In my previous post, Accelerate distributed deep learning with OCI, I explained how OCI’s RDMA networking can speed up model training jobs when scaling beyond a single GPU node. To demonstrate the performance boost with a concrete example, we set up a Compute cluster of four Bare Metal GPU nodes (BM.GPU.GM4.8) and ran the MLPerf training benchmark. Because each BM.GPU.GM4.8 is equipped with 8 NVIDIA A100 80G GPU, the Compute cluster can scale up to 32 GPUs to accelerate machine learning (ML) training time.
MLPerf 101
MLPerf is a benchmark suite developed by MLComons, an open engineering consortium, to evaluate training and inference performance of different systems. The training benchmark measures how fast system can train models to a target level of accuracy, while the inference benchmark measures how fast system can process new input and calculate a prediction using a trained model. MLPerf is becoming the industry metrics to measure and compare different hardware infrastructure and software frameworks for ML.
OCI Compute cluster with NVIDIA A100 tensor core scales linearly
In this benchmark exercise, we ran the following models to capture performance that cover both image classification and natural language processing (NLP) use cases:
-
MLPerf v1.1 ResNet50 (image classification)
-
MLPerf v2.1 ResNet50 (image classification)
-
MLPerf v2.1 BERT (NLP)
In the following graphic, 1 node = 8 GPUs, 2 node = 16 GPUs, and 4 node = 32 GPUs.
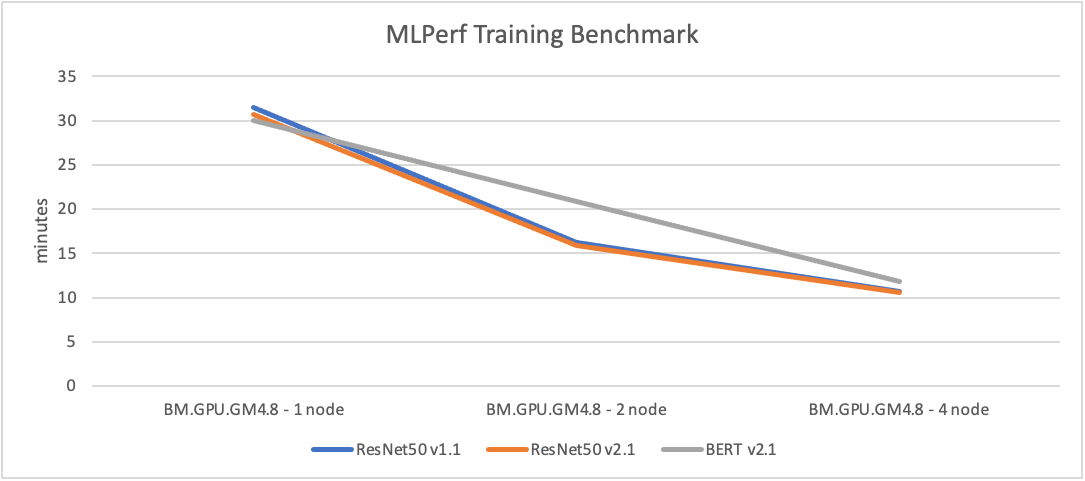
The results illustrate a near-linear gain across all three models with different ML frameworks as the number of compute node increases. When training ML models on multiple nodes, the performance gain is often sublinear, meaning that adding more nodes doesn’t lead to a proportionally greater improvement in performance. One of the key factors is communication overhead. With OCI’s high-throughput, ultra-low-latency RDMA networking, the cluster was able to distribute training jobs efficiently by optimizing cross-node GPU-to-GPU communication. For example, the time required to train a ResNet50 v1.1 model reduces from 31.5 minutes with 8 GPUs, to 10.67 mins with 32 GPUs.
Faster training times mean that you can train ML models more quickly, allowing data scientists and engineers to iterate more rapidly and experiment with different model architectures, hyperparameters, and datasets. This speed can lead to more accurate models, and higher development agility to respond quickly to changing business environment.
You can find a complete report with more details on this unofficial Oracle Cloud Infrastructure (OCI) benchmark website.
Conclusion
In the next post of this series, I go into technical details of setting up MLPerf multinode training with RDMA supported.
OCI offers support from cloud engineers for training large language models and deploying AI at-scale. To learn more about Oracle Cloud Infrastructure’s capabilities, contact us or see the following resources:

