The AMD Instinct MI300X GPUs are new entrant to the generative AI market and are proving to be strong contender for customers looking to run larger sized LLM model inference and training workloads. As part of Oracle Cloud Infrastructure’s (OCI) ongoing efforts to integrate innovative technologies, OCI has announced intentions to bring the AMD Instinct MI300X GPU bare metal offering . As part of the new product launch, we had the privilege of first access to MI300X GPUs in our preproduction regions. Our exploration of MI300X hardware was geared towards understanding its capability for large language model (LLM) serving online scenario with real workload and parameters in mind, focusing more on the development and validation of the AMD ROCm Software stack.
By diligently working with AMD technical support and engineering, this process allowed us to tap into the notable features of the AMD Instinct MI300X GPU, such as its 192-GB HBM3 and 5.2-TB/s memory bandwidth, significantly surpassing its predecessors. This exploration wasn’t just about benchmarking but also about aligning the hardware’s capabilities with our LLM serving requirements to keep it close to real-world workloads, such as pushing maximum throughput with 256 batch sizes.
The results and experiences shared in this blog post are based on preliminary software and hardware configurations, which are still in the process of being optimized for production.
Performance insights
In the experiments, our initial focus was on exploring the MI300X capabilities for latency-sensitive applications, also maximizing the throughput efficiency per machine on a single node with eight GPUs. Our benchmarking exercise produced the following results.
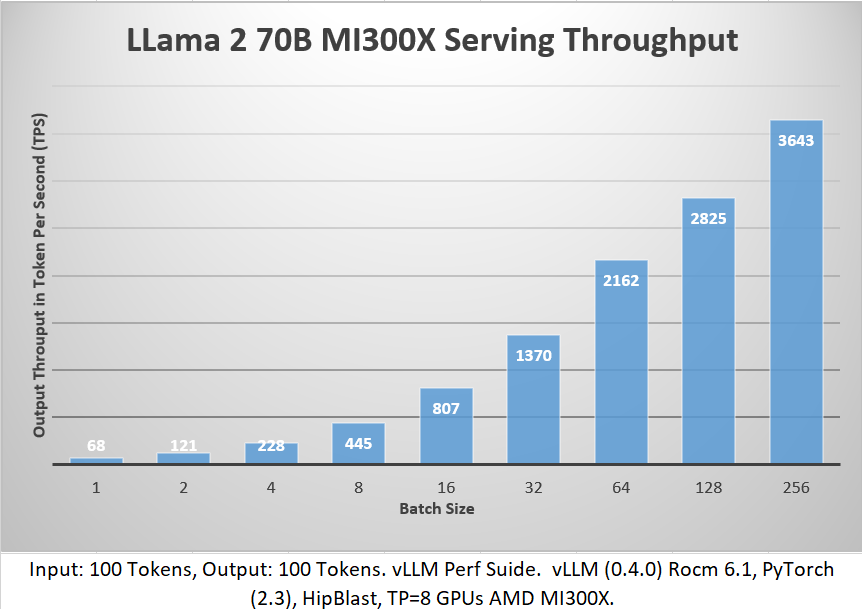
The time to first token latency was within 65 milliseconds and average latency of 1.5 seconds for batch size 1. As the batch size increased, the hardware was able to scale linearly and generate a maximum of 3643 token across concurrent 256 user requests (batches). Throughput in token per second (TPS) is a common measure of how many tokens a node can produce across all requests it’s handling in parallel, with 8 (Tensor Parallelism) GPUs assigned per inference serving through vLLM.
In our other scenario, we were also able to achieve 1.6 second end-to-end latency when experimenting with 2,048 input tokens and 128 output tokens with batch size = 1. In other words, we are able to replicate the record performance reported by AMD during the December 2023 launch. These findings underscore the potential of MI300X in serving latency-optimal use cases with long context length prompts efficiently even with larger batch sizes and ability to fit largest LLM models in a single node.
Next Steps
As OCI works towards making MI300X publicly available in the coming months, we plan to share updated results of Llama 3 70B inference with vLLM, PyTorch Performance, multi-node experiments while expanding the runs to other popular LLM models and use cases to finetuning. With an ongoing collaboration with AMD software team, we look forward to confirming real world customer scenarios as part of new product release to make it customer ready.
If you’re interested in getting access to the AMD Instinct MI300X GPU bare metal Oracle Cloud Infrastructure Compute offerings, get in touch with your Oracle sales representative or Kyle White, VP of AI infrastructure sales at kyle.b.white@oracle.com.


