We’re excited to announce a new release of Oracle Cloud Infrastructure (OCI) Data Integration. This release expands connectivity options for Oracle Fusion Cloud applications and more databases. It also adds support for hierarchical data, expression functions and user-defined functions, as well as orchestration for OCI Data Flow and REST tasks.
Cloud native, serverless integration
OCI Data Integration is a fully managed, serverless, extract, transform, and load (ETL) service in Oracle Cloud. Organizations building data lakehouses for analytics and data science can quickly deliver insights by simplifying, automating, and accelerating the consolidation of data from multiple data silos. Data Integration provides a graphical, no-code design interface with interactive data preparation and profiling. It also helps data engineers to design data pipelines using patterns and rules to handle schema evolution. It supports both Spark ETL and ELT push-down execution to the database. If you’re not familiar with this new service, check out this blog to find out more: What is Oracle Cloud Infrastructure Data Integration?
Data Integration is available in all OCI commercial regions.
Expanded connectivity with more options for Fusion Cloud applications
We continue to expand connectivity to more variety of data sources. OCI Data Integration users can now extract data from Fusion Cloud applications using the Business Intelligence (BI) Publisher connector. Azure Synapse and IBM DB2 are also newly supported data sources. See the complete list of supported data assets.
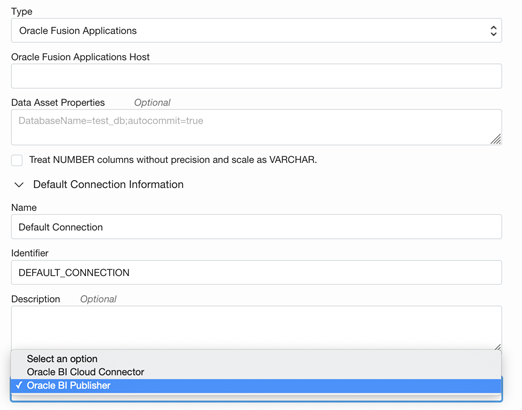
Figure 1: Fusion application connection Oracle BI Publisher type
Hierarchical data support
With this release OCI Data Integration supports processing of files with nested hierarchy and new data types: Composite, array, and map. You can access array types using an index like json_expression.cities[0].city_name. The following functions in the expression operator are now available to enable users to parse and process hierarchical data:
-
SCHEMA_OF_JSON(String): Parses a JSON string and infers its schema
-
FROM_JSON(string column, String): Parses a column containing a JSON string into a MapType with StringType as keys type, StructType, or ArrayType with the specified schema
-
TO_JSON(column): Converts a column containing a StructType, ArrayType, or MapType into a JSON string
-
TO_MAP(column…): Creates a column of map type. The input columns must be grouped as key-value pairs
-
TO_STRUCT(column…): Creates a struct column. The input columns must be grouped as key-value pairs
-
TO_ARRAY(column…): Creates an array column. The input columns must all have the same data type
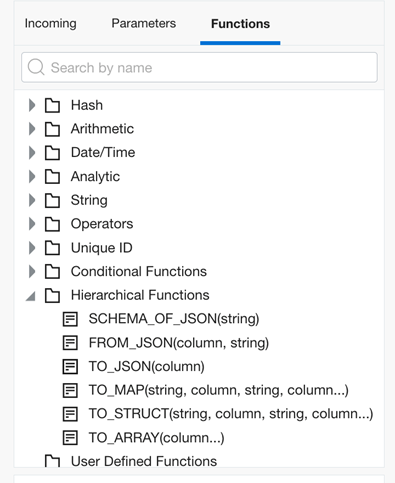
Figure 2: Expression operator
You can now process hierarchy data types in an OCI Functions operator. In a data flow, you can now map complex data types like array, composite, or map types as input and output attributes in an OCI Function operator.
More functions
Using user-defined functions, you can now define custom functions by using inbuilt OCI Data Integration-native functions and use them across data flows and pipelines. Now you can encapsulate the complex expressions and can provide the custom name to these complex expressions.
We added the following transformation functions in this release:
-
LPAD: Add padding characters to the left of a string
-
RPAD: Add padding characters to the right of a string
-
ListAGG: Aggregate function that transforms data from multiple rows into a single list of values separated by a specified delimiter
Schedule and orchestrate more variety of tasks
You can now start using REST tasks and orchestrate as part of OCI Data Integration pipelines. The REST task enables you to make synchronous calls to a REST endpoint. This functionality opens a wide array of possibilities for you to perform any operations that can be encapsulated as a REST endpoint.
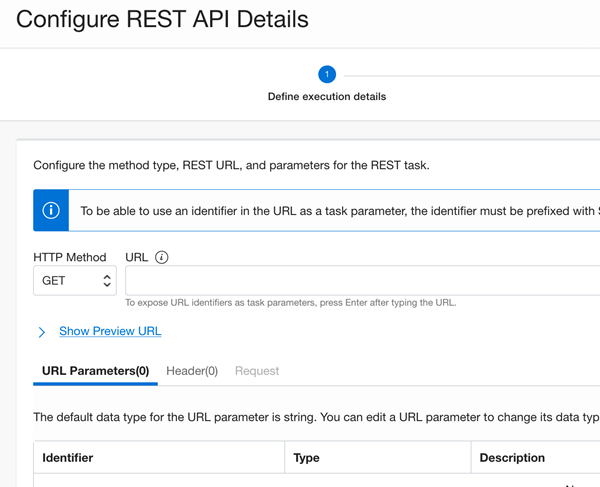
Figure 3: REST task
Now, you can orchestrate OCI Data Flow tasks in Data Integration pipeline. You can use the OCI Data Flow task to call an existing OCI Data Flow application in OCI Data Integration service, enabling users to call Spark applications created in OCI Data Flow seamlessly from OCI Data Integration.
You can also now schedule the tasks weekly, specific day of the week or month, and provide CRON expressions.
Want to know more?
Organizations are embarking on their next-generation analytics journey with data lakehouses and advanced analytics with artificial intelligence and machine learning in the cloud. For this journey to succeed, they need to ingest, prepare, transform, and load their data with Oracle Cloud Infrastructure Data Integration quickly and easily. Try it out today!
For more information, review the Oracle Cloud Infrastructure Data Integration documentation, associated tutorials, and the Oracle Cloud Infrastructure Data Integration blogs.
