Disasters like earthquakes, hurricanes, flooding, or other severe weather can cause unpredictable outages to an entire cloud region. Applications running on Oracle Cloud Infrastructure (OCI) and many other cloud vendors need to prepare and protect themselves from these regional outages. Storing data as objects within OCI Object Storage service can be subject to regional outages. Even though it’s highly available and durable, Object Storage is still a regional service and depends on the region it runs in. To mitigate and prepare for such disasters, you can deploy applications running their data through Object Storage in different regions that are geographically separate.
Let’s walk through how you can build your own disaster recovery strategy to ensure your application continuity in case of regional outages by replicating objects across OCI cloud regions.
A sound disaster recovery strategy consists of the following steps:
-
Preparing for a disaster
-
Implementing a disaster recovery setup
-
Handling application failover
-
Handling region recovery
-
Doing one-time reconciliation
-
Performing application failback
Remember to validate these recovery steps periodically by performing a disaster simulation exercise.
Preparing for a disaster
Although rare, a disaster can strike at any time and cause an entire cloud region outage. Applications deployed in a single region can become unavailable to their users in this scenario. However, you can architect applications for higher availability by running them in multiple geographically separated regions of OCI, so that application service remains unimpacted if an outage of one region occurs. If these applications are designed to store and use data in OCI Object Storage, then you need extra care that the data is available in a region outage.
Object Storage replication provides protection from such a regional outage. We recommend choosing an OCI region in the same country at a geographically far distance from the primary region as a replication region pair. For example, us-sanjose-1 can be chosen as a secondary region for us-ashburn-1 primary region.
Using cross-region object replication
To replicate objects automatically from one bucket to another in the same or different region, you must configure the required identity and access management (IAM) policies. Then, configure a replication policy on the source bucket by selecting the destination region and bucket to replicate objects to. Objects uploaded to the source bucket after policy creation are asynchronously replicated to the destination bucket. For details on how to set up cross-region object replication, see this tutorial.
Implementing a disaster recovery setup
With the object replication configuration in place, now customers can have application active in the primary region with a read-write bucket storing objects, which are replicated by OCI Object Storage to the secondary region read-only bucket, where the application can be passive and synchronizing with the primary.
To reduce impact to the application users during a disaster, the clients can be strategically programed to read from primary region (us-ashburn-1) first, and if the read fails, they can try to read from the secondary region (us-sanjose-1). If the object is replicated, it remains available in the secondary region. If a series of object read and write failures occurs in the primary region, then an application fail-over must be triggered.
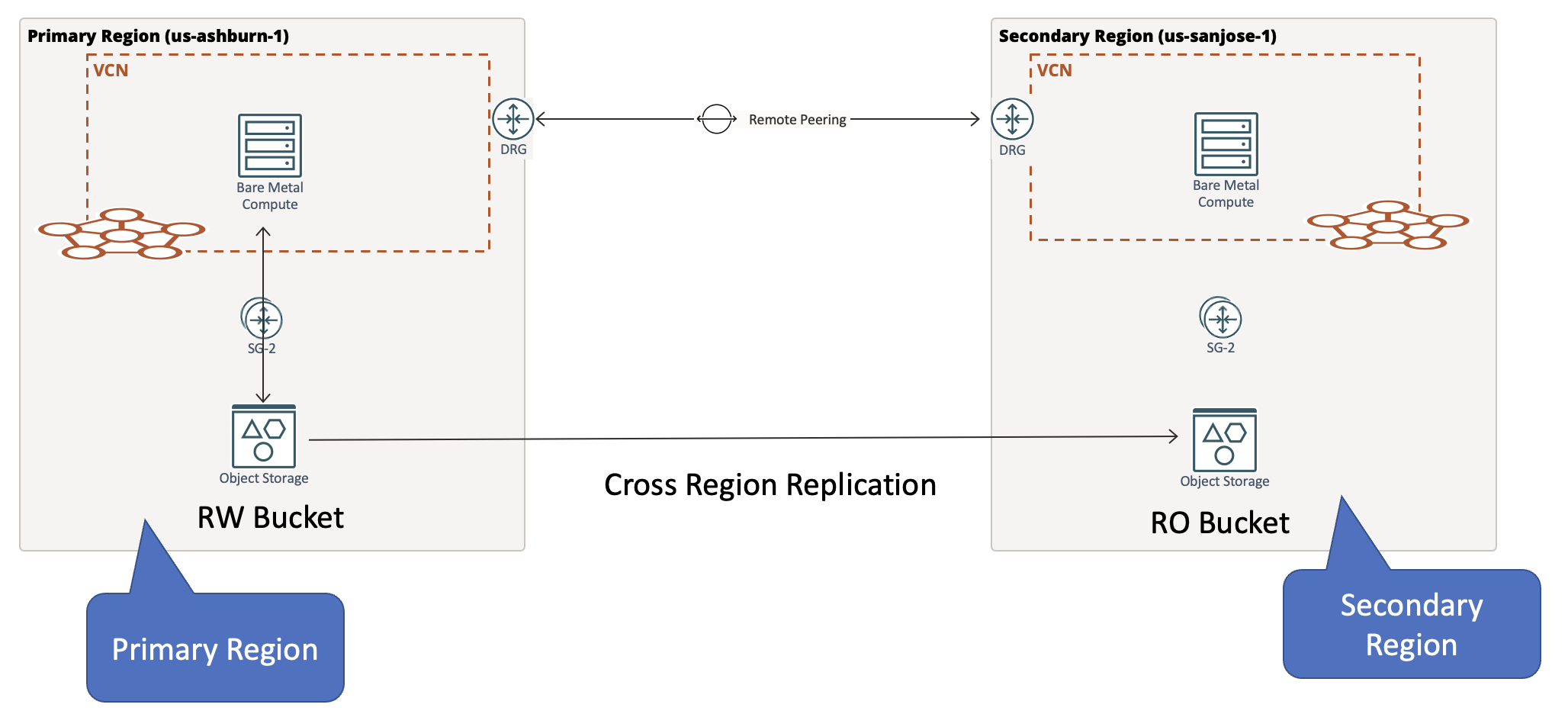
If the source bucket has existing objects before replication policy is created, they aren’t replicated. For these existing objects, you can replicate them with the following methods:
-
Read objects from source and copy them into the destination bucket using “if-none-match: *” to ensure that you don’t compete with replication
-
Read and write back the same object into the source bucket, which triggers replication of the object
Handling application failover
If the primary region goes down, an application failover must be triggered. Region outages stop the cross-region replication of objects. For the application in the secondary region to use the objects in the destination bucket, that bucket must be allowed read/write privileges.
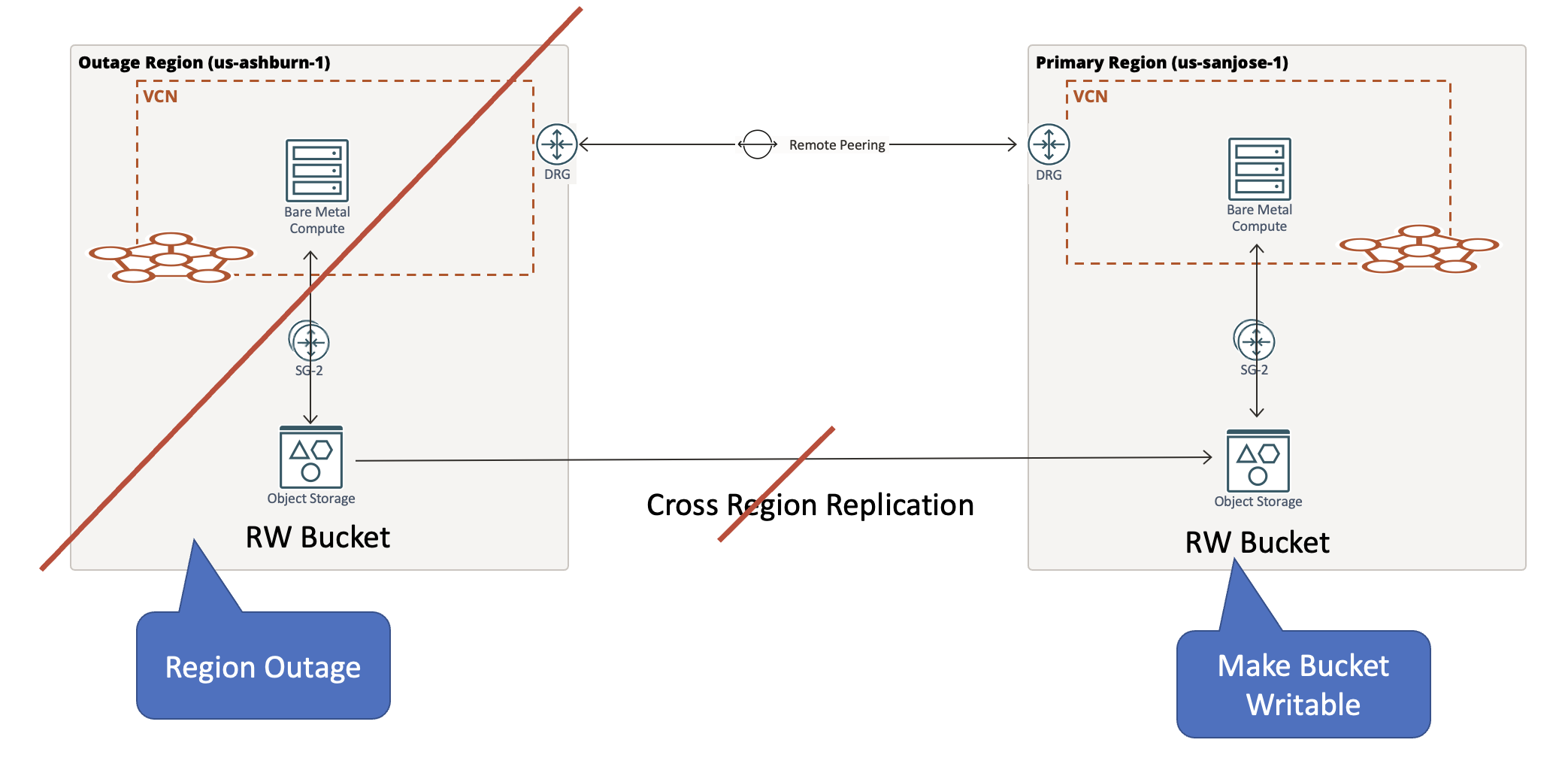
Handling region recovery
When the primary region recovers, it can be set up as the secondary region. The bucket in the new secondary region (us-ashburn-1) must be made read-only. Now, the cross-region replication must be configured on the primary bucket (bkp-media-bucket) in us-sanjose-1 to start replication to the media bucket in us-ashburn-1. Following the steps mentioned in the ‘Using cross-region replication’ section for the source bucket.
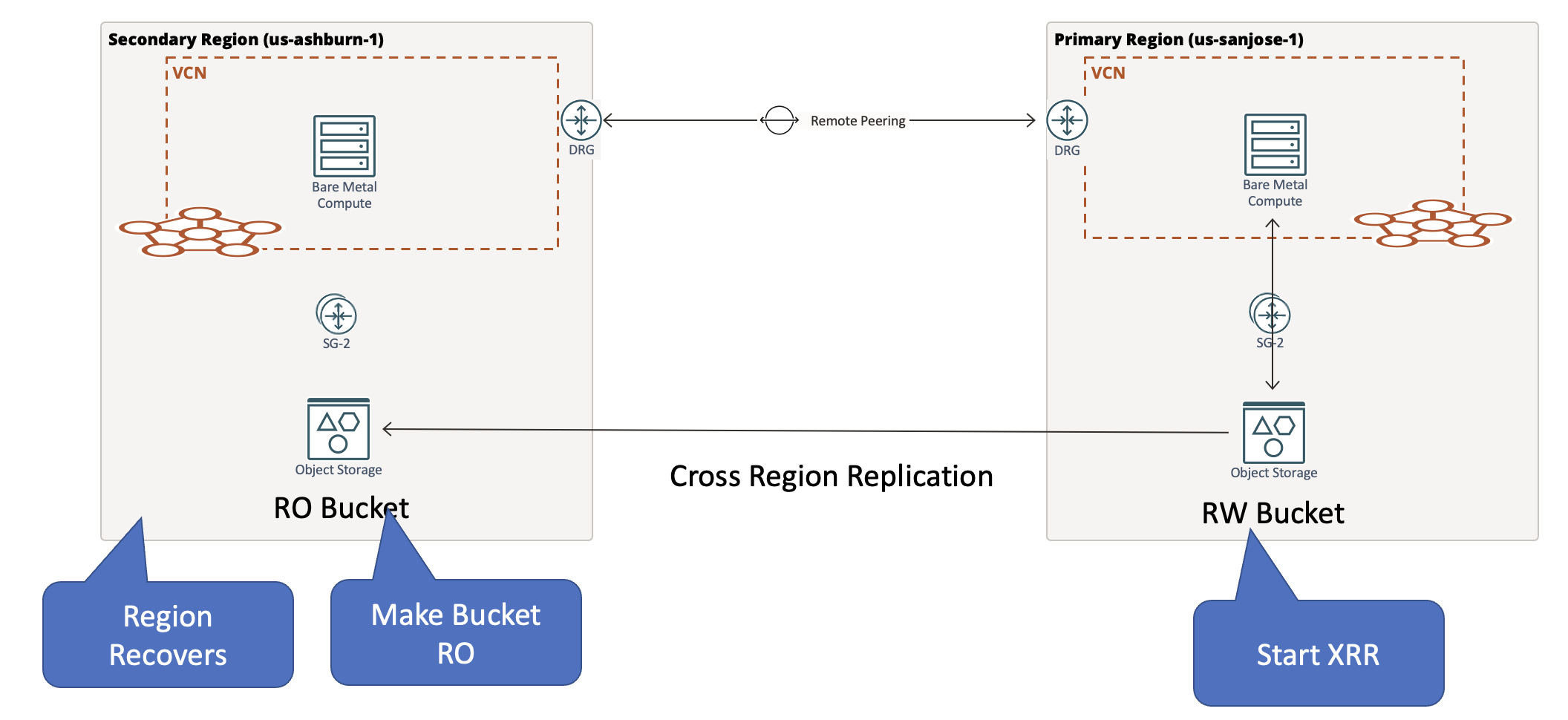
Doing one-time reconciliation
When the region recovers from the disaster, a one-time reconciliation can take care of the differences in the bucket contents. Depending on the recovery time objective (RTO) and recovery point objective (RPO) needed, the objects created, deleted, or updated while the us-ashburn-1 region was down must be synced up with the us-sanjose-1 region bucket.
List the buckets in both source (us-sanjose-1) and destination (us-ashburn-1) regions. As you discover differences, you have the following possibilities:
-
Object exists in us-sanjose-1, but not us-ashburn-1: Copy the object, using “if-none-match: *” to ensure that you don’t compete with replication.
-
Object exists in us-ashburn-1, but not us-sanjose-1: This object either wasn’t copied by replication or was replicated and then deleted in us-sanjose-1. Leaving these objects is safest, but the application might have a better way to determine what to do.
-
Object exists in us-sanjose-1 and us-ashburn-1, but the objects are different! This is the hardest part of reconciliation. Take one of the following approaches:
-
Throw an error.
-
Move one object to a “conflict” bucket and have someone look at it.
-
Last writer wins (by clock time)
-
Application-specific merge logic
-
First writer wins.
-
The new primary region always wins.
-
After reconciliation, the application can choose to continue with this configuration as the new steady state operation. In this case, us-sanjose-1 can be the active primary and us-ashburn-1 can be the passive secondary region, so the following fail-back step is not needed.
Performing application failback
If you want application failback to the original primary region (us-ashburn-1), use the following steps. When reconciliation is complete, allow the application, make the bucket in primary us-sanjose-1 read-only, make the bucket in us-ashburn-1 read-write, and configure object replication in the other direction. Then trigger the application failover. After completion, the original state is achieved with us-ashburn-1 as the primary region.
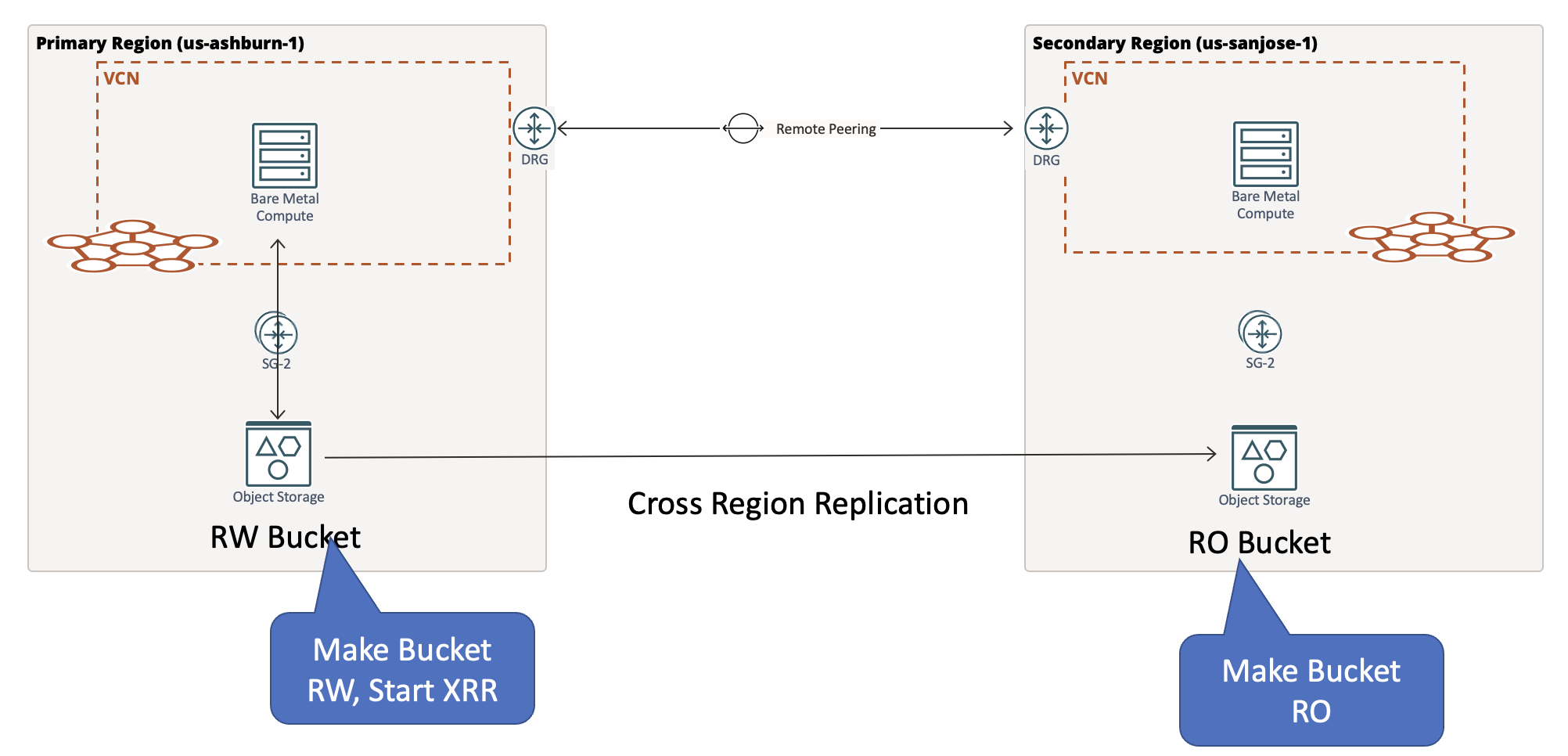
Conclusion
You can use the method in this blog to configure object replication for disaster recovery scenario. You can use the steps in this tutorial to configure object replication. Use the steps in this blog as a guide in recovery of applications if a disaster occurs.
To learn more about OCI object Storage replication, see the documentation. To get started with Oracle Cloud Infrastructure, create a free trial account.
