A central artifact and metadata repository
How much would a metadata and artifact repository accelerate your process? Data scientists and machine learning engineers aren’t always diligent about documenting their data preparation, feature engineering, and model training steps. If you’ve worked with teams of data scientists, you’ve felt the frustration of trying to audit or reproduce a model that someone else trained months ago. Reconstructing the training dataset (which might have been incomplete), the features generated and used, the compute environment, the libraries, or the source code can be a nightmare. You never quite reproduce those first predictions, leaving you wondering why the model is different from the original.
Enter the model catalog, a central metadata and model artifact repository. In the Oracle Cloud Infrastructure (OCI) Data Science service, the model catalog lets data scientists share and control access to the models, and deploy them as HTTP endpoints through Data Science Model Deployment. We recently released a series of upgrades to the model catalog centered on documentation, reproducibility, and auditability: Three critical concepts of scientific experimentation and ML. A model catalog acts as a repository for artifacts and metadata, helping you generate, store, and share reproducible models. This release is the first major step in that direction.
Metadata and artifact repository: What’s new?
This update is the first major upgrade to the model catalog since OCI Data Science was first released in February 2020. Let’s dive into the six new features you can use to document and reproduce ML models.
Expanded provenance tracking
If you want to reproduce your model, you need to know the following information:
-
Where the model was trained
-
The environment (Version of Python abd libraries used)
-
The source code (Git repo, commit, and training script)
-
The Compute resources
-
The training data
-
The resulting features
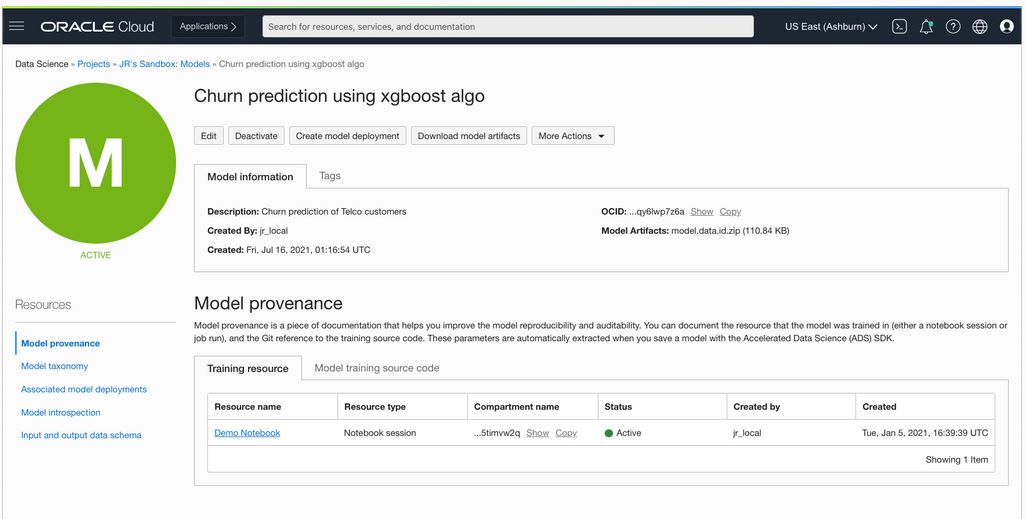
This information makes up the model provenance, and in this release, we modified the model catalog module of our Accelerated Data Science (ADS) Python software developer kit (SDK) to automatically track provenance. The information is stored in the catalog on your behalf when you save a model with ADS.
Documented model taxonomy

Model taxonomy is all about providing context. The model catalog lets you document the use case, the machine learning framework used to train the model, the version of that framework, and the algorithm used with its hyperparameters. You can input those values manually in the OCI Console or use ADS in the notebook that automatically extracts those values on your behalf. We provide value selection for both the use case and the machine learning framework to help standardize the results.
Model taxonomy helps you understand the context around which a model was trained and find the relevant models you need. All these steps are done without having to open a serialized model object, going through model training source code, or running a Docker container.
Documented input and output data schemas
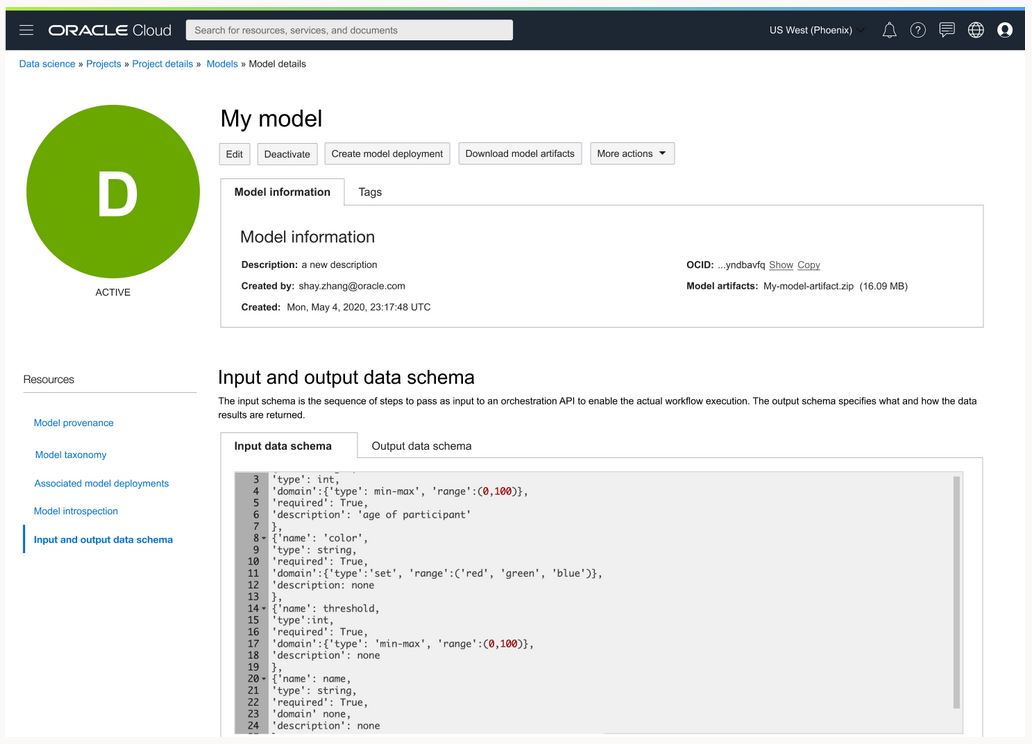
One of the most important pieces of information any model needs is a schema definition of the features that are required to make a successful model prediction. This information is critical when the model makes predictions in a production system.
The model catalog now allows you to store a JSON object representing both the input data schema for a model, the relevant features and their characteristics, and the response from the model. ADS can automatically generate those schema definitions, given a training dataset. The schema is stored in the model catalog, and you can directly inspect it in the OCI Console.
Model introspection: A 360-view of your model health
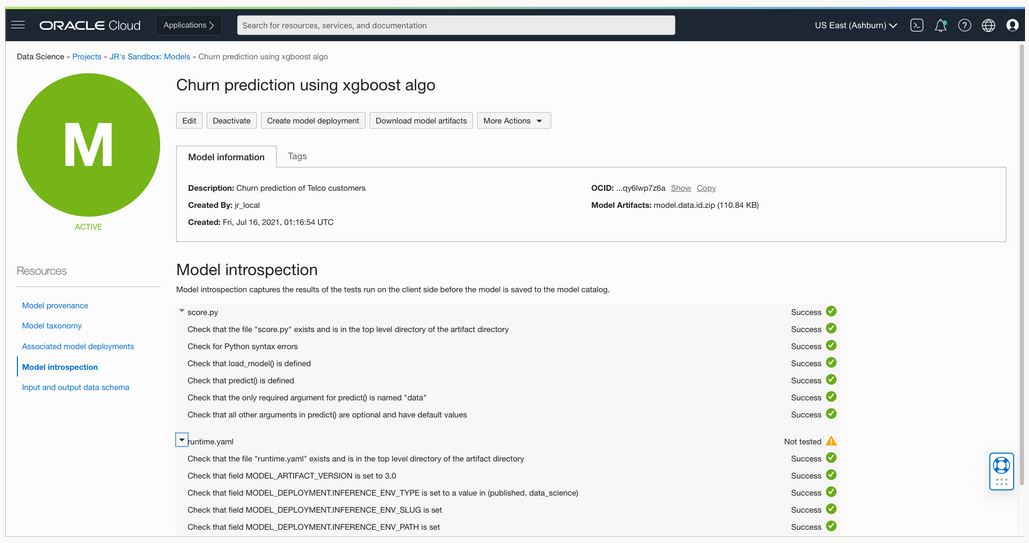
The new concept of introspection provides a comprehensive test suite for your model artifacts. These tests go beyond what data scientists call model evaluation. Instead, introspection is about assessing whether your artifact is healthy enough to be put into production.
This release of model catalog is the first that addresses this new introspection concept. A series of tests, ranging from syntax checks to the availability of the Conda environment for inference purposes, are available to run on each artifact before you save your model to the catalog. ADS runs all those tests on your behalf and stores the results in the catalog for documentation and audit purposes.
Expanded search capabilities in a metadata repository
Imagine an accessible and easy-to-use metadata repository. All the model metadata— provenance, taxonomy, your own custom metadata, or input and output schemas—are fully searchable with the OCI Search service. You can easily find that old bert model that you trained a few months ago and stored in some compartment or project that now escapes your memory. OCI Search returns all the models for which one or more pieces of metadata contain “bert.” This functionality is especially helpful for teams training and saving hundreds of models every month.
Your own model attributes
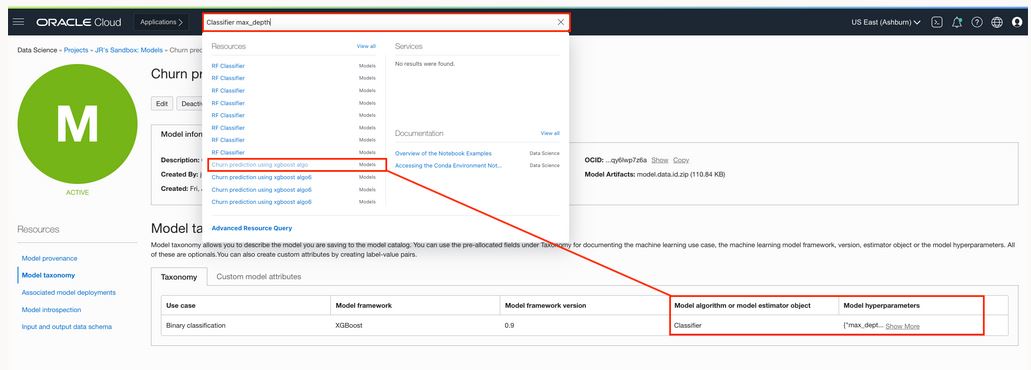
Although the model catalog has a new interface with a rich set of model metadata, sometimes you want to capture other bits of information that are missing from the auto-generated ADS metadata. You can always note other attributes (up to 50) to each model that you saved in the catalog. Like the other pieces of information we captured, all your custom attributes are also fully searchable in OCI Search.
ADS also generates extra attributes, depending on the model and the environment in which it was trained. ADS typically captures a reference to the training Conda environment, references to the training, and validation datasets, giving you the option to store key performance metrics, such as accuracy, F1, or precision.
Conclusion
Ready to learn more about the OCI Data Science service?
-
Star and clone our new GitHub repo! We’ve included notebook tutorials, code samples, and model artifact examples.
-
Visit our service documentation.
Try Oracle Cloud Free Tier today! A 30-day trial with US$300 in free credits gives you access to Oracle Cloud Infrastructure Data Science service and model catalog!
