Benchmarks are a means of evaluating the relative capabilities and performance of hardware. In machine learning (ML) and high-performance computing (HPC), benchmarks are essential to understand the efficiency in running workloads on compute infrastructure. This benchmark gives us a look at the power of the NVIDIA GH200 Grace Hopper Superchip running on Oracle Cloud Infrastructure (OCI). While utterly obscure to anyone who isn’t up-to-date on the latest GPU revolution, this blog post explains to layfolk and decision-makers what’s happening from a computer science standpoint—and results from our point of view—at OCI.
NVIDIA GH200 systems
The NVIDIA GH200 Superchip is built for the new era of accelerated computing and generative AI. It is the first architecture that brings together the groundbreaking performance of the NVIDIA Hopper GPU with the versatility of the NVIDIA Grace™ CPU, connected with a high bandwidth and memory coherent NVIDIA NVLink Chip-2-Chip (C2C)® interconnect into a single Superchip. Currently, NVIDIA GH200 provides the best performance across CPU, GPU, or memory-intensive applications. These systems are easy to deploy and scale out in a 1 CPU:1 GPU node, and are extremely simple to manage and schedule for HPC, enterprise, and cloud. These systems provide superior performance and total cost of ownership (TCO) for diverse workloads and maximize data center utilization and power efficiency.

Background of the GH200 benchmarking for AI inference
Our process consisted of benchmarking using MLPerf Inference v4.0, the framework from MLCommons, on two hardware setups: an 8-NVIDIA H100 GPU server and a single GH200 Superchip . Our benchmarks closely fit NVIDIA’s own performance figures for each workload , indicating consistency.
We also ran the ResNet50 model on the GH200 with the NVIDIA Data Loading Library (DALI). Residual Network 50 (ResNet50) is a 50-layer convolutional neural network considered to be a popular image-classification model for common computer vision tasks. The library’s ability to accelerate data loading processes, including augmentation of data, helped show how the GH200 can optimize workflows using large datasets and complex neural network models.
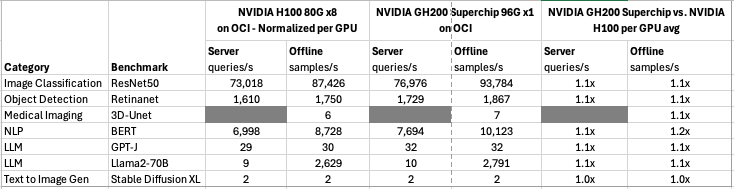
A chart comparing the benchmarks for image classification, object detection, medical imaging, speech-to-text, natural language processing, large language models, and text-to-image generation across NVIDIA H100 80G and NVIDIA GH200 96G on OCI. Both deliver strong performance across each workload.
MNIST and NVIDIA TensorRT-LLM
We also used the MNIST dataset with a performance benchmark on the NVIDIA GH200 Superchip. MNIST is a standard ML dataset, consisting of handwritten digits (0–9), which are widely used for training and testing various image processing systems. We developed a specific inference network prepared using NVIDIA TensorRT, and a high-performance deep learning inference library. We optimized this network to the NVIDIA GH200 Superchip. This setup represents typical ML workloads on the NVIDIA GH200 for serving inference with maximum efficiency for ML application s . NVIDIA GH200 processed about 29,253 images per second, while the NVIDIA H100, averaged to 1 GPU, was able to churn through about 19,200 images per second, highlighting the benefit of NVIDIA NVLink-C2C, which is responsible for this speedup.
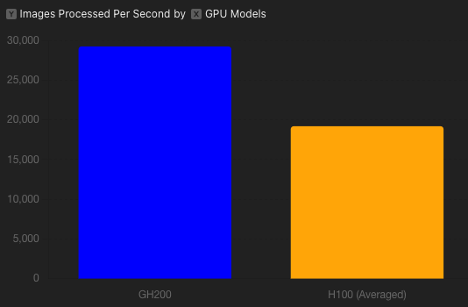
A bar chart comparing images processed per second for NVIDIA GH200 Grace Hopper Superchip and NVIDIA H100 Tensor Core GPU (Normalized per GPU)
Various precision benchmarking using Oracle Custom Workloads
The bar charts also provided test results of different mode s of precision: FP8, INT8, and FP32, which represent an important aspect of current training and inference of ML models. Our test results further prove that NVIDIA GH200’s performance was able to meet the same accuracy level of the NVIDIA benchmark and can be the optimal solution for ML models of high computational resources utilization with diverse precision requirement s .

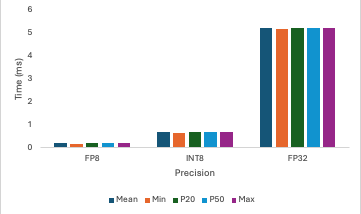
GPU and CPU stream performance for FP8, INT8, and FP32
Further, Oracle ran some very basic linear algebra operations and Fast Fourier Transform (FFT) on the NVIDIA GH200 . These tests provide a good window on the raw computational power of the GPU, and its efficiency in running common basic scientific and engineering math operations.
For example, Oracle’s HPC benchmarking of NVIDIA GH200 Superchip points toward a performance-driven future for the new hardware. The fact that the NVIDIA GH200 benchmarks from Oracle closely track results published by NVIDIA for both ML and more traditional data processing tasks points to reliable high-performance acceleration using this new hardware.
Conclusion
Moving forward, the tech community can anticipate having more detailed and thorough benchmarks to improve informed hardware purchasing decisions about new and existing ML systems. They can see first-hand a growing ecosystem for making these kinds of AI machines not only possible, but also business as usual.
We’ll keep you apprised of key updates and deep dives as Oracle releases further enhancements and optimizations to NVIDIA GH200 .
Find out more about Oracle Cloud Infrastructure AI infrastructure and speak to an AI expert today about getting access to NVIDIA GH200 .


