When architecting a cloud solution to support disaster recovery scenarios, Oracle Cloud Infrastructure (OCI) provides great tools and patterns. Capabilities like DNS traffic steering, Active Data Guard, OCI GoldenGate, and Object Storage replication all factor into your tool belt when designing your architecture for business continuity. However, one area that deserves a closer look is the approach to architecting block storage for disaster recovery.
Current replication capabilities address many, but not all use cases
You can use block storage, whether in the form of single-attach block volumes or shared file storage, for various purposes include application binaries, configuration metadata, log files, or transactional content. The OCI Disaster Recovery Playbook addresses this topic for both block and file storage by recommending regular backups to a secondary region. While this approach works well for static or disposable content like binaries and logs, it’s insufficient for protecting high-velocity or high-volume transactional data like FTP files and message queueing storage.
The following sections explore the limitations of both services in protecting highly volatile file system data.
OCI Block Volumes
Earlier this year, Oracle announced cross-region block storage volume replication capabilities. This great feature automates asynchronous replication without use of backups and can facilitate various disaster recovery and data migration use cases. However, customers today face some disaster recovery use cases that are constrained by the current capabilities and require a different solution.
The recovery point objective (RPO) is defined as one hour, meaning that it could take as long as 60 minutes for a write on the source filesystem to be asynchronously replicated to the target region. While my testing showed this interval to be much shorter and Oracle promises to continue to reduce the RPO, an architect nevertheless needs to plan around the worst-case service level objective (SLO). If you’re architecting for disaster recovery and running a file system that receives a high volume of writes, such as an FTP repository or file system backing a message queuing implementation like Apache ActiveMQ, you can’t afford to lose even minutes of data.
Your choice of replication target regions is also constrained by the service. For example, primary environments in US-East (Ashburn) can replicate to Sao Paulo, Amsterdam, London, or Phoenix. But what if your preferred secondary disaster recovery location is in Montreal, Toronto, or San Jose? Similarly, while Zurich can replicate to Frankfurt or London, other close European cities like Amsterdam aren’t supported. If your deployment requirements don’t match with OCI’s defaults, you need to look for a different block storage replication solution.
OCI File Storage
Unlike OCI Block Volumes, no asynchronous replication capability is supported by OCI File Storage. While File Storage provides excellent in-region availability, when thinking about a regional failure, the documentation recommends creating a file system snapshot, backing up that snapshot, and moving the backup out of region. This approach not only requires automation to achieve but also isn’t suitable for high-volume transactional file data. Also, the creation of full backups regularly isn’t efficient from a storage space or bandwidth perspective.
An alternate open source solution: Lsyncd
You need a single approach that applies to both Block Volumes and File Storage which provides a solution for high volume, transactional data replication with potential for a low RPO.
Lsyncd is a free, open source, and configurable data replication solution that can deliver RPO down to minutes or even seconds. It functions as a Linux daemon, which watches a directory structure using the Linux’s inotify interface that allows it to detect changes like creates, updates, or deletes to files with minimum system overhead. Lsyncd aggregates and combines events for a configurable number of seconds and then spawns one or more processes to replicate the changes to the remote filesystem using Linux’s native rsync copy tool. Because lsyncd is installed as a system service from the EPEL repository, it can automatically survive virtual machine (VM) restarts and VM creation from a base image as part of a scaling group configuration.
As with everything in life, every solution has drawbacks and benefits. In this case, a self-managed solution like this one requires you to configure and monitor it to ensure that no errors are reported by Lsyncd that impact replication. OCI can help in this regard by allowing you to configure log monitoring agents that ingest the Lsyncd logs allowing you to search the logs for errors or configure the OCI Service Connector Hub to generate alarms if it detects errors. If you’re implementing this solution on File Storage, you need to ensure that Lsyncd is running on a single Compute node that mounts the shared filesystem and that this node remains healthy.
A sample configuration
Assume that we have a primary and secondary region. Each region has a File Storage (FSS) environment, which needs to be replicated, and each FSS is mounted on a Compute instance at /mnt/fss. A head node exists in the primary region with a private IP of 10.0.1.2 and a head node exists in the secondary region with an IP of 192.168.1.2. A remote peering relationship exists between the primary and secondary VCNs. If you want to replicate the configuration used in this sample, create an environment that looks like the following graphic:
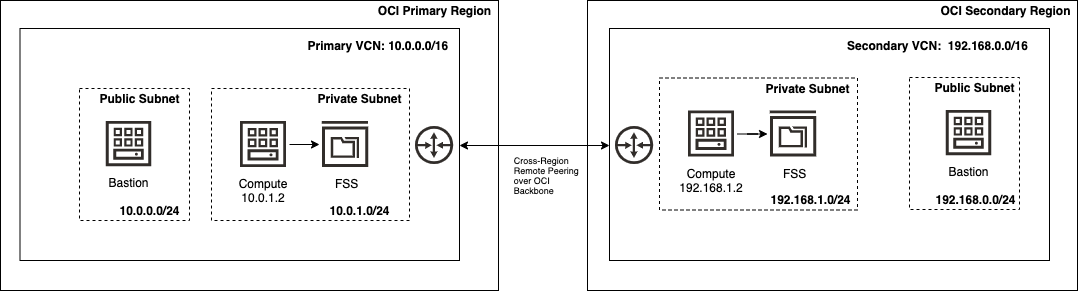
Refer to the OCI documentation if you need a refresher on creating a File Storage system, mounting a File Storage system to a Compute instance, or configuring a remote peering connection. When the architecture is deployed in your OCI tenancy, you’re ready to install and configure Lsyncd on the head node in the primary region such that it is responsible for replicating all file additions, modifications, and deletions from the primary FSS to the FSS in the secondary region.
Install Lsyncd
To install Lsyncd in OCI, enable the EPEL repository in your OCI Compute instance and then use the YUM package manager to install the latest version. The following commands accomplish this task and verify success.
sudo sed -i 's/enabled=0/enabled=1/g' /etc/yum.repos.d/oracle-epel-ol7.repo
sudo yum install lsyncd
lsyncd -versionPrepare the log directory
Lsyncd needs a directory to log status, info, and error messages. The lsyncd.log file is a good file to monitor for errors using whatever log monitoring and alerting solution you choose. Run the following commands to create the log target under the typical Linux /var/log structure and set appropriate permissions.
sudo touch /var/log/lsyncd/lsyncd.{log,status}
sudo chown -R opc:opc /var/log/lsyncdConfigure passwordless SSH
Lsyncd uses rsync, which requires an SSH connection between your primary and secondary hosts. The most seamless way to facilitate this connection is to link the two hosts using SSH keys. Run the following commands from your primary head node to enable the primary to securely copy files with rsync to the secondary head node.
cat > ~/.ssh/id_rsa {enter} {paste private SSH key to secondary node} {enter} {ctrl-d}
chmod 600 ~/.ssh/id_rsa
ssh opc@192.168.1.2 (make sure connection can be established)
sudo ssh 192.168.1.2 (this fails but registers the source server in the target)Configure and start the daemon
Lsyncd comes preconfigured with a sample configuration file that resides in /etc/lsyncd.conf. Open this file using your favorite text editor and replace the contents with the following configuration block:
settings {
logfile = "/var/log/lsyncd/lsyncd.log",
statusFile = "/var/log/lsyncd/lsyncd.status",
}
sync {
default.rsync,
source = "/mnt/fss",
target = "opc@192.168.0.2:/mnt/fss/",
rsync = {
_extra = {"--omit-dir-times","-e ssh -i /home/opc/.ssh/id_rsa"}
}
}Then bounce the service and verify that it starts with no issues.
sudo systemctl restart lsyncd
sudo systemctl status lsyncdThe successful result of the status command looks like the following image:

Double-check by verifying service startup in the Lsyncd log by issuing the following command:
cat /var/log/lsyncd/lsyncd.log
Test the setup
You can now start adding, modifying, and deleting files from the primary head node and, within seconds, see those changes propagated to the secondary region. The lsyncd.log file keeps a record of what changes are made and when they were propagated.
At any point, you can check the lsyncd.status file and see a snapshot of the status of the replication. If you check the file in the moments after you made a file change but before replication occurs, you can see that Lsyncd has detected modifications but is waiting to bulk them up into a single rsync push.

Handling a primary regional outage from a file replication perspective
You have now set up file system replication that protects your high transaction block volumes if an outage occurs in your primary region. You’ve also set up monitoring to ensures that your Lsyncd service is healthy and continuously replicating files.
Let’s say that a disaster has struck, your primary region is unavailable, and a business decision has been made to promote your secondary region to active mode. From the perspective of your replicated filesystem, no extra steps are necessary to switchover or hydrate your replicated store. The file system is automatically active in read/write mode and is ready to immediately begin receiving file modifications from user traffic that is routed to your secondary region when a DNS switchover has taken place.
Your only consideration now is to break the replication relationship from your original primary region because your secondary has taken a primary role, and you don’t want any inadvertent writes to the original primary to interfere with direct user traffic. If you have SSH access to your original head node, connect and disable the Lsyncd service to stop replication.
If SSH access isn’t possible, the next best approach is to break the VCN peering relationship from the secondary side by either removing the appropriate routing rule in your VCN’s route table or by stopping the remote peering connection. Your disaster recovery runbook needs all this information documented and should include steps to set up a new file replication relationship, perhaps to a third site, to act as a disaster recovery target for the newly promoted secondary region.
Conclusion
Oracle Cloud Infrastructure provides excellent tools that you can use to develop architectures that support diverse business continuity scenarios. In application topologies where high-velocity or high-volume block volume operations are performed, some extra tooling and configuration might be necessary. I hope that this blog has given you some insight into an availability solution that you can take advantage of in your deployments.
