Have you ever encountered the need to implement a feature that is common to several services? As the number of microservices grows, so does the complexity of managing cross-cutting concerns such as routing, throttling, security, and load balancing. For example, enabling authorization requires each microservice to integrate with an Identity service, which results in duplicated code across services. This not only creates maintenance overhead but also amplifies the risk of vulnerabilities and bugs.
I’ve seen firsthand the importance of consistency in customer-facing platform features. With over 17 years of industry experience, including six-plus years at Oracle, I’ve witnessed the complexities that arise from inconsistent experiences across services. For instance, something as simple as search functionality or auditing APIs can become a significant challenge. One such scenario can happen when services need to adopt a newer version of audit logs. Due to slow adoption, some services send richer logs but not others. This kind of inconsistency can cause confusion and a poor customer experience.
In this blog, I will discuss our approach to solving behavioral consistency through a platform consistency service. I will also delve into the challenges of architecting this centralized platform and explore the “golden paths” that help accelerate the delivery of services to customers and apply streamlined compliance for customer safety. By sharing our experiences and insights, we also aim to provide a valuable resource for organizations struggling with consistency in their microservices architecture.
Background
In the early days of Oracle Cloud Infrastructure (OCI), we had a limited number of cloud services that directly interacted with platform services like Identity and Audit. Service teams also used to manage API platform along with their services. The API platform offers routing and throttling functionality. As shown in Figure 1, Infrastructure-as-a-Service (IaaS) services such as Compute, Block Storage, and Virtual Cloud network were hosted behind a service instance of a Public API platform. Similarly, a set of database services were behind another service instance of the Public API platform, and so on. This simple architecture allowed us to manage and maintain our services with relative ease.
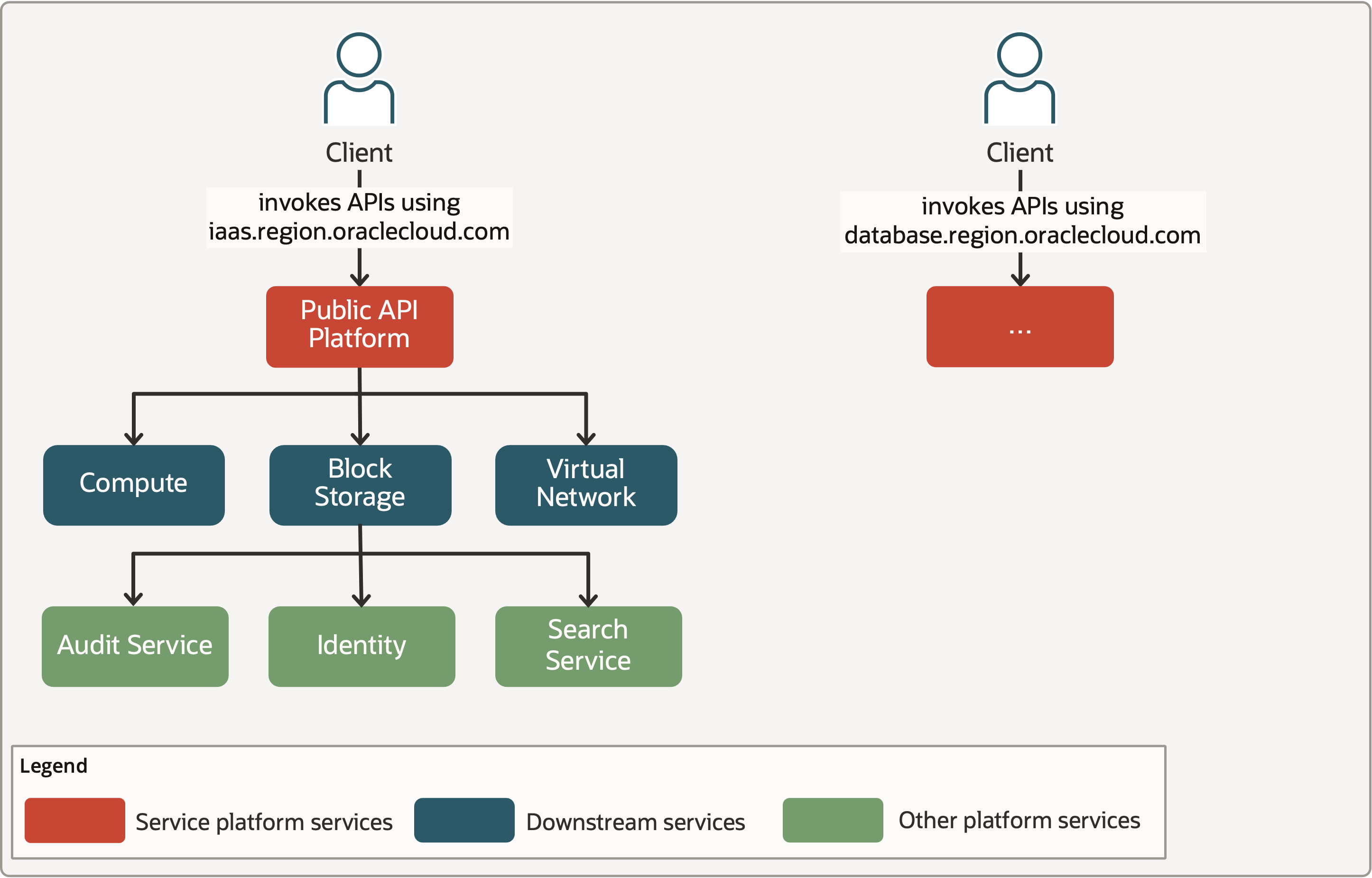
Figure 1: Bird’s-eye view of Public API service platform
In reality, interactions between downstream services and platform services looked like the ‘where we were’ section of Figure 2. Interactions between services are complex and it’s not easy to troubleshoot the issues. Any changes to the platform service require changes in multiple downstream services. Our objective is to simplify the interactions which are shown in “where we want to be” section of Figure 2.
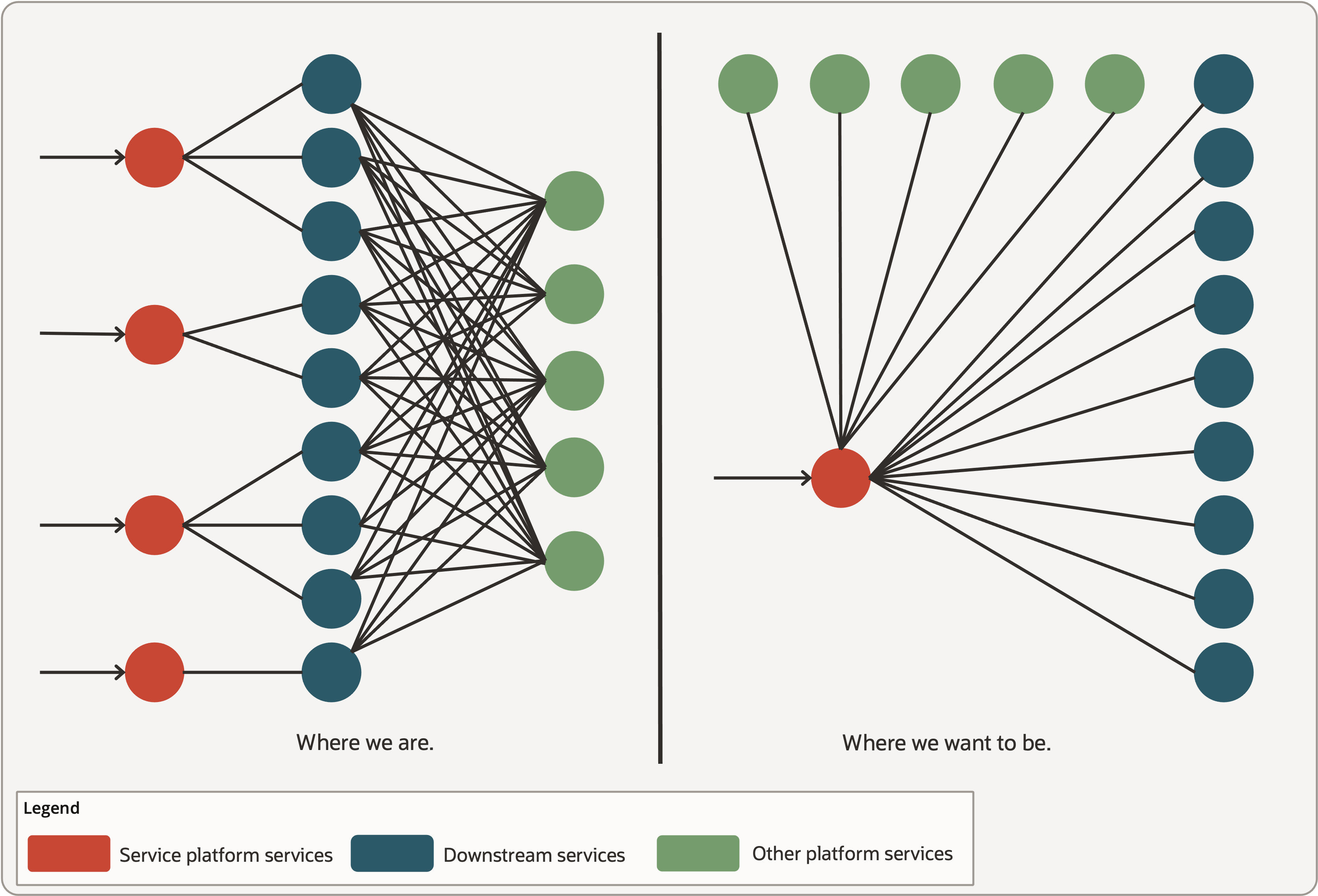
Figure 2: Request flow between services
The API platform relies on configuration files to manage the API routing and its behavior. As can be seen, the below snapshot contains a sample configuration for API Matcher configuration. It contains a list of regex paths used to match incoming request paths. Once the API is identified, another resource configuration file is used to determine the API endpoint and its behavior.
Sample API matcher configuration
{
api: "launch-instance"
uriRegex: "^/\\S+/instances$"
requestMethod: "post"
}
This architecture works well for a small set of services. As our cloud service offerings grew, we encountered the following challenges.
- Lack of expertise in the platform features could lead to outages or security gaps, especially with authentication and authorization.
- Any updates or fixes to the platform SDK require changes to be made to every service, resulting in a maintenance cost proportional to the number of services.
- There was a significant amount of hand-holding between platform teams and service teams, which was time-consuming and inefficient.
In one of our largest regions, we noticed a consistent 15% quarterly growth in the request rate. Upon reviewing our architecture, it became clear that platform features that span multiple services significantly increase the overall complexity of the service. These cross-service features introduce additional dependencies, interactions, and potential failure points, making it more challenging to maintain, update, and scale the platform.
Service Platform architecture
In addition to the challenges that were presented in the above architecture, we wanted a service that could route traffic over 400 cloud services. The service would need to be stateless, flexible, scalable, and super reliable. It would need to consider noisy neighbor scenarios and have low latency overhead for platform features. This would help ensure the traffic to downstream services is highly predictable.
The Proxy service plays a pivotal role in our architecture by acting as a gateway for all incoming requests. It applies crucial request-based features, helping ensure secure and controlled access to downstream services. However, to accurately apply these features, the Proxy requires detailed information from service owners regarding platform-specific features and their associated inputs. This is where Swagger specifications come into play, offering a standardized way to document RESTful APIs. By utilizing these specs, we help ensure a straightforward configuration process, reducing the need for complex configuration files. The Service Registrar is the central component that facilitates this process, providing a platform for service owners to upload and deploy their Swagger specifications, thereby enabling the Proxy service to seamlessly apply the necessary features at the API level.
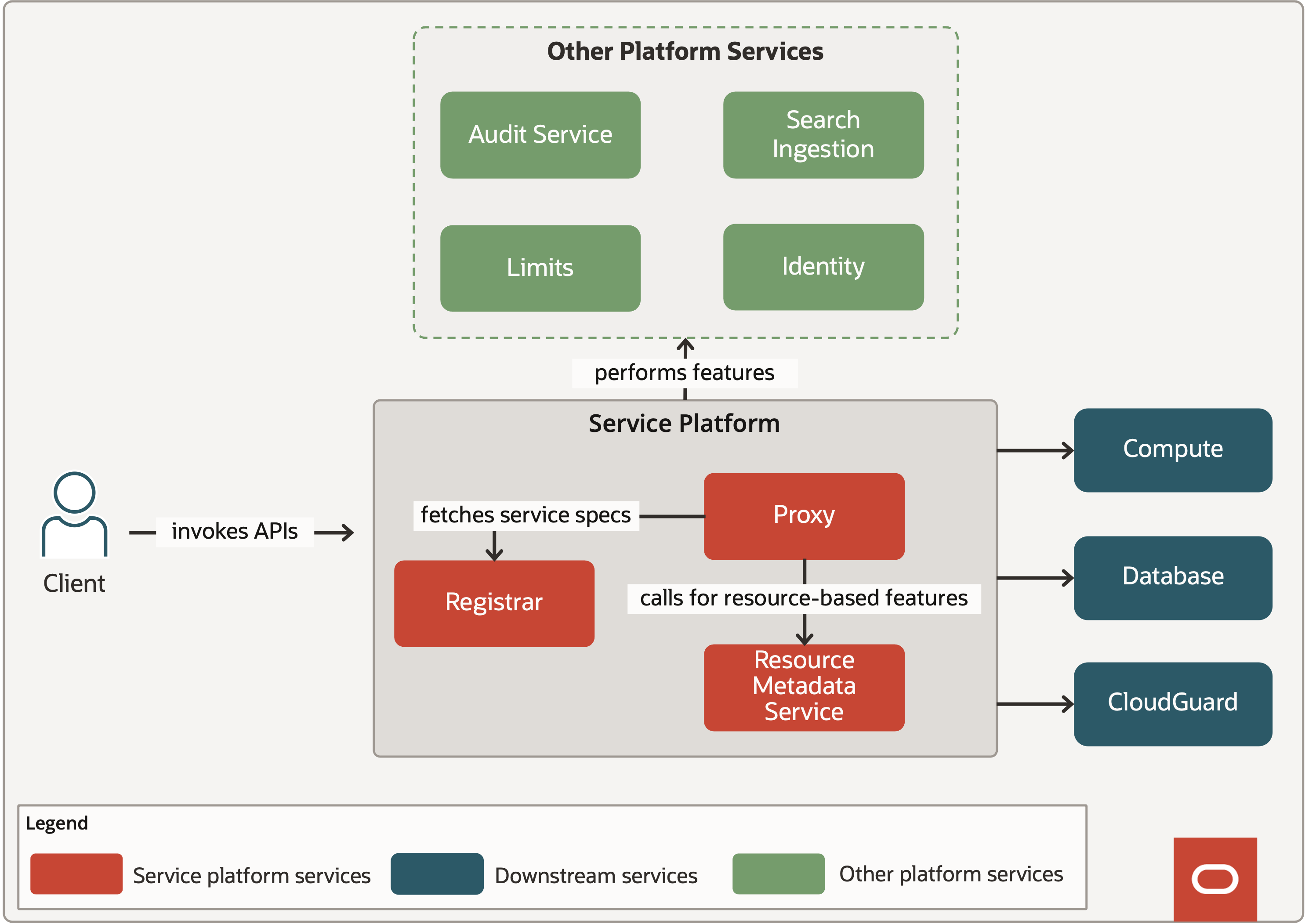
Figure 3: High-level Service Platform architecture
With our request-based features taken care of in Proxy layer, we decided to take our Service platform to the next level by tackling another set of platform features that are based on resources. For this, we introduced the Resource Metadata service. As shown in Figure 3, Proxy calls this metadata service to apply resource-based features such as resource limit enforcement, indexing resources and so on.
Also, the Proxy fetches the service specs from the Registrar and caches them on disk. The specs get updated periodically in the background. This makes the Registrar a soft dependency. Having as few dependencies as possible improves resiliency. The Proxy integrates with other platform services to enable platform features. There is no need for Downstream services like Compute to talk to Identity once the features are enabled through Proxy.
Journey of a Cloud Service Request
Currently, the Proxy service routes more than 65k distinct APIs and can process several hundred thousand requests each second. Since we have a high-level overview of The Service Platform components, let’s look at the journey of a request.
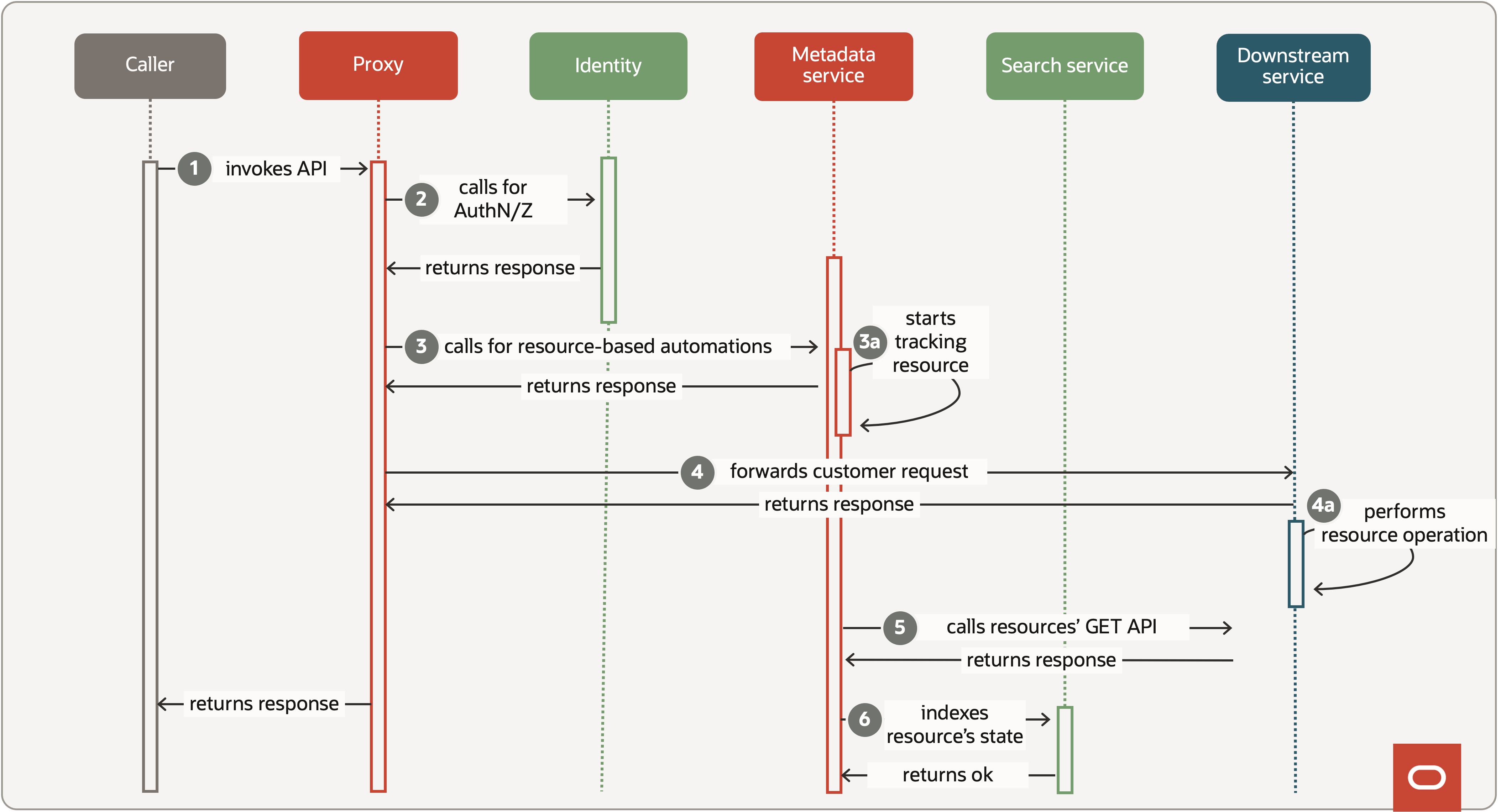
Figure 4: Request flow in the Service Platform.
When a request is made to any cloud service, it is routed to the Proxy service hosts. The Service platform supports only HTTPS connections, offering secure communication between clients and services. Managing DNS and certificates for multiple services can be complex, and many organizations struggle with certificate-related outages. In contrast, our approach at the Service platform layer involves periodic monitoring of both upstream and downstream certificates. This proactive approach enables us to detect and address potential issues before they impact our services.
As shown in Figure 4, the sequence diagram demonstrates an example of how the Service platform handles a request-based feature and a resource-based feature. The following steps provide a more detailed look at the request-handling process.
The Proxy service is like a conductor in an Orchestra, which uses other platform services to provide necessary platform features to Downstream services.
Simplifying Service Platform Architecture Through Standardization
I’ve spent years working towards a single implementation for all platform features, and I can attest that achieving this is more complex than it sounds. In my experience, different services written in various languages and exposing their functionality in different methods such as APIs, SOAP, and RPC, can make it harder for us to support them and add complexity to our Service Platform architecture. I recall countless hours spent troubleshooting issues that arose from trying to integrate common features across different platforms, and I knew we needed a better approach.
To address this challenge, we’ve established engineering practices and a release process that promotes standardization. We recommend that new services clone from a vanilla service. We also help ensure that our public APIs follow industry standards. As a result, around 80% of our services now follow standard guidance, which has significantly improved our Service platform architecture and organizational efficiency.
At Oracle, we prioritize our customers’ needs. Over time, I’ve learned that the most successful products are those that address specific pain points. For example, setting up the authentication for an API is entirely different from auditing an API call, and asking the teams to perform different steps for these features can be a real pain. That’s why we need a platform that provides a consistent way of handling these features.
Let me show you an example of how we do this. We use a custom extension in an API definition called x-platform. Here’s what it looks like:
Launch Instance API
/instances:
post:
x-platform:
audit:
mode: enabled
additionalFields:
ipAddress: response.body.IpAddress
authentication:
mode: oci-signature
Now, we know that every service could be a little different, so we need to be able to accommodate those variations. That’s where Groovy comes in – a dynamic scripting language that lets us represent logic in a super concise way. In the above example, Compute could add extra attributes to audit events. It’s given us a ton of flexibility and helped us avoid custom code for specific services.
Resource Metadata service
Let’s dive a little deeper into the Resource Metadata service architecture.
When the Metadata service receives a request from the Proxy service, it checks if the request is within service limits to help ensure fairness across customers. Metadata tracks usage at the resource/account level and stores this data in relational databases.
If the request is within limits, Metadata creates a reconciliation request to track the resource’s state. If processing fails, Metadata reverts the resource state using a 2-phase commit protocol to help ensure consistency. The service then polls the resource’s state using an exponential backoff algorithm until it reaches its final state, at which point additional resource-based features are applied.
To give you an idea of just how big this system is, in one of our largest regions, the metadata service is managing over 200 million resources. Data is sharded based on the tenancy at the application level. The tenancy is an isolated environment for managing cloud resources. This means that all requests for a customer are served from a single shard. By sharding the data, we get high throughput and reduce the impact of DB outages.
We also have standby databases ready to switch over in case of failures or maintenance, and we take periodic backups for data recovery. One thing we’ve noticed is that some shards can get “hot” due to the allocation of active tenancies. To balance out the request traffic and volume, we’ve implemented live resharding at the application level. This lets us migrate resource data from hot shards to less active shards without any downtime.
Once we got our core services like compute, virtual network, and block storage onboarded for platform features, we started to see some real improvements. We were running internal tests with Gartner to launch instances, and the results were consistently great. The problem was that there were all these extra storage calls that were slowing things down – and they weren’t even related to creating the resource itself. We’re talking about things like updating usage records and persisting data for background processing to index the resources. But with the platform features in place, we were able to streamline the process and make APIs much more efficient.
Scaling the Service platform
Now that we’ve talked about the resource metadata service architecture, let’s take a step back and look at the bigger picture. To help ensure scalability and reliability, we’ve deployed our services across multiple regions. As we were building out the Service Platform, we knew we needed a way to provide more isolation between services. We didn’t want a request spike in one service to bring down the whole platform. That’s where our cell architecture comes in.
Think of a cell like a self-contained unit that has its own DNS, load balancer, and hosts. It’s isolated enough that if something goes wrong in one cell, it won’t affect the others. We use DNS to map requests to a specific cell’s load balancer IP address, and then the request gets routed to the right cell. We partition the Proxy cells based on services. Each downstream service gets registered to a specific proxy cell. As shown in Figure 5, all the traffic to a particular service goes to a specific cell. We have come across an incident where one of the services has a bursty traffic pattern. Thanks to this cellular architecture, we were able to migrate the service to a new cell so that other services remain unaffected.
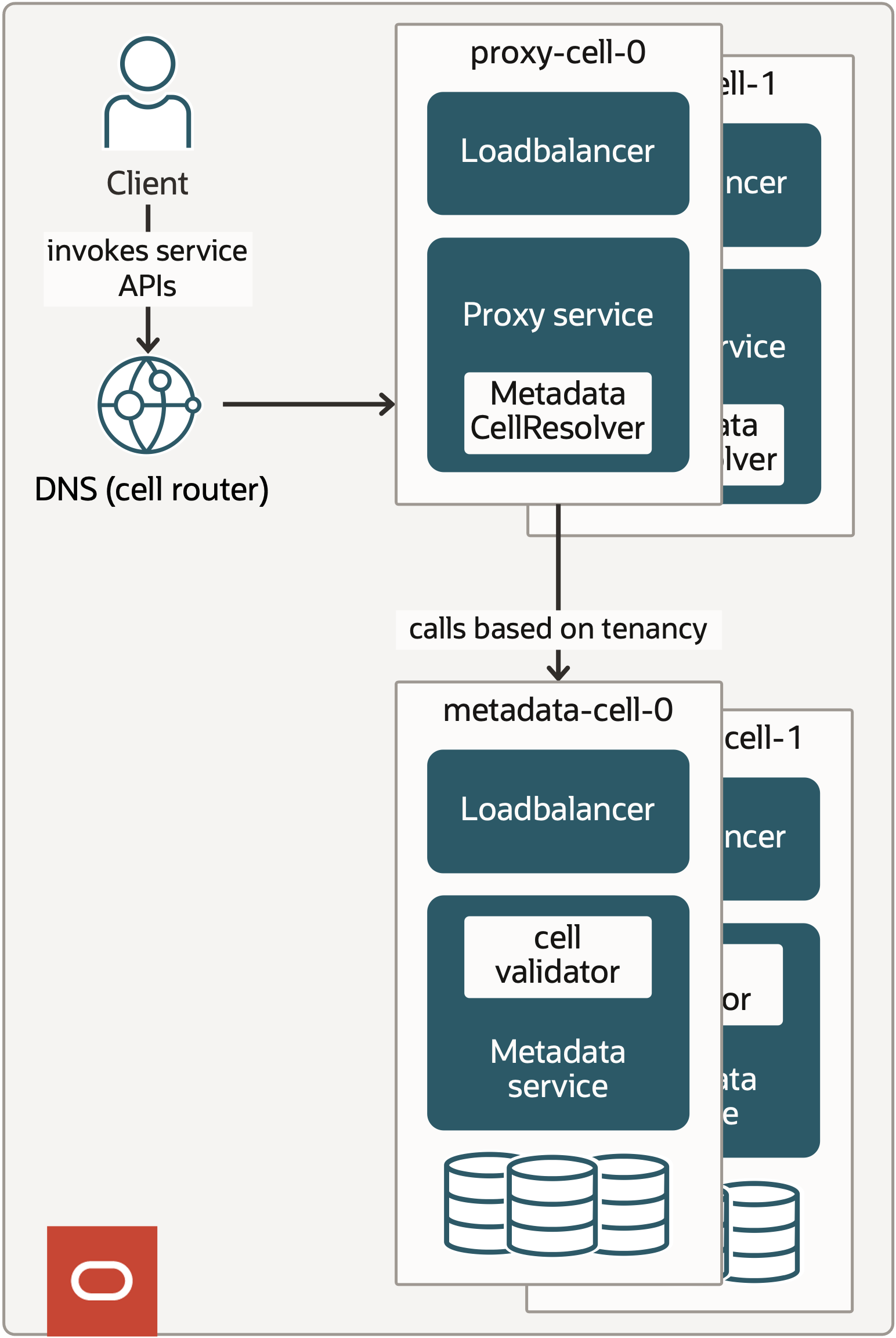
Figure 5: Cellular architecture of the Service Platform.
Now, you might be wondering how the Resource Metadata service fits into all this. Well, it uses cells too – but in a slightly different way. For the Metadata service, a cell is made up of a load balancer, hosts, and databases. We can’t partition the cells by service like we do with the Proxy service, because the metadata service offers features that span multiple services. Instead, each metadata cell handles a certain percentage of tenancies. To make sure everything works smoothly, we have a cell resolver module in the Proxy that finds the right metadata service endpoint based on tenancy and a cell validator in the Metadata service that checks whether the request is routed to the correct cell. If everything looks good, the cell accepts the traffic.
In one of the larger regions, we have more cells to handle the traffic. As our request volume grows, we can simply add more cells to handle the traffic.
How does the Service platform help with API security?
Before we wrap up this blog, let’s talk about something really important: security. At Oracle, we’re committed to making every cloud service API we expose as secure as possible. We want to help ensure that every request that comes in is thoroughly vetted before it reaches our downstream services. To do that, we’ve set up a series of secure access controls that every request has to go through. This includes things like authentication, authorization, network access-based control, maximum security zones, and so on.
The majority of the APIs use oci-signature as an authentication mechanism. However, we also know that one size doesn’t fit all. That’s why we offer a range of mechanisms, including basic, bearer tokens, OpenID Connect, etc. In some cases, our downstream service APIs are enabled with multiple authentication modes. We want to make sure that the service owners have the flexibility to choose the authentication method that works best for them.
Authorization is also a top priority for us. Our service owners specify what permissions are required to access a particular resource, and our platform performs the necessary checks by calling our Identity service. It’s all about making sure that the right people have access to the right resources.
For example, let’s say you want to create a load balancer. You need to have the right permissions on the subnet. But what if the subnet is owned by a different service? Our platform is robust enough to handle these cases. We can specify the permissions required for a particular resource, and our platform will take care of the rest. Here’s an example of how it works:
Loadbalancer API definition
/loadbalancers:
post:
x-platform:
resources:
Subnet:
forEachInArrayExpression: subnetIds
targetCompartmentId: service.invoke('VirtualNetworkService','GetSubnet', each).compartmentId
permissions: ["SUBNET_ATTACH"]
authorization:
check: resourceList["MyResource"].every { it.grantedPermissions.contains("SUBNET_ATTACH") }
As you can see, our platform makes it easy to manage complex authorization scenarios without a lot of boilerplate code. We’re all about making things simple and secure, so our Service owners can focus on what matters most – building great services.
Conclusion
The Service Platform is the backbone of our cloud infrastructure and currently offers more than 15 platform features. Our centralized architecture enabled us to reduce infrastructure costs and developer effort, as we no longer needed to learn and integrate each service individually.
Here are some key takeaways:
- Faster rollout of organization-wide features by eliminating the need for all services to make code changes, test, and deploy.
- A centralized platform helps ensure that all services are in compliance with security standards, providing an additional layer of protection and assurance.
- Enforcing standards and having a single implementation for platform features improves the organization’s productivity.
This blog series highlights the new projects, challenges, and problem-solving OCI engineers are facing in the journey to deliver superior cloud products. You can find similar OCI engineering deep dives as part of Behind the Scenes with OCI Engineering series, featuring talented engineers working across Oracle Cloud Infrastructure.