Companies increasingly show interest in expanding beyond their data warehouses and into data lakes. Data lakes offer a great alternative to reduce storage costs for their growing amounts of data. Specifically, many companies want to establish long-term data storage in a lower cost and highly available object storage layer, while moving more relevant data to a data warehouse for quicker access. To further reduce storage costs on the less often accessed data, and to increase performance, this data is often converted into the PARQUET format, which is compressed and reduced in file size.
Oracle Cloud Infrastructure Is Here to Help
Oracle Cloud Infrastructure offers a range of cloud services to help you quickly build this type of solution, including Oracle Functions, Oracle Cloud Infrastructure Data Integration, Oracle Cloud Infrastructure Object Storage, and Oracle Autonomous Data Warehouse.
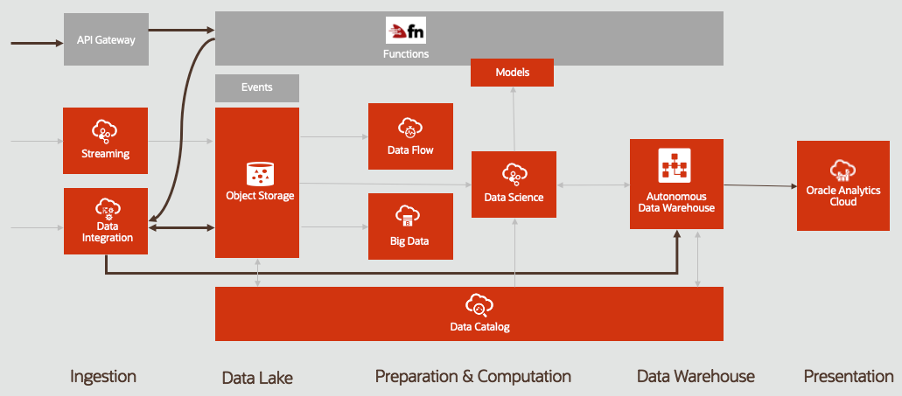
With Data Integration, Oracle provides a serverless extract, transform, and load (ETL) which helps customers quickly move their data into a data warehouse or other target system.
Functions provides a great opportunity to trigger integrations. In my earlier blog, I demonstrated how to convert files into the more efficient PARQUET format using serverless technology. In this blog, I show how to integrate select PARQUET files into the Autonomous Data Warehouse.
Example
Much like other functionality in Oracle Cloud Infrastructure, you can fully code this ETL process, but ETL can be complicated. So, I assume that most users prefer to let the UI do the data mapping and launch the integration programmatically. This process also provides the advantage that you can alter the following code to use it for a different integration. You can find a fully coded example on GitHub.
Build the Data Integration in the UI

The process on how to create a data integration is fully documented and follows a few simple steps:
-
Define the data source and target.
- Source: Object Storage Bucket (reached through the service network or public IP)
- Target: Autonomous Data Warehouse. The connection is simple using the wallet, reached through the service network, private IP, or public IP.
-
Create a project.
-
Create the desired data flow. I use a mapping from a PARQUET file in object storage to a table in my Autonomous Data Warehouse.
-
Create a task for the data flow.
-
Create an application.
-
Publish the task into the application.
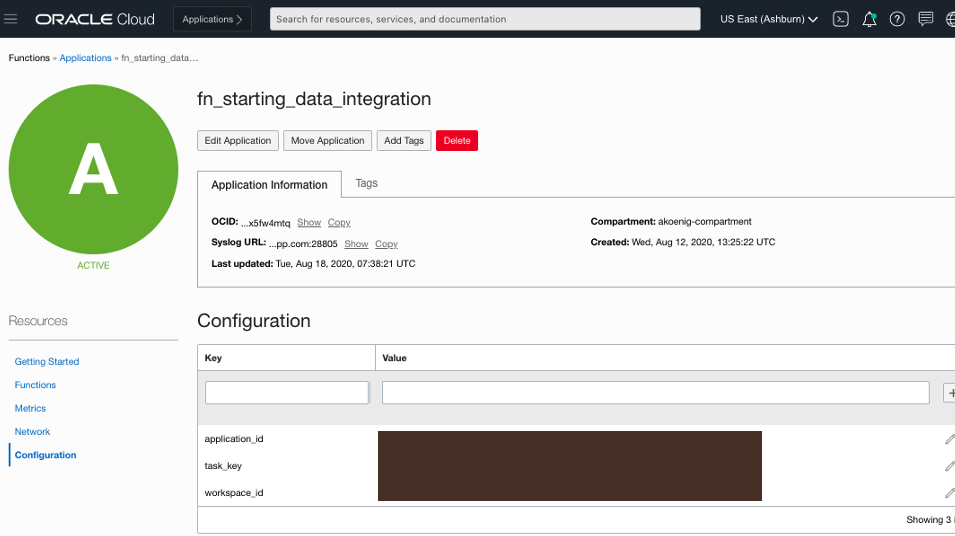
For later use, note the workspace_id, application_id, and task_key.
Create a Serverless Trigger Function for This Integration
Using Functions is ideal, because it’s serverless and can work with a variety of code. For a tutorial on how to write functions with Python, see this blog post.
The overview of Functions describes how to create Functions applications in the UI. When using the cloud shell, you don’t need to install Docker, OCI-CLI, or Fn. It’s enough to create the application in the UI.
In the configuration section of the application, define the variables noted in the previous section.

Deploy the Code to the Function
To deploy the code to the function, open the Cloud Shell. Follow all commands and the “Getting Started” section of your application. Afterward, to copy the required files from my Git repository, use the following input command in the shell:
git clone https://github.com/elex3nda/dataintegration_parquet2adw.git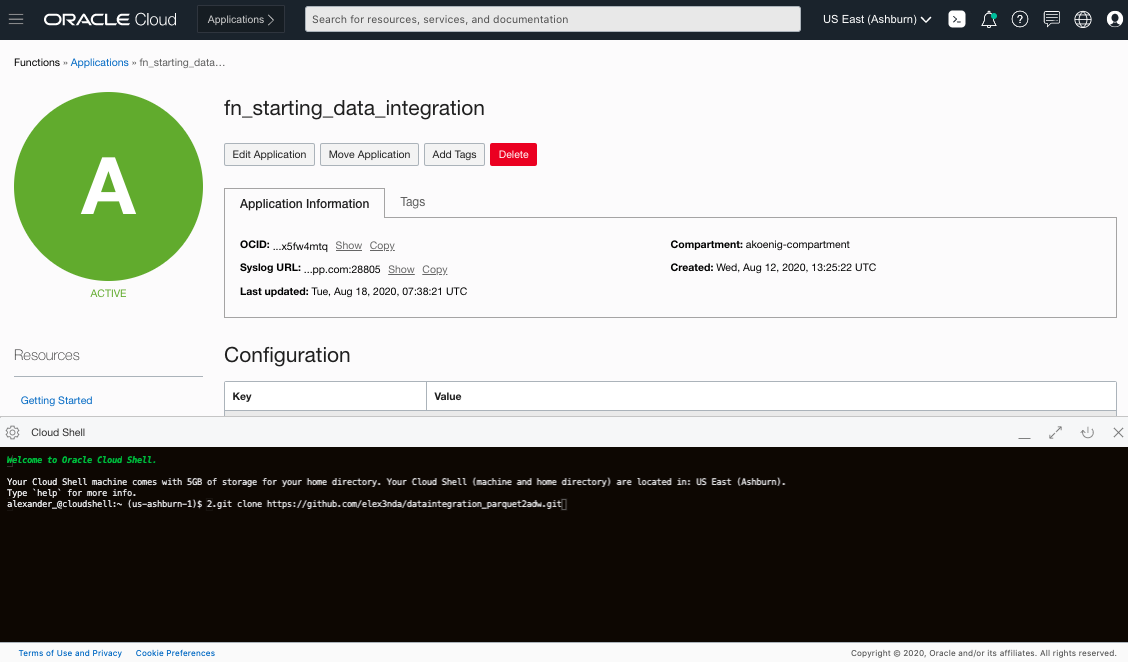
Trigger Through the API Gateway
Oracle Cloud Infrastructure provides an API gateway, which you can easily use to trigger the function. Now, you can start the integration by calling the API from your browser. For example, having a prefix “/trigger” and route path “/start” this would be similar to the following code:
https://<yourgw>.apigateway.us-ashburn-1.oci.customer-oci.com/trigger/startConclusion
Instead of constantly appending data from newly added files from a data lake to your data warehouse, this solution stores rarely used data in low-cost storage, while maintaining quick access to highly used data. This solution is serverless and is only charged when it runs, making it ideal for companies facing fast data growth.
For more data warehouse architectures, visit our architecture center.
