Every customer, from the large government agency enterprise to the small defense contractor, strives to deliver a highly available solution that can quickly recover from a service disruption to a potential disaster. The technology to deliver this level of service quality has existed for decades, but because of limited funding requiring project prioritization, the cost to support fault tolerance is out of reach for many and was often so complex that outages occurred despite efforts to ensure critical workloads maintained near 100% availability.
The cloud has ushered in a new set of tools to make these availability goals cost effective to deliver, and Oracle Cloud Infrastructure (OCI) has further developed the redundancies in the cloud to make high availability simple and cost effective using something called fault domains.
Availability domains and fault domains
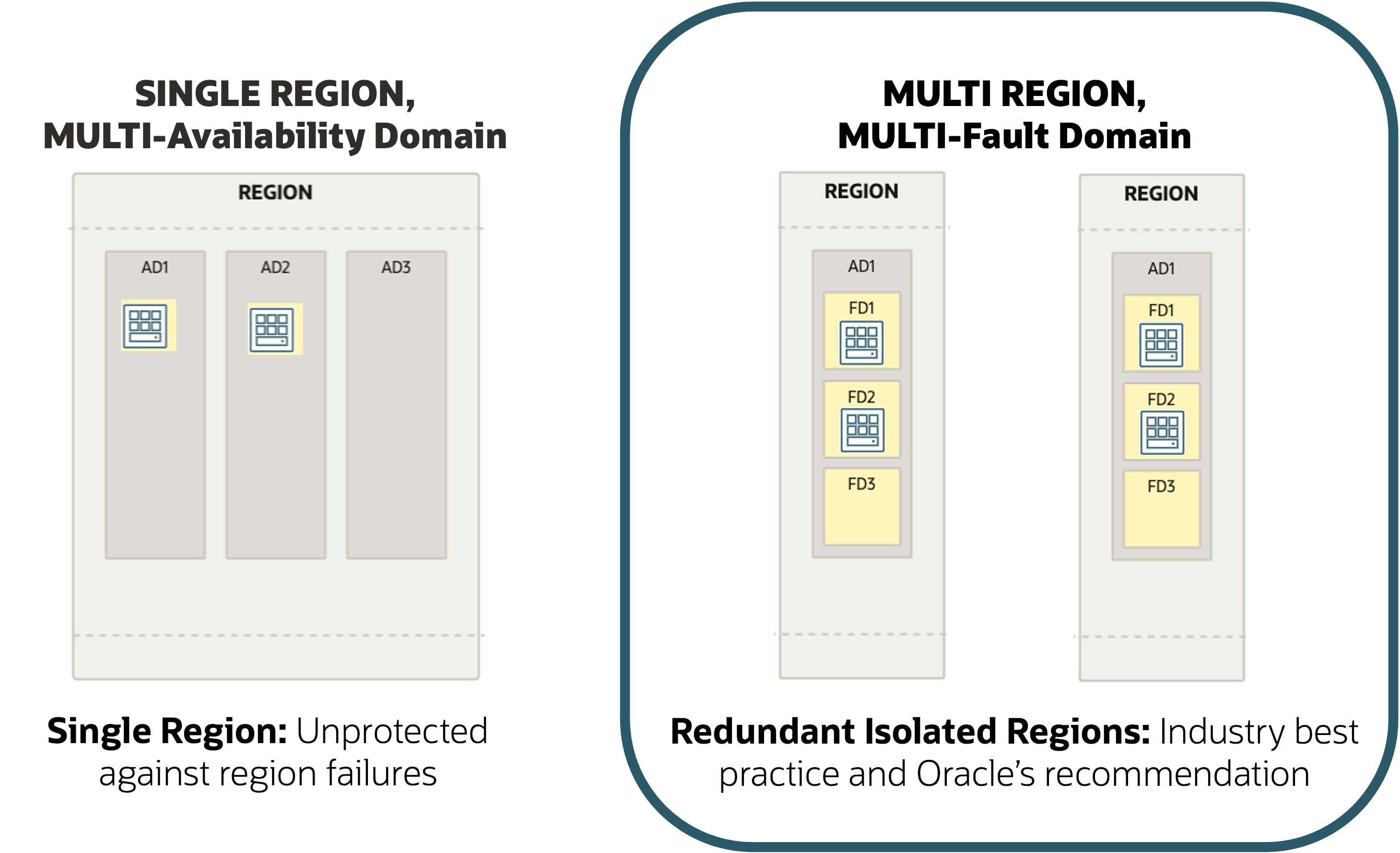
OCI has released dozens and dozens of new OCI regions in the last five years, including government regions, and all have one availability domain. OCI designed and deployed a technology called fault domains as an optimized architecture for delivering high availability. With fault domains, you gain little to no value in deploying across multiple availability domains in a region for most real-world use cases.
When we look at the history of on-premises architecture over the last few decades, except in very rare cases, no on-premises environments had an architectural analog to the availability domain. Some deployments had “campus clusters,” but they introduced high cost, high administrative burdens, and often unacceptable latency for services.
Our competition, and even some Oracle regions, offer multiple availability domains or zones, but multiple availability domains don’t provide the protection you think they do. Instead, they primarily provide scale for the cloud service provider (CSP). Availability domains are too close for disaster recovery and too far apart for high availability. For high availability the speed of light matters, the distance between availability domains can impact response times, especially for large scale three-tier architectures with high database transactions.
Oracle has designed the ideal architecture for high availability to the enterprise: Fault domains, which provide a great platform for availability through full redundancy of power, compute, networking, and storage. Fault domains remove the complexity of a three-availability domain architecture, removing the frailties this complexity imposes, frailties that have resulted in region outages for some CSPs. Fault domains provide a high-performance and low-latency foundation with virtually no administrative or cost burden, yet deliver on the requirements for deploying a highly available solution.
Fault domain concepts
Each OCI availability domain contains three fault domains. A fault domain is a set of resources and services that are independent of the other fault domains. They’re used internally by OCI to provide fault tolerance to the cloud control plane and distributed services. They’re also exposed to customers so they can build fault tolerance into their workloads. Fault domains protect the OCI resources against unexpected hardware failures, network failures, or software changes. So a hardware failure or compute hardware maintenance event that affects one fault domain doesn’t affect the OCI resources in other fault domains. Additionally, fault domains protect against a broad spectrum of power failures as each rack is fed from two separate circuits, and the power to these circuits is protected by an uninterruptible power supply (UPS). Finally, the facility has generator backup (with on-site fuel and contracts to deliver more as needed). You can target bare metal or virtual machine (VM) instances to a particular fault domain to provide anti-affinity, ensuring workloads are distributed across redundant infrastructure.
Ideal service protection setup for common outages
| Failure type |
Multiple regions |
Multiple fault domains |
Multiple data centers in a region |
| CSP network component |
Not required |
CSP-managed redundancy |
CSP-managed redundancy |
| CSP platform-as-a-service (PaaS) service |
Not required |
CSP-managed high availability |
CSP-managed high availability (Latency compromised) |
| CSP patches |
Not required |
CSP-managed high availability |
CSP-managed high availability (Latency compromised) |
| Customer-managed application |
Not required |
High availability optimized event |
Latency compromised high availability event |
| Regional disruption |
Disaster recovery event |
Use customer configured multi-region disaster recovery |
Use customer configured multi-region disaster recovery |
| Data center-wide outage |
Disaster recovery event |
Use customer configured multi-region disaster recovery |
Latency compromised high availability event |
Performance implications
|
|
Between regions |
Between availability domains |
Between fault domains |
| Time and latency between resources |
High |
Low |
Near zero |
Want to know more?
If you’re considering cloud computing to improve availability while also reducing costs and improving performance, Oracle Cloud infrastructure is a trusted and secure platform to host service and workloads that meets government accreditation requirements. Oracle has a dedicated team and established resources ready to support your migration and help you achieve your accreditation goals.
For more information, see the following resources:
