This blog provides details of OCI’s successful MLPerf Inference 5.0 results. The MLPerf Inference benchmark suite, developed by MLCommons, measures the performance of systems running AI/ML models with various deployment scenarios. The scenarios are carefully curated to cover the comprehensive use cases that enterprises require. MLPerf is the most recognized industry-standard benchmark for evaluating ML system performance. It also provides independent, apples to apples comparison against competitors.
OCI participated in benchmarks of these models shown below.
| Benchmark |
Task |
Area |
Scenarios |
| Llama 2 70B |
LLM – Q&A, Interactive, Summarization, Text Generation |
Language |
Offline 7and Server (FP32) |
| Mixtral 8x7B |
LLM – Text generation, Math and Code generation |
Language |
Offline and Server (FP16) |
| Mixtral 8x7B |
LLM – Text generation, Math and Code generation |
Language |
Offline and Server (FP16) |
| GPTJ-6B |
LLM Summarization |
Language |
Offline (FP32) and Server |
| RetinaNet |
Object Detection |
Vision |
Offline and Server (FP32) |
| Resnet-50 |
Image Classification |
Vision |
Offline and Server (FP32) |
OCI offers a range of GPU accelerators
Not all workloads are the same and the use of the premium GPU accelerators should be based on the specific use case. OCI offers a range of GPUs for workloads ranging from small-scale to mid-level and large-scale AI. OCI Supercluster offers the widest selection of bare metal GPU instances, ultrafast RDMA cluster networking and high performance storage options, including Managed Lustre. Learn more on our AI Infrastructure page and documentation.
Benchmark Results
OCI chose to run the MLPerf Inference 5.0 benchmark on BM.GPU.H200.8 shape that has the following specifications.
| OCI Compute with NVIDIA H200 GPUs | |
| Instance Name |
BM.GPU.H200.8 |
| Instance Type |
Bare Metal |
| Specifications |
8 x NVIDIA H200 141GB 2×56 cores Intel SPR 8480+ 3 TB DDR5 8×3.84TB NVMe 1×200 Gbps front-end network 8×400 Gbps RDMA |
| Cluster Network |
RoCEv2 RDMA at 3,200 Gbps |
Latency and throughput are closely intertwined, and considering them together is crucial. MLPerf uses latency-bounded throughput, which means that a system can deliver excellent throughput yet struggle when faced with latency constraints. Consider the difference between the offline and server scenarios. The server scenario imposes a significant latency constraint due to its nonuniform arrival rate (as stated in MLCommons.org). This highlights the importance of understanding how latency affects overall system performance.
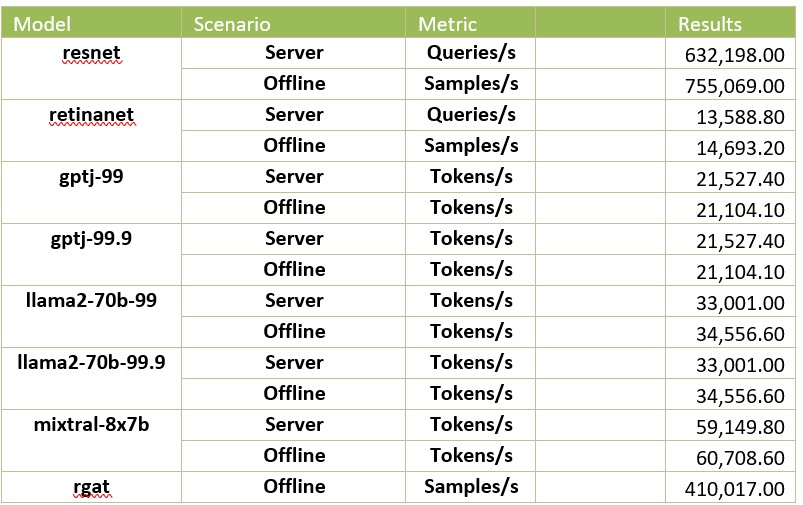
In the chart below, the performance of the Server scenario is normalized to that of the Offline scenario. These numbers indicate how well the latency bound system performs to one not restricted by latency. Note that RGAT does not have a run for Server scenario.
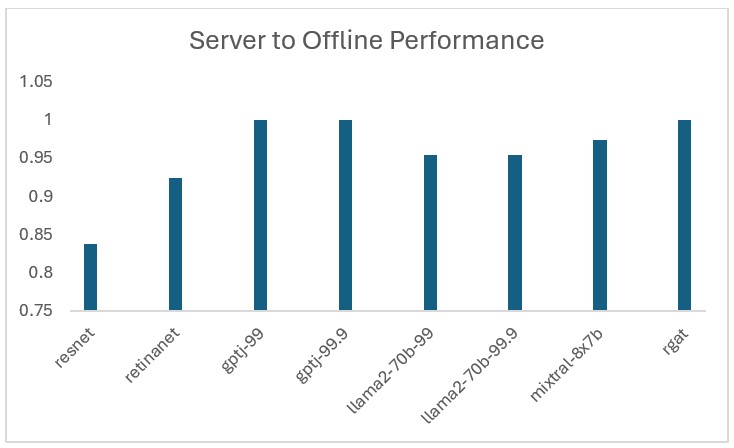
The comprehensive results are available on MLCommons. The results showcase OCI’s low latency network.
Summary
Oracle’s results in the MLPerf Inference Benchmark Suite 5.0 showcase the impressive performance and scalability of OCI’s AI infrastructure with industry-leading GPUs such as NVIDIA H200 . With consistent linear scaling across a range of demanding workloads—such as large language models, text-to-image generation, and biomedical image segmentation—OCI proves its capability to support the diverse generative AI needs of modern enterprises.
To learn more about OCI and AI infrastructure, please visit the links below:
OCI AI Infrastructure
https://www.oracle.com/ai-infrastructure/
Contact:



