Introduction: Why One-Dimensional Search is Not Adequate anymore.
Traditional enterprise search engines used to rely primarily on keyword or filters. These traditional keyword-based search engines broadly work as a 2-step process: indexing & retrieval.
- Indexing: Index documents and data, mapping individual terms to the documents in which they appear.
- Retrieval: When a user query is submitted, the engine 1st tokenizes the text, then removes any stop words and applies normalization, and finally matching the results against the index. The results are then ranked depending on multiple criteria, including how frequently the searched term appear.
This system excels for use cases involving exact-match retrieval such as finding documents containing specific words, phrases, terms, or numbers. However, it fails to deliver in cases where semantic interpretation or contexts matter. E.g. the traditional search mechanism doesn’t work as optimally as expected in cases where the users do not know the exact terms in the data or where Relevant items use different vocabulary or where the inter-relationship between the data matters.
As a result, Hybrid search, which combines keyword, graph, and vector capabilities in a single architecture, is slowly becoming popular.
What Is Hybrid Search Architecture?
Hybrid search architecture is an architectural approach which attempts to combine multiple search modes, such as keyword, vector, and graph search, to answer complex user queries rather than allowing just one of the methods to handle all queries.
A hybrid approach attempts to bring the best of the three modes together:
– Keyword search for precision and control (filters, exact terms).
– Vector search for semantic context (similarity).
– Graph search for relationship evaluation (paths, neighborhoods and influence)
What the Hybrid Architecture is not:
- It doesn’t run three independent searches against three different search infrastructure
- It doesn’t show three separate result sets
- It is not a replacement for keyword, vector, or graph search, but a deliberate combination of all three to solve more complex questions.
Instead, what the architecture attempts to do is:
- It allows users to run one single query in simple natural English language
- It decomposes complex user queries into distinct intents (filters, similarity, relationships) and applies the appropriate search technique to each.
- It orchestrates one single search plan
- It produces one ranked, explainable result
Why OCI Is Well Suited for Hybrid Search
OCI approaches hybrid search differently from most platforms.
Instead of spreading search capabilities across multiple services, OCI enables AI Vector Search, Text, and Graph together as native features, enabling OCI a natural platform for building the search infrastructure foundation
- Keyword search (Text)
- Vector search (AI Vector Search)
- Graph search (Property Graph)
Oracle AI Vector Search introduces semantic search by representing text, images, and other data as high‑dimensional vectors and using similarity metrics (such as cosine) to find conceptually similar content. At the same time, Oracle Text continues to provide rich, indexed keyword search on content, while Spatial and Graph features support property graphs and spatial queries for relationship‑heavy data.
As a result, OCI enables a hybrid search infrastructure to operate within the same database-centric environment, allowing:
- One security model
- One governance framework
- One transactional boundary
This capability does not remove the need for application-level orchestration. However, it simplifies the architecture considerably.
End-to-End Hybrid Search Architecture on OCI
The below diagram articulates the key components of a hybrid search architecture.
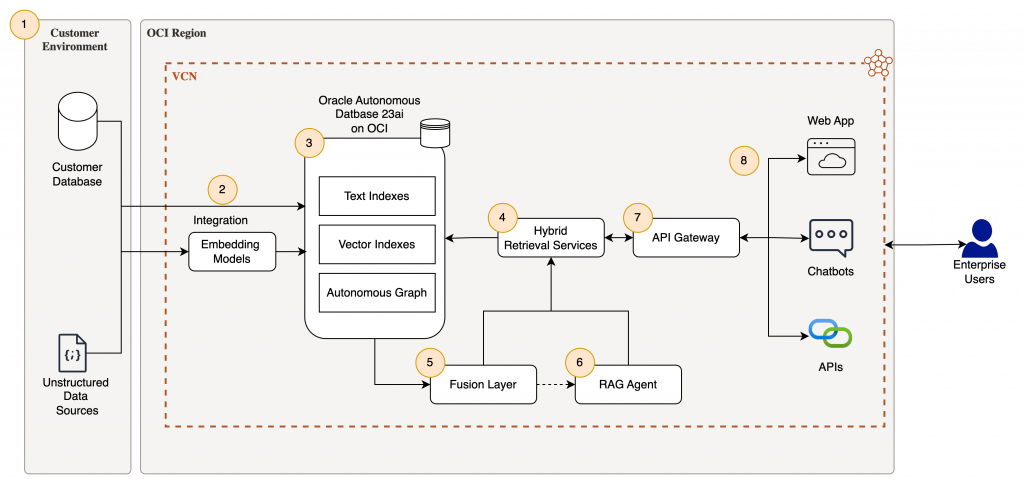
Logical Components
| S# | Component Name | Additional Details |
| 1 | Enterprise Data Sources | Enterprise Application DataEnterprise Documents (best practices, policies, knowledge repository)Graph Data ( Entities, relationships) |
| 2 | Integration & Processing | Text ExtractionEmbedding generationRelationship Modelling |
| 3 | Unified Data Store | Oracle Text indexes for keyword searchVECTOR datatype & indexes for semantic searchProperty Graphs (Relationships) |
| 4 | Hybrid Retrieval Services | REST APIs or microservicesSearch PlansOrdered Executions |
5 | Fusion Layer | Result merging Similarity scores & Relationship proximity Business defined weightages |
6 | RAG Agent | Grounded responseConversational Contexts Citations |
| 7 | API Gateway | Secure endpoints Authentication Request Transformations |
| 8 | WebApp/Chatbots/APIs | User-facing interfaces consuming API Gateway responses |
Typical search workflow:
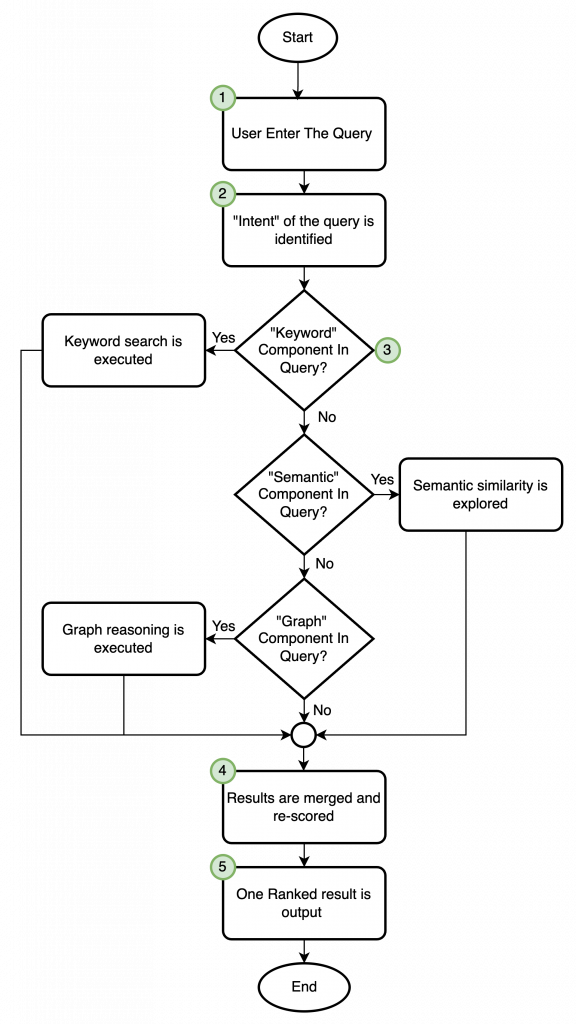
| S# | Details |
| 1 | User enters a query using the interface that it has at its disposal e.g. Web App or Chat Bot |
| 2 | The system (retrieval services) identifies the intent of the query and categorizes into: Keyword Search (Filter)Decide whether semantic similarity search needs to be explored (Vector Search) Decide whether graph reasoning is required (Relationship) |
3 | Each of the 3 path outputs a ranked list of candidatees Keyword: Narrows the effective dataset and reduce the search scope Vector: Compares embeddings and ranks output by semantic similarity Graph: Traverses relationship and identifies paths to the searched criteria |
| 4 | In the Fusion Layer: Results from the above 3 paths are merged and re-scoredHybrid search is more than just concatenating lists. Rather, hybrid search process should use ranking strategies such as Reciprocal Rank Fusion (RRF) or other composite scoring functions to combine various outputs |
5 | Output: One ranked result set is sent for output.For search‑only experiences, the system should typically return the result set to the client.For chat-based applications, agents or services are usually called to generate a response based on these results. |
How the System Knows Which Search to Use
The system does not guess.
The system relies on:
- Pre-defined query templates
- Pre-defined intent rules
- Usage of AI for classification
The user submits one query.
The application selects the appropriate hybrid search plan and outputs one result.
Best Practices & Considerations
There are several considerations, in terms of use cases, governance, performance and cost, that should be kept in mind while designing a hybrid search architecture:
- +ve and -ve Use Cases
Use Hybrid Search in cases where:
- Simple keyword lookup is not enough and meaning/relationship between data set matters too
- Latency is important but ultra-low latency is not essential
Avoid Hybrid Search in cases where:
- Simple keyword lookup does this job
- Dataset is comparatively small
- Ultra-low latency is critical
- Optimize for specific use cases
- Compliance and legal queries may require strict filters.
- Exploratory analytics might benefit from higher emphasis on vector search.
- “Impact analysis” kind of searches might benefit from higher emphasis on Graph search.
Hence, the system should begin with simple weightage techniques and the weightage can be adjusted during optimization.
- Application of Keyword filtering early in the workflow might provide better cost considerations.
- Graph traversal depths and vector search can be bound and limited to control the relevant datasets.
- Search relevance and model drift should be monitored and tuned as applicable
Conclusion
Hybrid search, combining keyword, graph, and vector search, creates a powerful and flexible foundation for intelligent enterprise applications. If used correctly, It would definitely help organizations deliver better usage of enterprise data artifacts, better query responses and stronger usage of AI tools to solve enterprise challenges.
OCI enables this architecture in a way that is database-centric and easily governed, making hybrid search a practical value provider.
