Introduction
Companies are looking to utilize high-performance computing (HPC) in the cloud for various reasons. Some customers are looking to fully transition their on-premises HPC to the cloud in a lift-and-shift manner, while others wish to augment their on-premises infrastructure in a hybrid or burst way. Oracle Cloud Infrastructure (OCI) has recently released two new Compute shapes with the 4th generation AMD EPYC “Genoa” processor, the bare-metal (BM) BM.Standard.E5.192 with 192 physical cores, and the virtual machines (VM) VM.Standard.E5.Flex with up to 94 physical cores. We explored the performance potential on these new shapes with Ansys Fluent version 2023 R1, an industry-leading computational fluid dynamics (CFD) and multiphysics application. The upcoming HPC, optimized, and dense I/O Compute shapes weren’t considered for these tests.
Benchmarks
Our reference was an right-node cluster based on our current HPC-purposed shape, BM.Optimized3.36, with dual 3rd generation Intel Xeon “Ice Lake” 18-core processors, 512-GB memory, 3.2-TB NVMe, and ultralow latency 100-Gbps RDMA over converged ethernet (RoCE) v2 network. We discuss the new HPC-purposed AMD Genoa shape in an upcoming paper. We also tested a BM.Standard.E4.128 cluster based on the 3rd generation AMD EPYC “Milan” processor. All clusters were instantiated using an HPC stack in the OCI Resource Manager using a Terraform template turning a collection of instances into a functional HPC cluster, as described in this reference architecture. The following table describes the test systems.
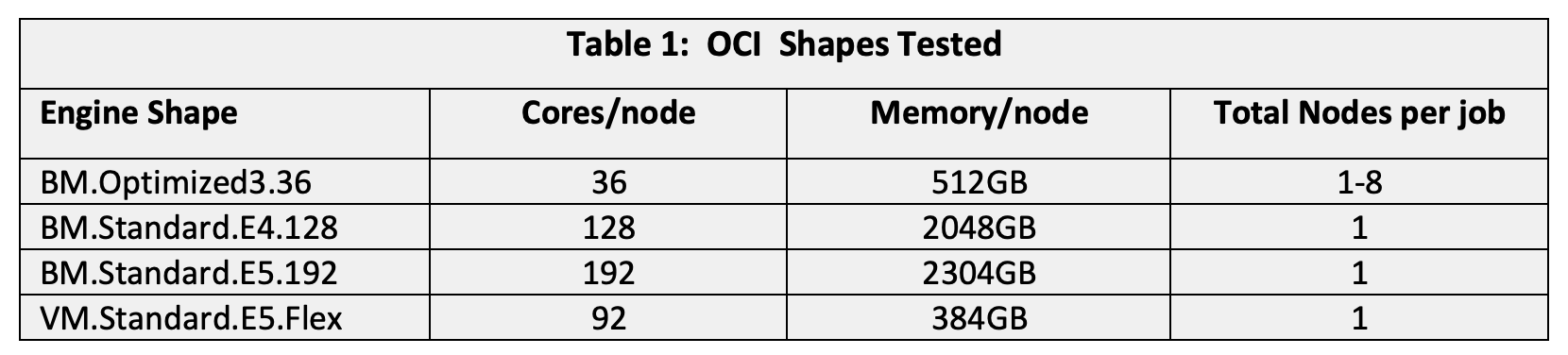
For the shapes without an RDMA network, we tested only single Compute node jobs as nonRDMA network performance can make multinode test results variable. However, a single AMD Genoa-based node with up to 192 cores can offer performance comparable to many current multinode clusters. The bare metal shapes have fixed core and memory. The new VM.Standard.E5.Flex Compute shape is flexible, allowing the user to specify the number of cores and memory (subject to constraints) for the node. We chose 92 cores and 384-GB memory (4 GB/core), balancing price and performance for a wide range of CFD analyses.
We tested the following standard Fluent benchmarks: sedan_4m, aircraft_wing_14m, combustor_71m, f1_racecar_140m, and open_racecar_280m, representing a variety of CFD workloads. We reported benchmark performance based on the “Solver rating” reported from the output file of the “fluentbench.pl” script, representing the total number of jobs per day. In the following chart, higher is better.
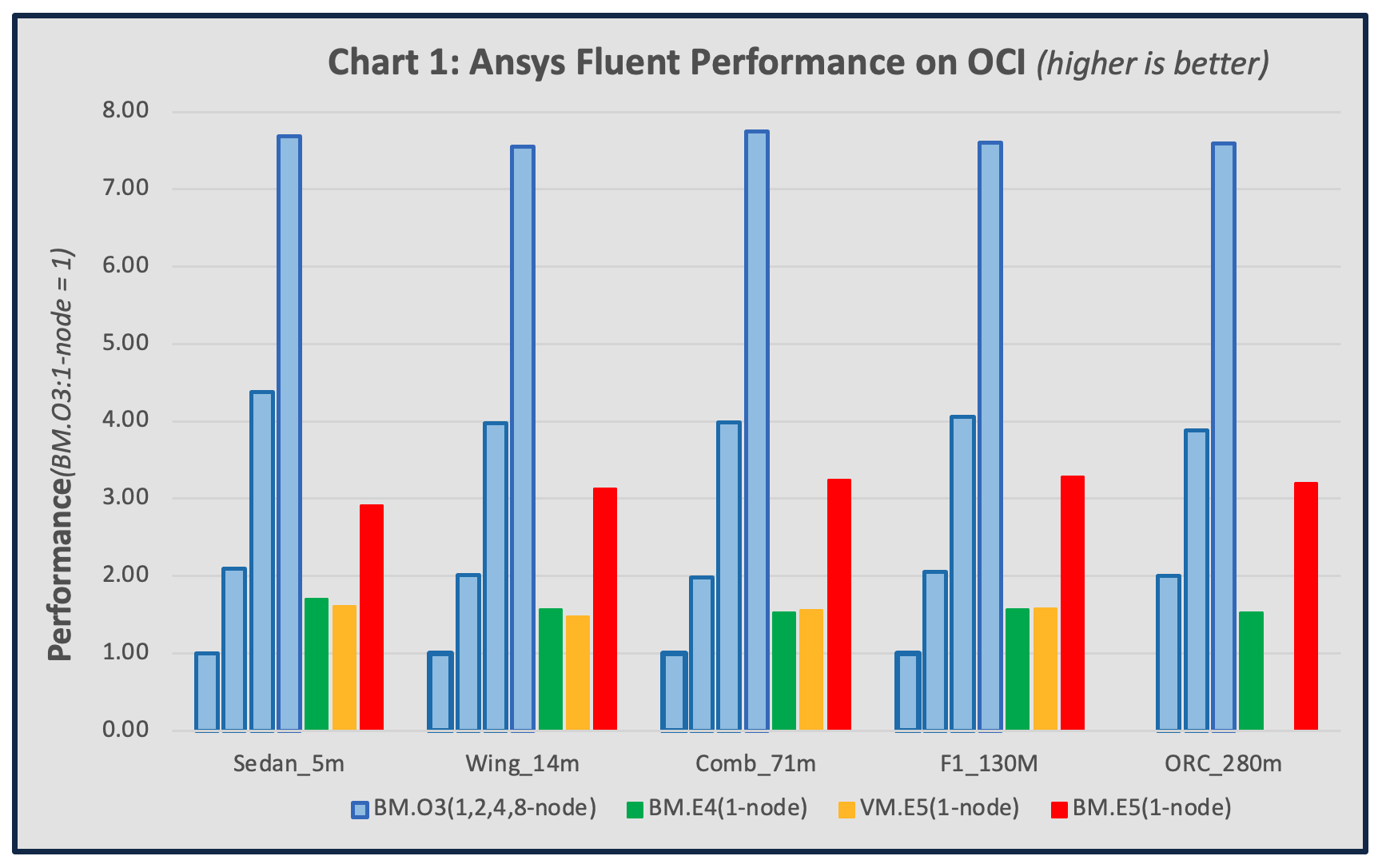
The results were normalized to the performance obtained from a single BM.Optimized3.36 node, abbreviated as BM.O3(1-node) in the legend. The largest case, open_racecar_280m, didn’t fit into the memory of either the single node BM.Optimized3.36 or VM.Standard.E5.Flex configured here, so we took the performance metric of the single-node BM.Optimized3.36 as half of the two-node result.
The BM.Optimized3.36 cluster multinode parallel speedup is nearly linear due to the RDMA network. A single node BM.Standard.E5.192 offers three times the performance of the reference single node BM.Optimized3.36. The VM.Standard.E5.Flex has comparable single-node performance with the BM.Standard.E4.128 using 30% fewer cores, both offering twice the single node performance compared to the BM.Optimized3.36.
The cost of an HPC resource is often of comparable importance with performance for many customers. Chart 2 displays our results in terms of the OCI hardware cost per job, using the single-node BM.Optimized3.36 as reference. In this figure, lower is better.
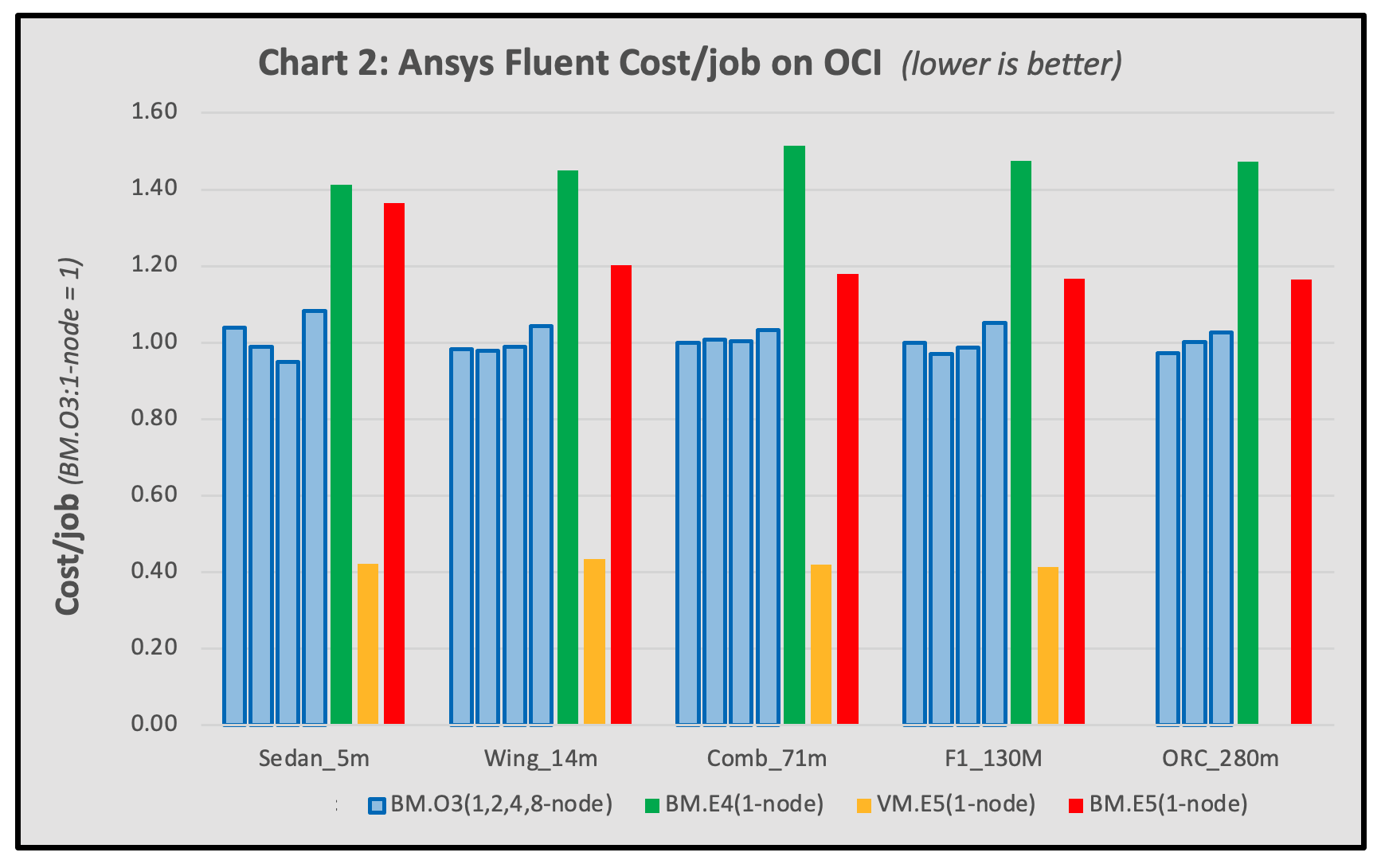
The lowest cost option was used for each node shape (on-demand for bare metal and preemptible for VMs). BM.Standard.E4.128 had the highest cost per job, while the similarly performing VM.Standard.E5.Flex had significantly lower cost than all others. Job cost didn’t vary much for BM.Optimized3.36 when using more nodes per job for the larger model sets. The cost of the BM.Standard.E5.192 was about 20% higher than the BM.Optimized3.36.
Observations
Our results demonstrate that OCI’s different Compute shapes offer different attributes for HPC. While carrying out such varied workloads on a cluster comprised of a single shape might be possible, migrating workloads to the cloud allows for using different compute shapes on different workloads. Figure 1 ranks various attributes for the shapes we tested where the distance from the middle is desirable.
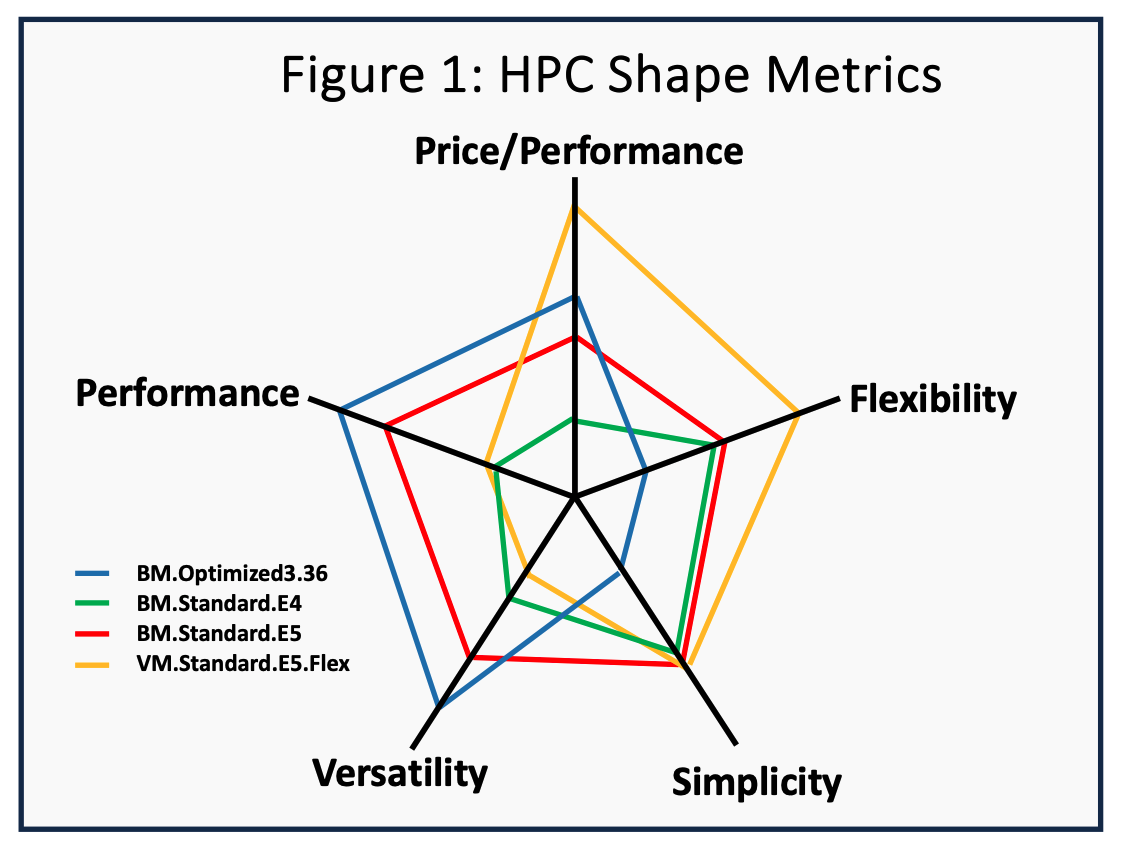
Performance is based on job time, price-performance is based on lowering the total hardware cost per job, versatility is based on the ability to solve various jobs on a single shape, flexibility is based on the ability to quickly add or reduce cluster capacity, and simplicity is based on the ease of cluster use and management. The chart indicates that the preferred compute shape may change depending on the desired job attributes.
Conclusion
HPC analyses are typically either human-driven, where job turnaround time is critical, or algorithm driven, such a design of experiment (DOE), where human intervention isn’t required for each job but the time and cost to run a multitude of jobs matter. Human driven analyses are often complex simulations requiring high performance and cluster versatility, such as memory, I/O, network, naturally maps to the BM.Optimize3.36. For customers with limited HPC IT support, the BM.Standard.E5 offers strong performance and versatility with simpler management compared to a BM.Optimized3.36 cluster. DOE analyses requiring thousands of more modest analyses favor the low-cost VM.Standard.E5.Flex. We encourage you to scope and test your HPC workloads on Oracle Cloud Infrastructure with a 30-day free trial.
