
Large language models (LLMs) are revolutionizing industries across the globe. From transforming customer service workflows to advancing healthcare diagnostics and driving content creation, LLMs are unlocking new dimensions of automation, personalization, and decision-making. As businesses race to adopt generative AI (GenAI) to stay competitive, the demand for scalable, high-performance infrastructure is growing, especially when deploying LLMs in real-world applications.
While hyperscalers and other large cloud providers offer managed services for LLM inferencing, scaling these models can come at a significant cost. Large, state-of-the-art models, such as GPT-4 with 1.8 trillion parameters, though offering cutting-edge capabilities and broader general knowledge, often require intense computational power and specialized GPUs, making them expensive to operate at scale. In contrast, smaller models like Llama 3, with parameter ranges from 1B to 8B, strike a balance between performance and resource efficiency, offering robust capabilities without the prohibitive hardware costs. Furthermore, for enterprise use cases, such as real-time inference or situations where low latency and cost-effectiveness are priorities, running these smaller models on CPUs, especially with optimized frameworks like llama.cpp, can be highly effective.
In this post, we explore an efficient, cost-effective approach to hosting and scaling LLMs, specifically Meta’s Llama 3 models, on OCI Kubernetes Engine (OKE). We also examine the critical infrastructure components needed to deploy production-grade GenAI solutions, such as API rate limiting, autoscaling, performance testing, and observability through robust monitoring tools.
Solution architecture
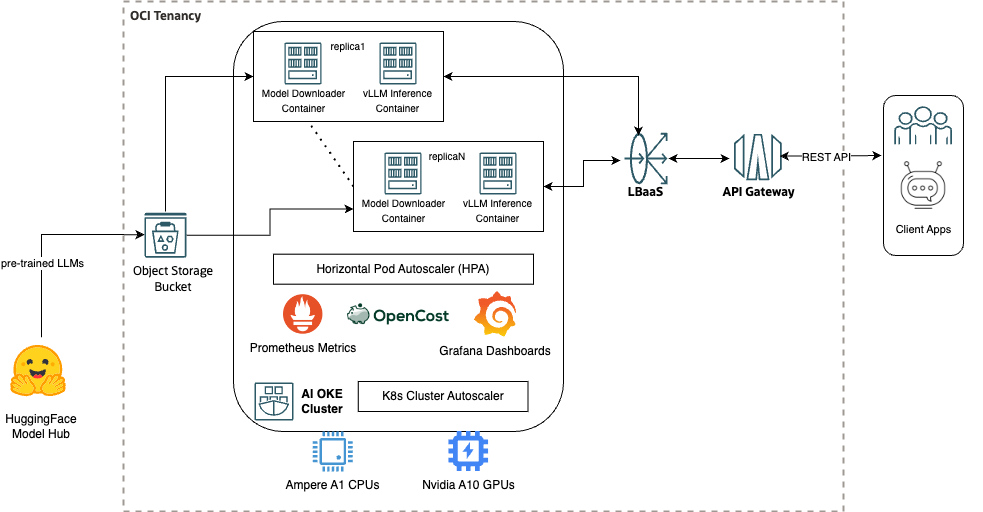
This architecture provides the following distinct LLM inferencing options for your deployment:
- vLLM inferencing on NVIDIA A10 GPU node pools: This option utilizes vLLM containers running Llama 3.1 8B and Llama 3.2 1B models on NVIDIA A10 GPUs.
- Ampere-optimized llama.cpp on A1 CPU node pools: Here, the same Llama models are hosted on Ampere A1 CPUs through llama.cpp containers, optimized for further cost efficiency.
By offering both GPU and CPU inferencing options, organizations can evaluate the most effective choice for their specific use cases. The flexibility of this approach helps ensure that you can deliver high throughput with minimal impact on accuracy, providing optimal performance across diverse workloads.
The HorizontalPodAutoscaler (HPA) and cluster autoscaler further enhance scalability by automatically adjusting pod replicas and worker node pools based on real-time throughput or other relevant metrics, as monitored by Prometheus. Grafana is used for visualizing infrastructure performance, while OpenCost helps track and manage cost allocation for the OKE cluster.
Finally, API access to the inferencing models is managed through OCI load balancer as a service (LbaaS) and the OCI API Gateway, which helps ensure secure and reliable API endpoints.
Rate-limiting API calls with OCI API Gateway
As you scale AI infrastructure to support multiple client applications, managing how API calls are handled is crucial. Without proper rate limiting, you risk overloading the system, creating security vulnerabilities, and degrading user experience.
Using OCI API Gateway helps you manage and protect your GenAI APIs by enforcing usage plans and quotas. This method helps ensure that only authorized users can access the models, while providing a way to balance load and prevent abuse. With API Gateway, you can control access to your APIs by tailoring usage plans based on customer needs, adding another layer of flexibility and security.
Autoscaling the pods and GPU and CPU node pools
To meet fluctuating demand, the Kubernetes HPA automatically adjusts the number of active pods based on observed metrics. This adjustment becomes particularly important when serving LLMs at scale, where demand can vary rapidly.
For vLLMs, a key metric to monitor is vllm:num_requests_waiting, which tracks how many requests are queued when system resources, such as GPU capacity, are fully utilized. By scaling the pods and underlying GPU or CPU node pools based on this metric, you help ensure that the infrastructure can handle peak loads without sacrificing performance.
The HPA allows seamless scaling to help ensure that both compute resources and model deployments are optimized for varying workloads.
Observability and cost dashboards
Effective observability is critical to managing a production-grade GenAI deployment. In this solution, we use the Prometheus and Grafana stack for comprehensive monitoring and visualization of both infrastructure and model performance. The stack helps visualize critical OCI metrics, including API Gateway statistics, to track usage patterns and identify potential bottlenecks using the OCI Metrics plugin for Grafana.
We have also integrated OpenCost, a Cloud Native Computing Foundation (CNCF)-backed vendor-neutral, open source tool for Kubernetes cost monitoring. This tool gives you transparency into how your resources are being consumed and helps manage your budget effectively. We also track specific LLM performance metrics like time to first token (TTFT), intertoken latency (ITL) and total throughput, which are vital assessing the performance of your models, providing real-time feedback on inference times and throughput.
These observability tools empower teams to not only monitor the performance of their AI infrastructure, but also track the financial impact of their LLM inferencing, ensuring they can scale efficiently while keeping costs under control.
Performance testing with LLMPerf
To help ensure that our solution meets both performance and accuracy requirements, we used LLMPerf, a benchmark suite specifically designed for evaluating the performance of LLMs. LLMPerf includes the following tests:
- Load testing: Evaluates the performance of LLM models under varying load conditions, helping ensure they can handle production traffic without compromising response times.
- Correctness testing: Helps ensure that the models are delivering accurate results, with no degradation in quality from optimization or scaling.
We tested different configurations, such as the following use cases:
- Use case 1: Chatbot, inference server: llama.cpp, Model: Meta-Llama3.1-8B_Instruct, Quantization: Q8R16, input and output tokens: 100 each.
- Use case 2: Retrieval-augmented generation (RAG), inference server: vLLM, Model: Meta-Llama3.2-1B_Instruct, Quantization: FP16, input tokens: 2,000, output tokens: 200.
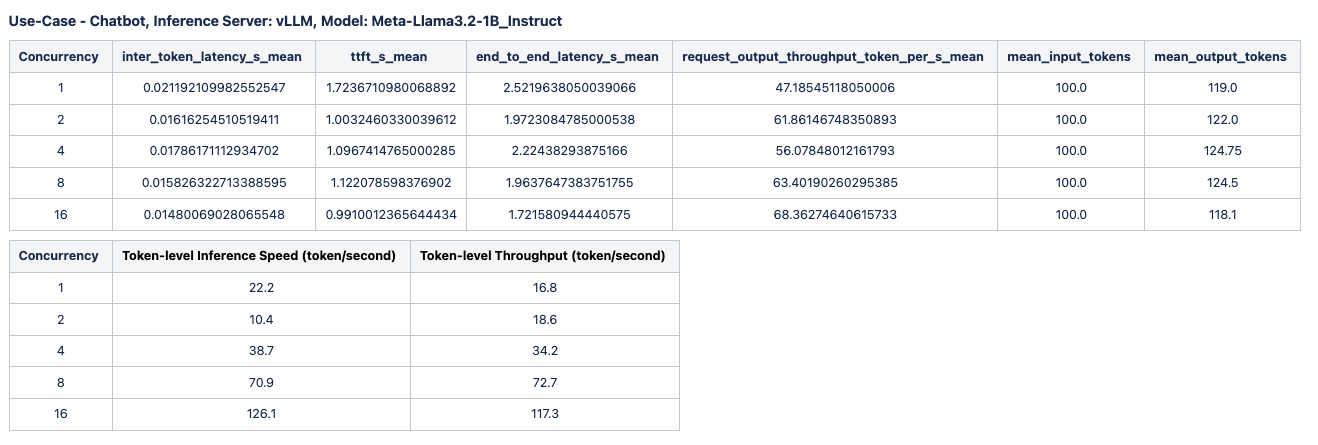
We captured and analyzed the performance results, including key metrics like TTFT, ITL, and throughput in tokens per second, to assess the system’s overall performance and suitability for different use cases.
The following image shows a sample result of performance testing:
Conclusion
In this post, we showed how to deploy a scalable, production-ready LLM infrastructure on OKE that balances cost efficiency with high performance. By offering both GPU and CPU options, OCI customers can optimize their AI deployments, achieving remarkable results with fewer computational resources. With integrated observability, cost monitoring, and intelligent scaling, this approach enables businesses to confidently deploy Generative AI solutions, helping ensure that they remain agile, cost-effective, and competitive in the ever-evolving AI landscape.
For scenarios where ultra-low latency and high-performance inference are critical, along with enhanced control over data and security, the outlined steps provide a solid foundation. For more demanding use cases that require larger models or access to more powerful GPUs, Oracle Cloud Infrastructure’s Generative AI service offers more scalability options to meet these needs.
For more information, see the following resources:


