We’re excited to announce the release of the Oracle Cloud Infrastructure (OCI) Data Flow plugin for OCI Code Editor. This new plugin offers a streamlined way to develop and deploy serverless OCI Data Flow Spark application on OCI.
OCI Oracle Data Flow is a powerful managed service that uses Apache Spark to process large datasets seamlessly without the need to deploy or manage any underlying infrastructure. The service also offers Spark Streaming, allowing developers to perform cloud-based extract, transform, load (ETL) operations on continuously produced streaming data. This integration gives you a faster application delivery process, so developers can concentrate their efforts on application development rather than dealing with infrastructure management.
OCI Code Editor provides a rich, in-Console editing environment that enables you to edit code and update service workflows and scripts without having to switch between the Console and your local development environment. You can now access the power of managed Apache Spark directly from OCI Code Editor, simplifying your cloud experience even further.
Benefits of the plugin
The OCI Data Flow plugin for OCI Code Editor offers a range of features and benefits that make it an essential tool for developers working with serverless Data Flow on OCI. The plugin includes the following benefits:
- Simplified Spark application development: The plugin provides a range of features that make it easy to develop and debug Spark applications, including syntax highlighting, intelligent completions, bracket matching, linting, code navigation, and so on.
- Easier and faster code testing: The OCI Data Flow plugin allows you to test your Data Flow Spark code locally before deploying it to OCI, which makes it easy to catch and fix errors early in the development process.
- Integrated debugging: The OCI Data Flow plugin allows you to debug your code right within OCI Code Editor with real-time error reporting and detailed stack traces.
- Git integration: The plugin enables you to clone any Git-based repository, track changes made to files, and commit, pull, and push code directly from within Code Editor, allowing you to contribute code and revert code changes with ease.
- Simplified deployment: When you’re ready to deploy your Data Flow application, you can deploy directly from the OCI Code Editor with no need to switch to another tool or interface.
- Get started faster: The OCI Data Flow plugin for OCI Code Editor comes with over a dozen OCI Data Flow samples as templates, allowing you to get going faster and work more efficiently, reducing the time and effort required to build and deploy serverless Spark applications on OCI.
Example of a Data Flow-based data pipeline
You want to build a data pipeline that loads data from a CSV file stored in an OCI Object Storage bucket, performs some transformations on the data using Spark, and then saves the results to an Oracle Autonomous Data Warehouse instance. Before this plugin, you took the following steps:
- Data ingestion: Use the Spark CSV data source to read the CSV file from Object Storage bucket and load it into a Spark Data Frame.
- Data processing and validation: When the data is ingested, use Spark SQL and API to perform various transformations and data cleansing operations, including data aggregation, filtering, and joining data if multiple data sources are involved.
- Data cataloging: Add metadata to processed data and store it using OCI Data Catalog. The metadata can include information such as data sources, schema, data lineage, and so on. Storing metadata helps your data discovery and lets data consumers easily find and use the data they’re looking for.
- Data warehouse: Finally, store the obtained processed and validated data in to the Autonomous Data Warehouse instance using Spark Oracle data source for long term storage and analytics to generate insights from the data.
Now you can stay within the Code Editor and utilize the Spark API to implement the entire data pipeline and run it on a Spark cluster powered by Data Flow. This approach simplifies the overall development, testing, and deployment process, resulting in a more efficient and streamlined workflow.
Building an OCI Data Flow-based data pipeline
Before you begin, ready the following prerequisites:
- Set up your tenancy.
- The Code Editor uses the same IAM policies as Cloud Shell. For more information, see Cloud Shell Required IAM Policy.
- The script /opt/dataflow/df_artifacts/apache_spark_df_plugin_setup.sh to set up Apache Spark locally on Cloud Shell to run the code locally.
- A user configuration file for authentication. You can use the Console to generate the config file. For instructions on creating the config file, see the developer guide.
- An Autonomous Data Warehouse instance. To create an instancein Autonomous Data Warehouse, refer to the documentation.
- A Data Catalog instance. To create an instance in Data Catalog, refer to the documentation.
Now you’re ready to set up your data pipeline with the following steps.
- Log in to Oracle Cloud Console and navigate to Data Flow. Click the Launch code editor button.
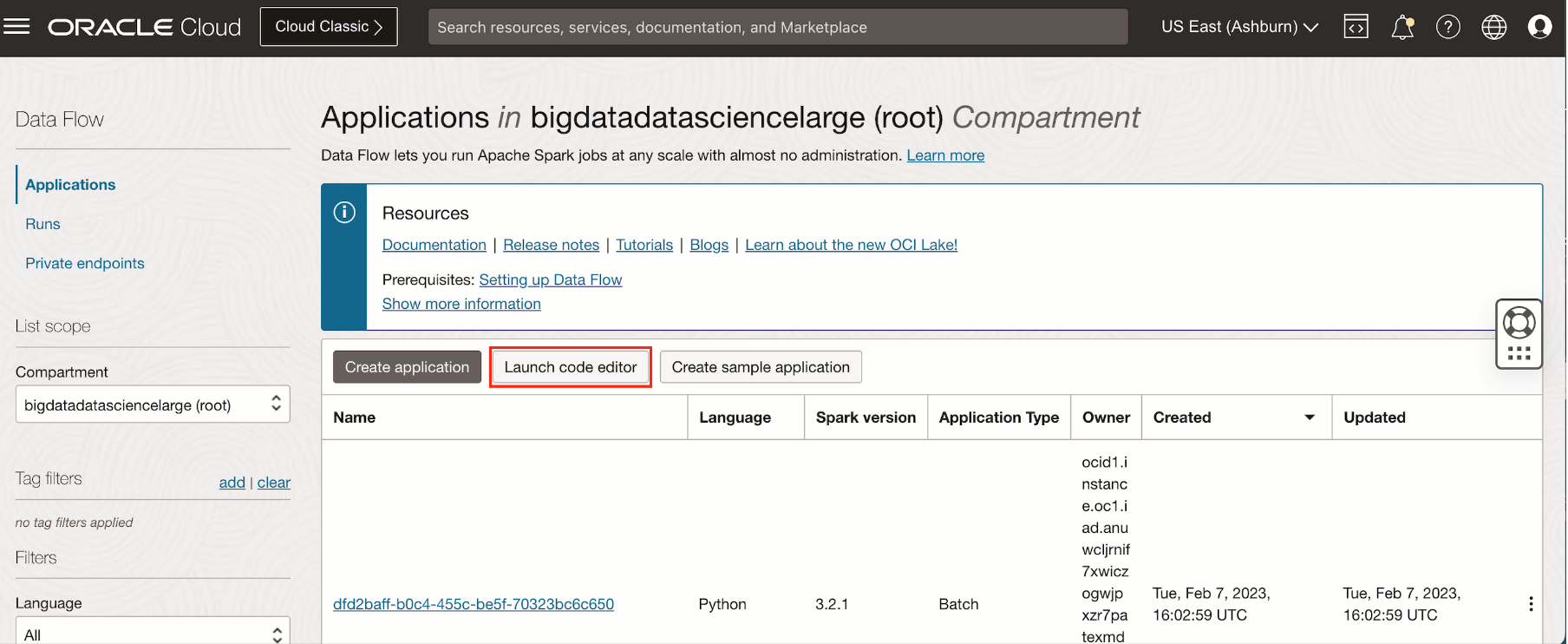
-
When the code editor window launches, click the Oracle logo button, which shows the Data Flow plugin. To see all the compartments and the associated Data Flow Code Editor projects for your tenancy, expand the plugin.
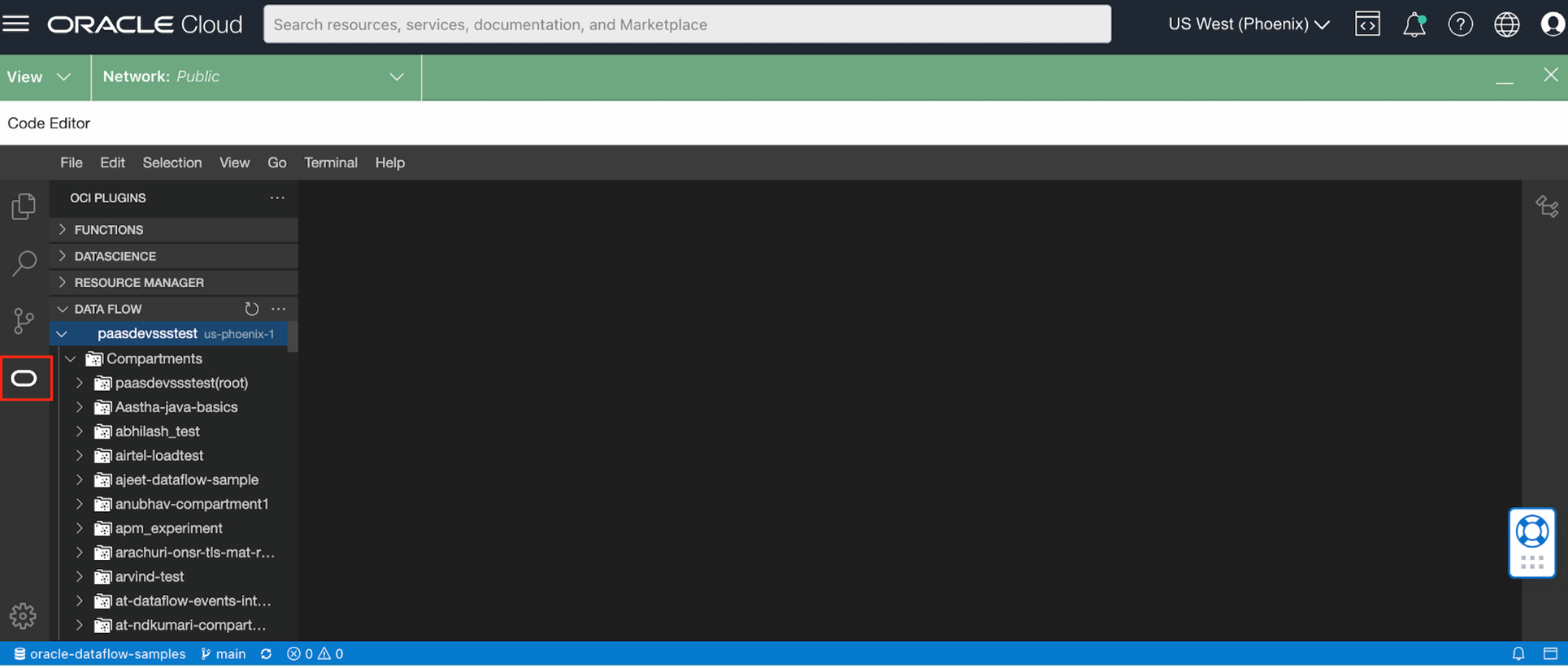
- To create a project in the plugin, you have three options. For this example, we select “Create from the template,” which sources the code from the OCI sample GitHub repo.

-
We’re using a Python example called “csv_metastore_adw,” which has the sample code to read from CSV file, transforms the data, writes the metadata to Data Catalog, and saves the transformed data to an Autonomous Data Warehouse instance. After creating the project, name the project.

-
After you select the example, the plugin pulls the code into the editor. Next, inspect the code and make changes to capture the setup parameters per for enviornment. The changes to the input parameters, such as path for the CSV file and Autonomous Data Warehouse details, are described in the README file .
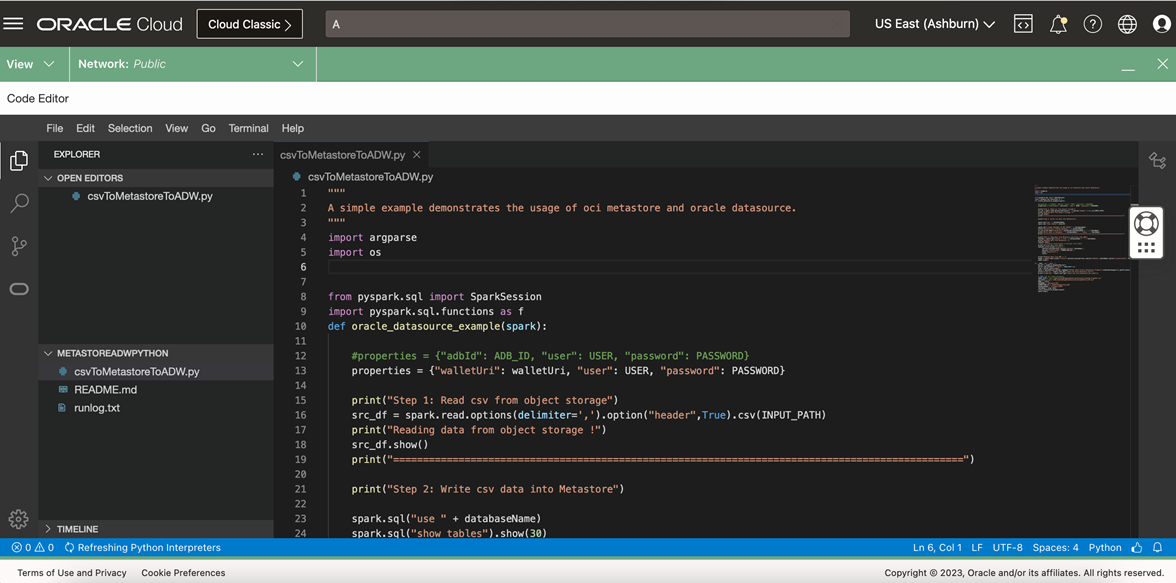
-
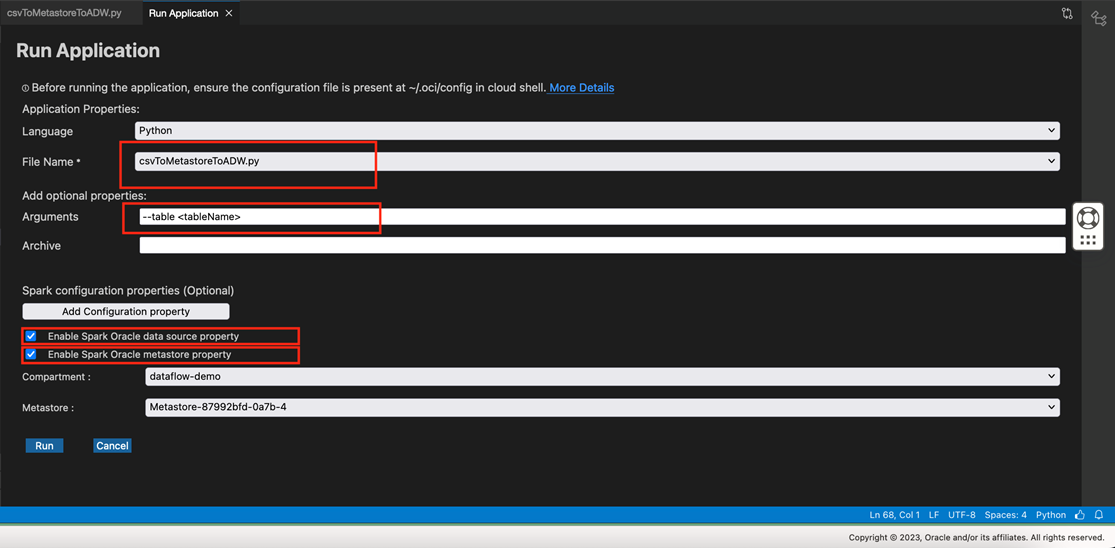
Run the code locally to verify that it works as expected. Clicking Run locally opens the screen “Run Application” to capture the application input parameters.
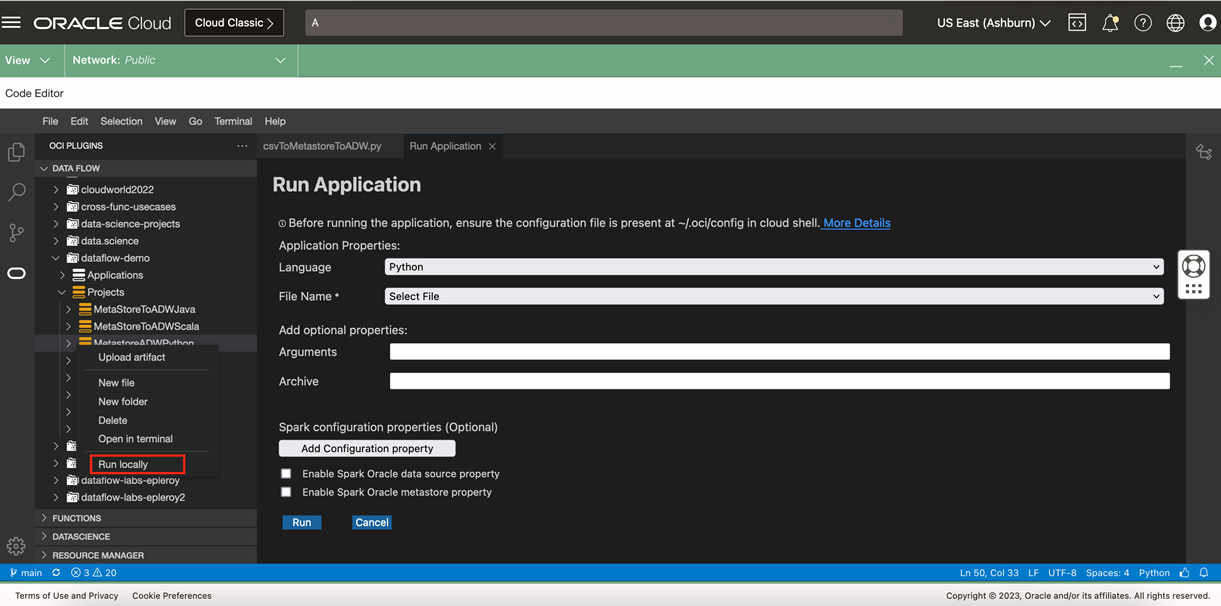
-
Enter the following input parameters to run the application locally:
-
Language: Python
-
File Name: csv_metastore_adw
-
Argument: –table <tableName>. Supply the Data Catalog metastore table.
-
Enable both the Spark Oracle data source property and Enable Spark Oracle metastore property. Enabling them requires you to give the compartment housing the metastore instance
-
-
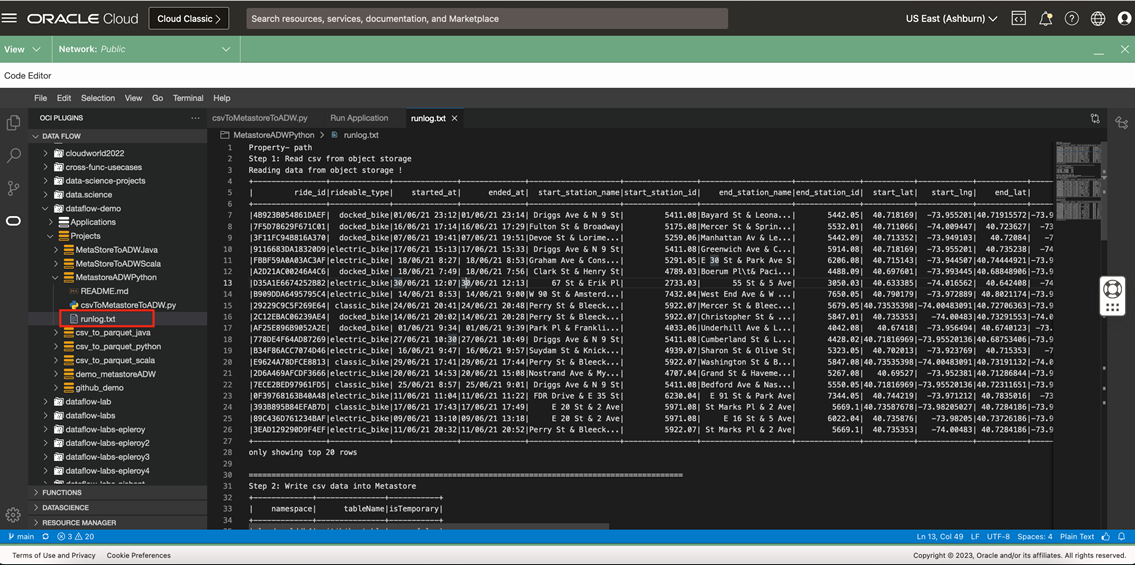
Click Run. It submits the Spark job locally and shows the output in the log file, runlog.txt. If an error occurs, it’s logged to the terminal and the log file.
-
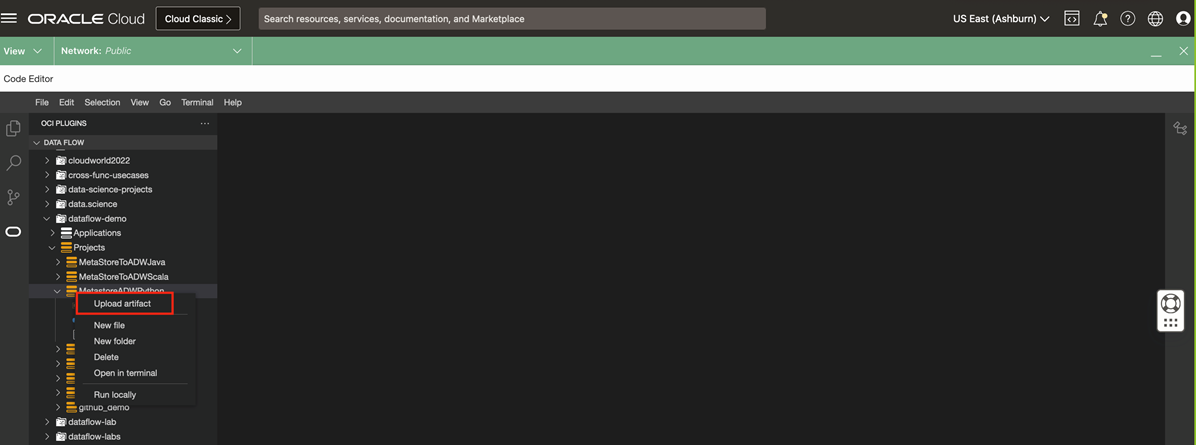
After verifying the output, deploy the code to the Object Storage bucket so that Data Flow can use it by clicking Upload artifact in the menu. While uploading, supply the path for the bucket. Select the language (Python), select the Python file, and enter the Object Storage file URL path (oci://<bucket_name>@<tenancyname>/folder_name>). Then press Enter.
You can now start using the application in the Data Flow service.
Conclusion
Revolutionize your Data Flow with Apache Spark app development and deployment with the OCI Data Flow plugin for OCI Code Editor. Say goodbye to the hassle of managing infrastructure and hello to a streamlined workflow that lets you create, test, and deploy your data pipeline, all in one powerful integrated environment. Unleash the power of the Oracle Cloud Infrastructure Data Flow plugin today, and see today for yourself how easy it can be.
For more information, see the following resources:
Data Flow (Documentation)
Code Editor (Documentation)
