From small startups to global enterprises, organizations of all sizes are harnessing the power of the cloud to streamline processes, enhance collaboration, and adapt swiftly to evolving market demands. But ever wondered how we build a cloud region from scratch? While the concept of cloud regions might be familiar, the behind-the-scenes complexities remains enigmatic.
Building cloud regions isn’t merely about setting up hardware and installing software; it’s a testament to innovation and collaboration. With over two decades of experience in infrastructure management, including three years as the OCI region build engineer, I have personally encountered the formidable obstacles inherent in this pursuit. From laying the hardware foundation to resolving software bootstrap challenges, each step in the process requires meticulous planning and processing.
As Oracle Cloud Infrastructure (OCI) expanded its footprint to new locations, it became evident that we needed a robust automation framework to support our growth and our customers. This realization led us to launch the Touchless Region Build (ToRB) in 2021. ToRB aims to automate and orchestrate the software bootstrap process needed to build the OCI cloud region. This initiative enables the region build process to be not only faster but also more scalable, currently reducing OCI’s region build time by approximately 70%. As a part of this program, we aim to go ‘touchless’ by eliminating human involvement in the software bootstrap process, allowing us to support hundreds of region builds simultaneously.
In this blog post, we explore the intricate process of building cloud regions, delving into the foundational elements and innovative software bootstrap solutions that make a cloud region build possible.
What is a cloud region?
Before we dive into the nitty-gritty of building cloud regions, let’s demystify what exactly a cloud region is.
A cloud region is a data center packed with lots of hardware, all geared towards meeting the demands of customers like you and me. Beneath this seemingly simple description lies a mind-boggling stack of software working tirelessly to provide seamless access to that hardware. When people say “serverless,” it’s all about freeing you from the hassle of managing the operating system, network configuration, runtime environment, and so on. But your applications still need central processing unit (CPU) power, memory, and network access to run on. It’s just that the behind-the-scenes magic of managing all that is hidden away by the genius software stack in the cloud. So, for the cloud itself, there’s no such thing as serverless—it’s all about the clever orchestration for running the customer payload on hardware efficiently, in most cases using multiple layers of virtualization, including OS, hypervisors, and containers.

Figure 1: Sample of a data center
Let’s consider why clouds can offer some unique features, which are difficult to implement using a home-grown data center. The answer is in the value of the hardware and load that each cloud region is designed to handle. The video, First Principles: Using redundancy and recovery to achieve high durability in OCI Object Storage, explains how it works.
Now, let’s dive into the topic of building cloud regions.
Foundations of region build: First mile activities
We all know that building a new cloud region isn’t a simple feat. It involves orchestrating a lot of activities that must align perfectly before we can even begin to bootstrap the software necessary to run the OCI cloud region.
First, we must finalize the ideal location for the new cloud region. When this location is selected, contracts are signed and the data center is ready, awaiting human interaction. The data center engineers set up power cables, install universal power supply (UPS) units, activate generators, and configure cooling systems. They’re also busy installing racks, switches, routers, and cables, but cabling all these hardware components is more challenging than it appears.
Unfortunately, with the current state of technology, automating the foundation—the hardware assembly—of a cloud region is nearly impossible. We don’t have robots smart enough to perform such tasks yet. These installations require the expertise of trained engineers who follow the data center plan meticulously to ensure that fault domains are supported and the blast radius of any potential issues is minimized.
Now that our hardware is perfectly installed, it’s time for the next big step: Bootstrapping the software for running our cloud region! If you thought installing a new OS on your hand-built PC was a chore, imagine bootstrapping hundreds of services that OCI offers on thousands of newly installed servers. Let’s see how we do it at OCI.
Cloud region software installation
Imagine if instead of using OS image, you had to install memory, CPU, network, and disk management subsystems individually. To make things more complex (and closer to reality), those subsystems have interdependencies. The CPU management system needs access to memory and disk to operate and those subsystems need CPU to run their code as well. This scenario mirrors the reality of building any complex, large-scale cloud regions.
Within the OCI cloud ecosystem, we took an early and strategic architectural decision to leverage our own cloud to build our cloud services, i.e. services rely on one another. In a steady state of a running region, this approach works exceptionally well for both OCI and our customers. OCI doesn’t need to support separate stacks for internal and external usage, and customers benefit from the same high quality of service that OCI itself relies on. However, this also creates a unique challenge for building new regions: a web of circular dependencies.
Embracing this challenge has been a positive opportunity for innovation, and before we delve into how we solve the circular dependency problem, let me give you an overview of our high-level design for the Touchless Region Build (ToRB).
Cloud region build orchestration
Each service team creates their deployment automation, navigating through multiphase deployments that encompass multiple components. A classic example is a control plane and data plane, but even within each of these components, there might be multiple subcomponents, including APIs, asynchronous worker, and canaries. Each deployment phase has list of dependencies called cloud features, which should be available before it starts deployment. Each phase might publish one or more features to notify other services, and the orchestration engine that this feature is available in the cloud. Think of it as a giant puzzle, where each piece must fit snugly into place before the next can take its turn in the spotlight.
But here’s where the magic happens: Our orchestration engine constantly monitors the cloud features, managing a seamless flow of deployment phases until all services are successfully deployed. Our goal with touchless region builds? To tackle the following challenges head-on that we faced in previous cloud builds:
- Dependencies between services are self-managed, using automation to a greater extent. To achieve this goal, we developed a deployment static analyzer to identify dependencies and determine the features provided by each piece of deployment automation.
- Human intervention is minimal, with a goal of zero intervention (a touchless process), necessitating an orchestrator to drive the process based on the dependency graph and enabled automation features.
- The process is designed to be repeatable and easily testable to ensure its reliability and effectiveness.

Figure 2: Simplified representation of a region build directed acyclic graph (DAG)
In figure 2, Service 1 doesn’t have any dependencies and can be deployed at the beginning of the region build process. After deployment, it informs the Orchestrator about the availability of two new features in the region. This action then allows Service 2 and Service 3 to proceed with their deployments. As these services are deployed, they activate more features and unlock further services in a chain reaction. This iterative process continues until all services are successfully deployed. In reality, the graph is more complex because it’s a common case for a service to depend on 40–50 features.
This flow works perfectly for services that we install after our core part is done. Now that the overall region build flow is clear, let’s dive into the circular-service dependency problem.
Cloud region OS installation
In OCI, we have a core set of services that almost every other service relies on, either directly or as a transient dependency. Consider the need to run applications somewhere, which means we need to install OS on our hardware servers, often with hypervisors to optimize the resource usage. We also require network setup, identity management, permanent storage like databases, and more. These requirements are common across OCI services.
However, a challenge arises during the setup of a cloud region: None of these essential services are readily available. For example, the Compute service requires storage for asset information, yet the database service isn’t available. Conversely, the database service needs compute resources to function, but they’re not yet provisioned. This interdependency complicates the initial setup process.
To address this issue, the features mentioned in the previous section are set up as dependencies with another attribute, required or not. This setup allows each part of deployment automation to specify the exact list of features, without which the service can’t start at all (required) and a set of features with which the service can start but operates at reduced functionality. Some services use optional features to solve circular dependency issues, while others prefer multiple independent deployment phases run one after another, as illustrated in figure 4.
Breaking these dependency loops isn’t just a job for the orchestrator. It’s a team effort. Take compute and database, for example. Compute needs a database for storing data, but the database needs compute. So, we came up with a brilliant solution: Our virtual bootstrap environment (ViBE).
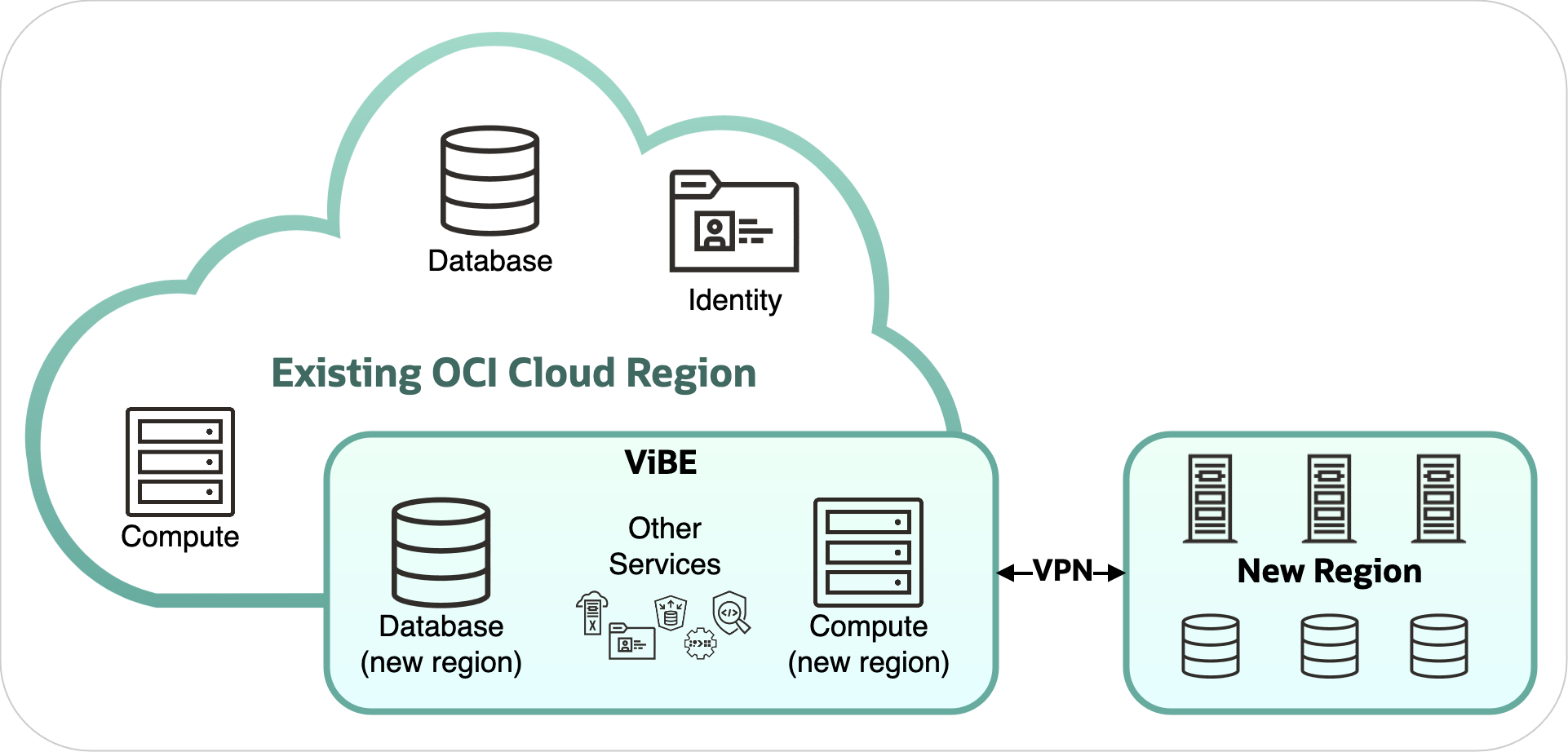
Figure 3: Illustration of the virtual bootstrap environment (ViBE) for deploying services in new region
ViBE stands as a special environment within an existing production region, where all OCI services are readily available to bootstrap new regions. For a certain period, it has access to two contexts – existing hosting region and the region under construction until services are deployed onto real hardware, rendering this environment unnecessary. It’s a temporary lifeline until our new region can stand by itself.
Now, let’s look at the compute and database example. First, you set up the database in ViBE, using services from the existing region. Then, it signals it’s available. Compute then uses ViBE’s database to get things rolling in the new region. Each service helps each other until they’re both running in the new region. When everything’s in place, compute and database are operating at full throttle in the new region, like a well-oiled machine. The real flow is more complex because multiple dependencies must be resolved at the same time, such as Compute and Networking, Compute and Identity, Networking and Identity.
All the deployments are orchestrated through the orchestrator. Services themselves don’t create any resources. The following sequence shows the context in which these calls are made, with feature publications being global and available to all services:
- The database service deploys its instance in ViBE using services from the hosting production region, informing dependencies of its availability through feature publication.
- The Compute service deploys its ViBE version using ViBE Database service and services from hosting region.
- Upon establishing a connection between ViBE and the target region, Compute can begin ingesting real hardware from the target region into its pool. When completed, it publishes the compute_ready feature, signifying that Compute instances in the target region can be created.
- Subsequently, the Database service requests Compute instances in the target region and deploys the service there, notifying other services when completed.
- Data from the target region context might still be in ViBE, requiring migration. After the migration is done, a notification is sent to the Compute ViBE that it should stop using the database in Vibe.
- Compute deploys its service in the target region using migrated database from the Database service. From this point forward, both Database and Compute operate the production version of the service.

Figure 4: Example of a service bootstrap using the virtual bootstrap environment (ViBE) to resolve circular dependency
At the end of this sequence, we have the Compute and Database services running in the target region. The reality is more complex because those circular dependencies exist, not only between Compute and Database, but also between Compute and Networking, Compute and Identity, Database and Identity, Networking and Database, and more. But we can use the same high-level idea: An initial version of the service is deployed in ViBE, with some limited functionality that allows dependencies to proceed to the next step. Then when a connection is established to the target region, the service scales out, with the potential need to migrate the data that was created in ViBE. When in the target region, the service can provide the full set of features.
When the most complex process in deploying core services is done, other services can proceed smoothly. Future circular dependencies, while possible, are less complex to resolve since the target region’s cloud foundation is established. The journey from installing nothing to having core services ready marks the most intricate step.
Conclusion
Touchless region build is a very complex program involving hundreds of services, presenting a myriad of unique issues and challenges. The region build has many moving parts, such as services adjusting their dependencies, providing new features, publishing security updates, the creation of services, and more, making it a complex environment. Despite this complexity, we’re making a good progress. Currently, OCI’s region build time has been reduced by approximately 70%, and our goal is to further reduce it by improving “touchlessness.” These advancements aren’t solely attributable to the region build platform but signify a collaborative effort across OCI, involving over 10,000 developers.
While region build is currently among OCI’s top priorities, helping to ensure the security and reliability of services for existing customers remains paramount. As a testament to the program’s success, Oracle can now offer Dedicated and Alloy regions to customers. However, this journey is far from over, so stay tuned for further developments.
This blog series highlights the new projects, challenges, and problem-solving OCI engineers are facing in the journey to deliver superior cloud products. You can find similar OCI engineering deep dives as part of Behind the Scenes with OCI Engineering series, featuring talented engineers working across Oracle Cloud Infrastructure.
For more information, see the following related articles:
