We recently instrumented 10X performance improvements and higher resolution observability metrics into the OCI HDFS Connector to enable one of the largest Hadoop clusters in the world to migrate from on-premises into OCI. OCI Hadoop Distributed File System (HDFS) Connector enables customers to run their Apache Hadoop applications easily on Cloud Infrastructure (OCI) Object Storage. Customers prefer to run HDFS on OCI Object Storage as it offers massive aggregate throughput, liner scale and high durability at a lower cost than complex on-prem systems.
Why do customers gravitate towards OCI Object Storage for their Hadoop workloads?
Hadoop is a distributed compute and storage system that delivers massive aggregate throughput and allows parallel processing of many data sets at once. The standard storage interface to Hadoop is HDFS. A long list of big data tools from streaming data processing systems such as Flink to distributed database systems such as Pinot, and many others have standardized on this interface.
Many customers who use Hadoop or HDFS-based applications build and manage large clusters of machines in their own data centers. This setup comes with the upside of performance but with the downsides of managing a large cluster throughout its lifecycle, such as budget renewals, capacity planning, breaks fixes, technology refreshes, and version control. Even when companies build Hadoop clusters in the cloud, they might still rely on many manually configured volumes for the underlying data storage, which comes with many of the same downsides.
OCI Object Storage with the HDFS Connector overcomes all these downsides: It has unlimited expansion, requires no maintenance, delivers 11 nines of durability, and doesn’t require you to preplan or provision capacity. It’s also generally the least expensive option per GB stored.
But can Object Storage deliver the throughput required to match a large on-premises Hadoop cluster? And is it compatible with the existing HDFS applications? It turns out that the answer to these questions is yes!
Object Storage is not only a convenient, low-cost storage option, but like HDFS, it offers a distributed storage system that can deliver multiple TBs per second of aggregate bandwidth. The OCI HDFS connector bridges the gap between unmodified Hadoop applications and the Object Storage service. Many customers use this connector with success for their big data applications.
About the HDFS Connector
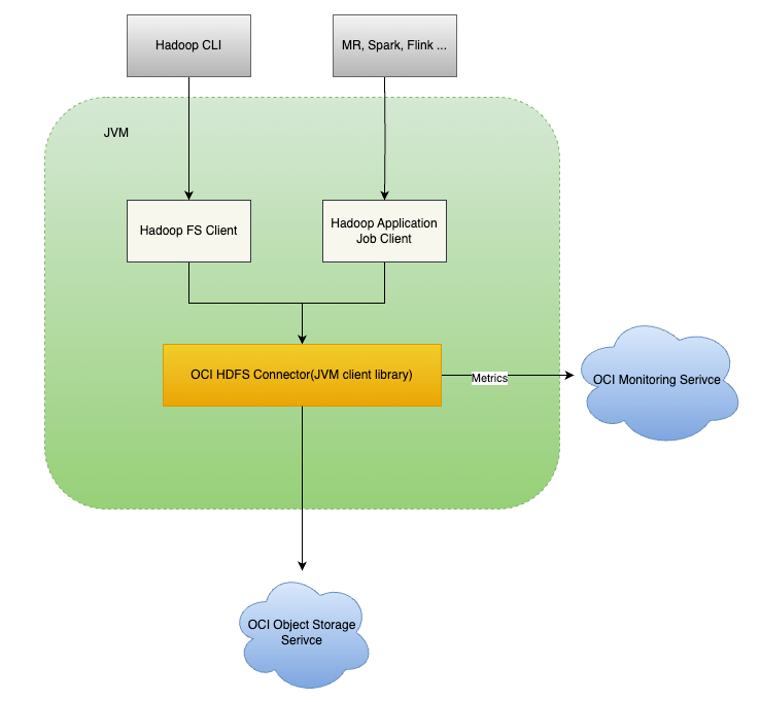
The Open Source (and OCI supported) HDFS Connector translates all application-level file system operations defined in HDFS interfaces into OCI Object Storage service API calls. The HDFS connector client runs in each Compute node and makes OCI Object Storage look like HDFS. Hadoop ecosystem applications, such as Map/Reduce, Flink, and Pinot, can talk to the HDFS connector with the standard HDFS commands, like dfsPut, dfsGet, and dfsCP. The connector translates those commands to perform the equivalent operations on OCI Object Storage.
These operations include tasks such as checking directory and file status, file creation, reading, and deletion. Furthermore, to enhance file system access performance, depending on the specific configurations in place, either partial or complete file content may be cached locally in memory or on disk before it is accessed by the application or uploaded to the storage service.
10X Higher Performance – Improvements and benchmark results
Recently, one of the largest Hadoop installations in the world decided to move many hundreds of nodes of HDFS storage into OCI Object Storage, and we decided to take a closer look to ensure that we were up to the challenge. Working with our customer, we ran an HDFS benchmark on their local Hadoop environment on-prem and then ran it again on OCI Object Storage. The new optimized HDFS Connector ran the benchmark test 40% faster on OCI Object Storage than the same test on one of the largest production Hadoop clusters in the world.
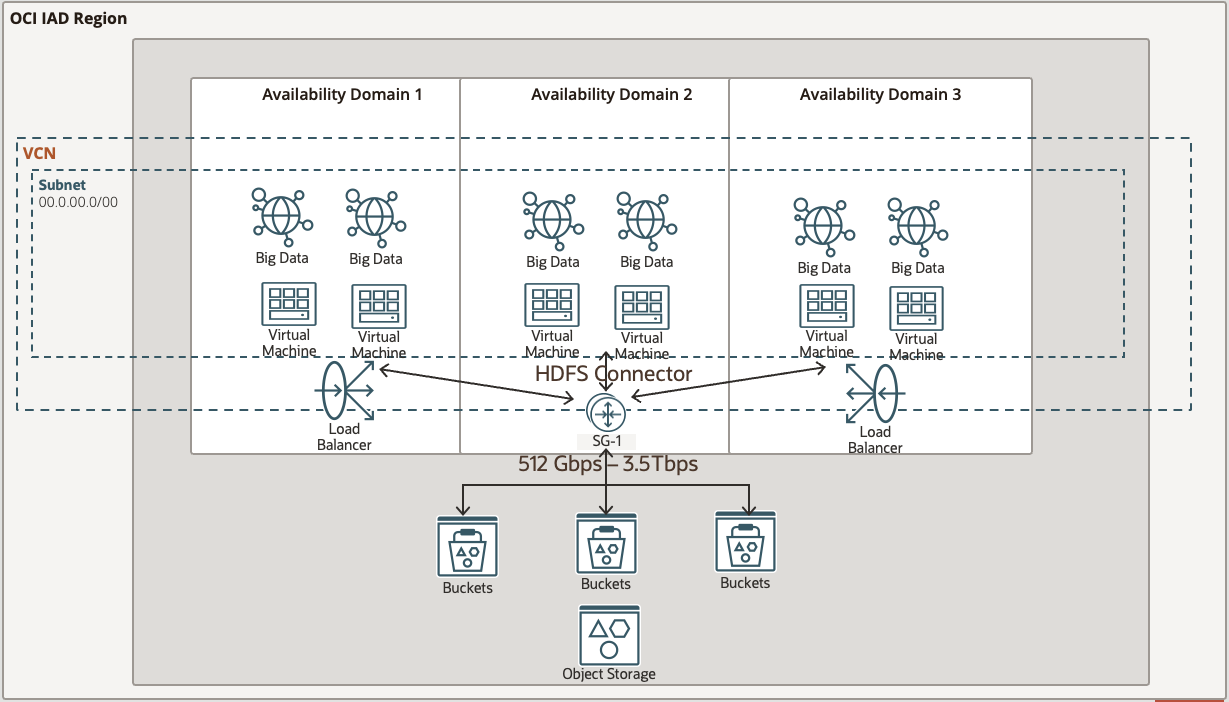
With those benchmark targets in hand, we started optimizing the connector to make maximum use of the distributed power of our storage platform. The latest version of the connector (starting with version 3.3.4.1.2.0) is now about ten-times faster than before! More importantly, the combination of the improved HDFS connector and OCI Object Storage is an average of 40% faster than our customer’s on-premises HDFS cluster.
These improvements are available to any OCI user and include the following features:
- Writing large files with parallel MD5 checksum processing: Improves PUT time on an 80 GB file by 75% over the previous version and 48% faster than the on-premises benchmark.
- Retrieving large files with parallel range-reads: Improves GET time on an 80 GB file by 800% over the previous version and 36% faster than the on-premises benchmark.
- Better memory management allows a dfs copy operation on an 80 GB file ten-times faster than the previous version and 56% faster than the on-premises benchmark.
- Improvements in directory listing speeds up small file processing: For a directory of 21K small files, dfsGET, dfsPUT, and dfsMOVE all improved by 25 times versus the previous version.
For more information, read the full release notes on GitHub.
Results
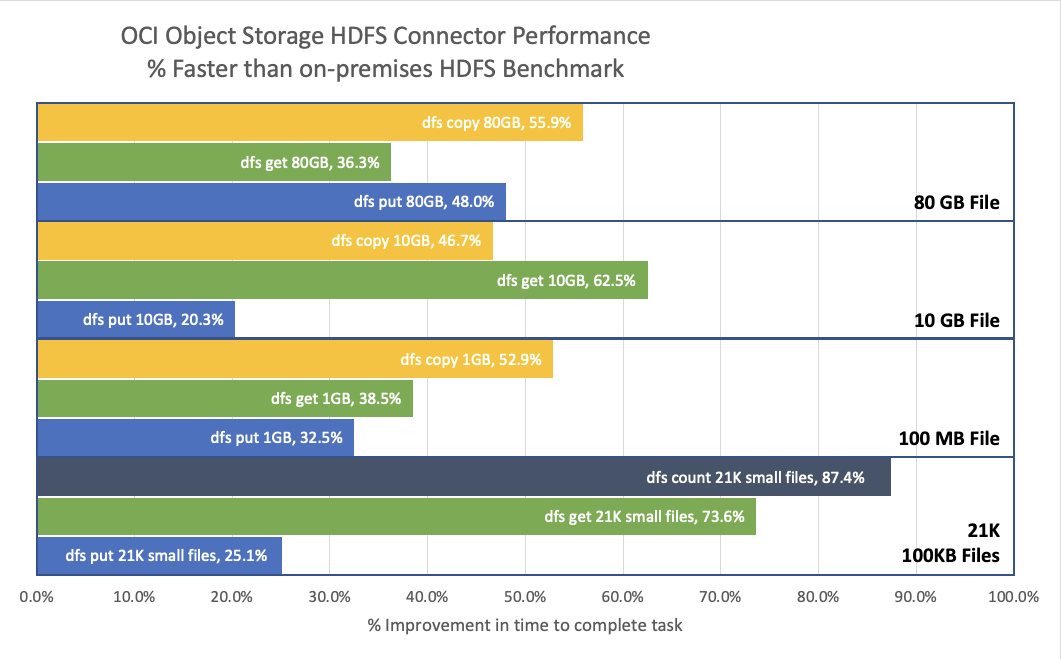
The following graph shows the tests in the benchmark (dfsGET, dfsPUT, dfsCP, and dfsCount) for four different file size configurations (80 GB, 10 GB, 100 MB, and 21K small 100 KB files) spread over many directories. The color of the bar indicates what kind of test it measures. For example, GET tests are green. For each combination of command and file size, we measured the number of seconds to complete the task, such as how many seconds to get an 80 GB file and how many seconds to count 21K small files. We ran this benchmark on the on-premises HDFS cluster and again on OCI Object Storage using the HDFS connector. The length of the bar indicates how much faster our optimized HDFS connector with OCI Object Storage completed the task compared to the on-premises HDFS cluster.
Monitoring the connector
The HDFS connector generates rich monitoring metrics. The metrics emitted by the connector can be monitored using the OCI public telemetry in the console (Metric Explorer) or your own monitoring application connected to the API framework. We recently enabled the following metrics:
LIST {COUNT, OVERALL_LATENCY, ERROR_COUNT}
HEAD {COUNT, OVERALL_LATENCY, ERROR_COUNT}
WRITE {COUNT, OVERALL_LATENCY, ERROR_COUNT, TTFB, BYTES, THROUGHPUT}
READ {COUNT, OVERALL_LATENCY, ERROR_COUNT, TTFB, BYTES, THROUGHPUT}
DELETE {COUNT, OVERALL_LATENCY, ERROR_COUNT}
RENAME {COUNT, OVERALL_LATENCY, ERROR_COUNT}
The operation will be appended with the metric to form the full key. For example: LIST_COUNT, LIST_OVERALL_LATENCY.
To start using the OCI Monitoring framework, you can setup the required properties in the core-sites.xml as explained in this document. The document also covers how your own consumer for the metrics can be created. By having the HDFS connector metrics in the same telemetry monitoring tool users can correlate metrics with both HDFS operations as well as Object Storage operations which are often different (e.g. multi-part upload, parallel downloads, etc.).
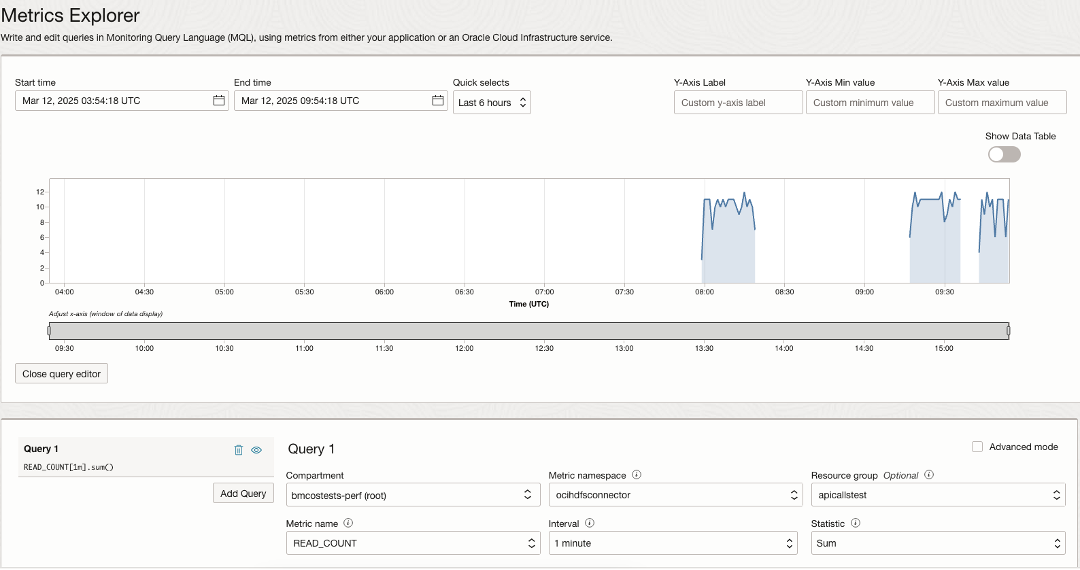
Examples of visualizing the exported OCI HDFS connector and Object Storage metrics in OCI Metrics Explorer are shown below.
Conclusion
While performance is an important consideration for migrating a big data environment to Object Storage, customers like it for its unlimited scalability, easy management, low cost, observability and high security. Analytics departments are eager to focus their attention and budgets on building the next great solution and not on managing a massive fleet of servers and disks, doing capacity planning, and coordinating technology refreshes.
Individual results vary, but we’re confident that the new HDFS connector is much faster than the old version, and we believe that, in our largest regions, we can offer performance that will satisfy compared to your on-premises infrastructure.
If you’re not yet using Object Storage for your big data workload, you should try it and see for yourself with an Oracle Cloud Free Trial. If you’re using Object Storage and haven’t updated to the latest connector, you might find that you’re leaving some easy performance gains on the table! The OCI Object Storage HDFS connector is available from GitHub and is automatically installed on each Compute instance in the Oracle Big Data service. For installation and usage information, see the official documentation.
Resources:

