Oracle Cloud Infrastructure (OCI) Data Flow is a fully managed big data service that lets you run Apache Spark applications at any scale with almost no administration. Spark has become the leading big data processing framework and OCI Data Flow is the easiest way to run Spark in Oracle Cloud because there’s nothing for developers to install or manage.
Today, different people who use Data Flow often need to collaborate based on their roles and the data they process, produce, or consume. The data engineer can be on point to prepare the data: A combination of extract, transform, clean, and load operations. The data scientist can then feed that cleaned dataset into machine learning models to generate predictions, classifications, or recommendations. The data analyst can consume the same dataset and models to generate new insights and business intelligence reports.
Multiple team members within the same group can be responsible for different parts of the extract, transform, and load (ETL), data preparation, processing, or reporting.
Without a common metadata repository for contents in object storage, each user duplicates data definitions, data formats, extractors, and loaders every time they write a Data Flow application or query. No single source of truth for the metadata and data exists. Fortunately, OCI Data Flow users now have that shared persistent metadata repository, thanks to the Data Catalog Metastore.
Introducing Data Catalog Metastore
As an OCI Data Flow user, you can now use the Data Catalog Metastore to securely store and retrieve schema definitions for objects in unstructured and semistructured data assets in object storage. OCI Data Catalog Metastore provides a Hive compatible metastore as a persistent external metadata repository shared across multiple OCI services. Sharing metadata by different applications or users improves collaboration, reusability, and consistency and accelerates the extraction of insights from the data lake.
The Data Catalog Metastore securely stores metadata about tables schema, location, table statistics for query optimization and partition metadata for the Apache Spark driver in OCI Data Flow to track the progress of various data sets distributed over the cluster. When used with OCI Data Flow, Metastore is no longer embedded or limited within the scope of a single Data Flow application. So OCI Data Flow users can now define the shared schema once and consume or update data based on that shared schema multiple times across multiple Data Flow applications, users, or user personas.
Using Data Catalog Metastore in OCI Data Flow
To use the Data Catalog Metastore with OCI Data Flow, complete the following steps:
1. Set up the Hive Metastore-related policies
Ensure that your tenancy admin has set up the policies needed by Data Catalog Metastore.
ALLOW any-user to READ object-family in tenancy where any {
all {target.bucket.name='bucket-name-of-managed-table-location', request.principal.type='datacatalogmetastore'},
all {target.bucket.name='bucket-name-of-external-table-location>',
request.principal.type='datacatalogmetastore'}
}
ALLOW any-user to MANAGE object-family in tenancy where all
{target.bucket.name='bucket-name-of-managed-table-location',
request.principal.type='datacatalogmetastore'}
Policy for Data Flow admins: Let Data Flow admins manage Data Catalog Metastore
Allow group dataflow-admins to manage data-catalog-metastores in tenancyPolicy for Data Flow users: Let Data Flow users use Data Catalog Metastore for applications and runs
Allow group dataflow-users to {CATALOG_METASTORE_EXECUTE,
CATALOG_METASTORE_INSPECT, CATALOG_METASTORE_READ} in compartment
<compartment-name>2. Create a Data Catalog metastore
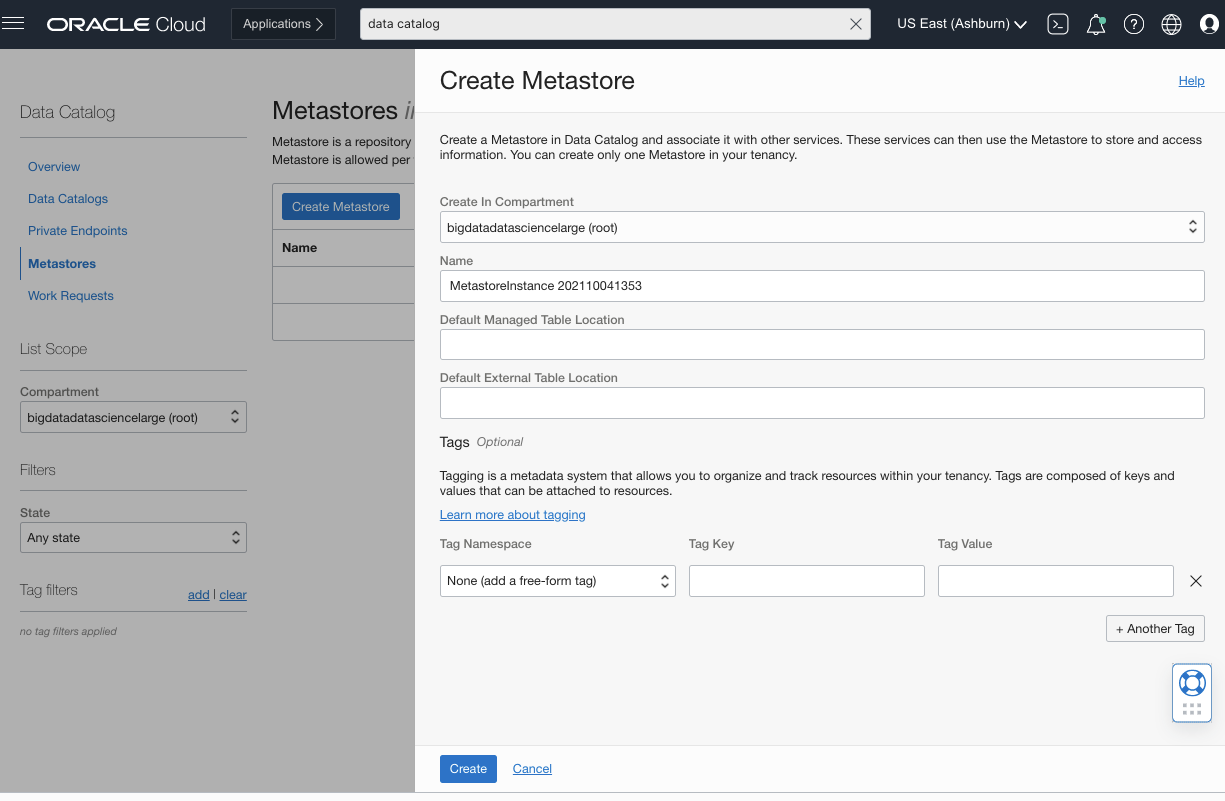
In the Oracle Cloud Console, navigate to Data Catalog, Metastores, select Create Metastore, and fill in the relevant details. You can only create one metastore per tenancy. This constraint ensures a single source of truth for metadata. While creating a Data Catalog metastore, you can indicate both the managed table location and the external table location in OCI Object Storage. As a best practice, make these two locations different. The metastore assumes that it owns the data for the managed tables. For external tables, the Hive-compatible metastore doesn’t manage or own the underlying data. So, operations like ‘DROP TABLE‘ deletes both data and metadata for managed tables while it only deletes the metadata for external tables.
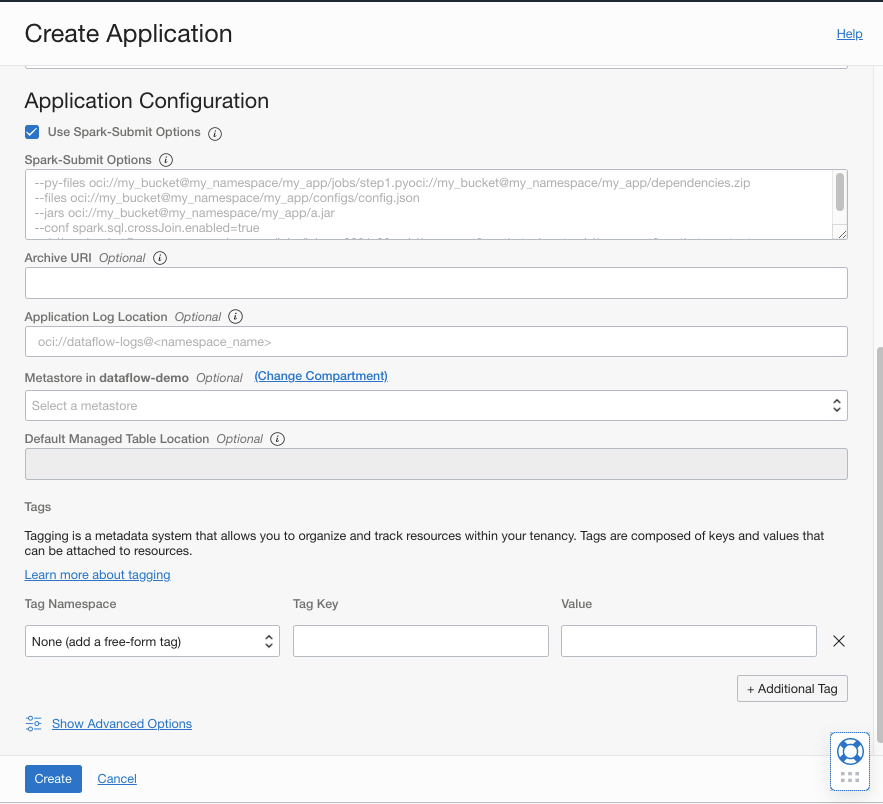
3. Create a Data Flow application using the metastore
In this step, you create the Data Flow application where the metastore you created is attached. If you miss this step, the OCI Data Flow application uses the embedded metastore by default, instead of the shared persistent metastore. To collaborate based on the same metastore, you can create separate databases or tables based on the user persona or role.
4. Enable the metastore while creating the Spark session
Enable the Data Catalog Metastore from your application code when creating a Spark session by calling enableHiveSupport().
See for yourself
After the initial setup, you can follow an upcoming hands-on lab to explore how different OCI Data Flow users can share a Data Catalog metastore. That Live Lab uses the Yelp review and business dataset to demonstrate how data engineers and data scientists can collaborate based on a shared metastore. In this Live Lab, the data engineer first loads the raw JSON-based Yelp review and Yelp business datasets from the Object Storage bucket. The data engineer cleanses and transforms it into the Parquet format for efficiency and finally loads the parquet data into a managed table of an OCI Data Catalog Metastore. A data scientist then queries the same data and metadata to build a sentiment-analysis-machine learning model to predict the sentiment of text reviews.
Data Catalog Metastore is available now in all commercial regions. Using Data Catalog Metastore with Data Flow incurs no charges. You only pay for the resources that your Spark jobs use while Spark applications are running. To learn more about OCI Data Catalog Metastore, see the documentation.
To get started today, sign up for the Oracle Cloud Free Trial or sign in to your account to try OCI Data Flow. Try Data Flow’s 15-minute no-installation-required tutorial to see just how easy Spark processing can be with Oracle Cloud Infrastructure.
