Deep learning models are getting bigger with billions of parameters trained on more data and for longer periods. To facilitate these massive training workloads, customers need hundreds of GPUs, meaning the infrastructure scales beyond a single Compute instance. An Oracle Cloud Infrastructure (OCI) Compute instance BM.GPU4.8 comes with eight NVIDIA A100 Tensor Core GPUs. For training jobs that require 128 GPU, it translates to a cluster of 16 BM.GPU4.8 instances.
Parallelism and inter-GPU communications
When a training model grows beyond a single GPU, model parallelism and data parallelism are popular techniques for distributed deep learning, introducing the need for high-throughput, low-latency GPU-to-GPU communication. Inter-GPU networking within the same instance usually isn’t an issue, but it becomes more challenging when model training scales out to multinode, where GPU on one compute node needs to talk directly to another GPU on a different compute node.
Remote direct memory access (RDMA) allows one computer to access the memory data of another over the network without involving CPUs. With RDMA, network adapters can directly read from and write to remote GPU memory. It results in great performance improvements by reducing latency and CPU overheads.
Scaling with OCI cluster networking
RDMA over converged ethernet (RoCE) is a network protocol that supports transporting RDMA packets over standard ethernet. Built on RoCE, OCI has engineered a unique GPU Compute cluster offering with high-throughput and low-latency RDMA support. The solution is comprised of NVIDIA GPU instances, Mellanox ConnectX network adapters, and a dedicated spine-leaf network fabric. Each Mellanox has two 100-Gbps ports transmitting data over the non-blocking backbone fabric, resulting in near line rate (above 185 GB per second) aggregated bandwidth for each BM4.8 instance.
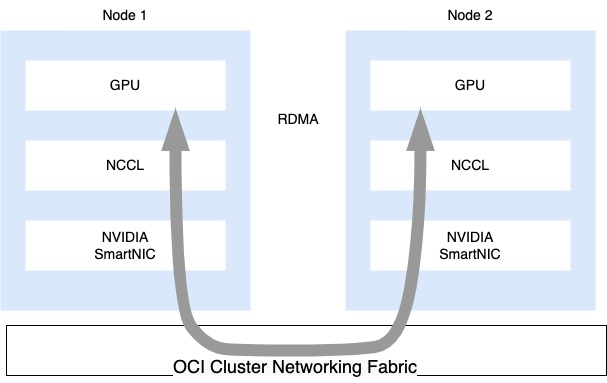
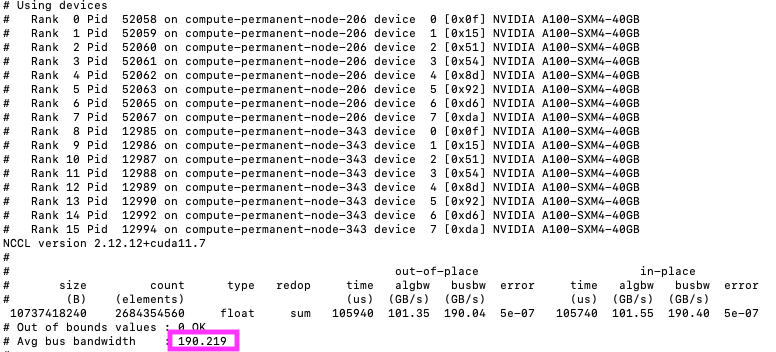
NVIDIA Collective Communication Library (NCCL) provides multiGPU and multinode inter-GPU communication primitives, optimized for NVIDIA GPUs within a node and over Mellanox Network across nodes. NCCL allows CUDA applications and deep learning frameworks to implement parallelism across GPUs without writing complicated custom codes. You can run NCCL tests to check performance and correctness of NCCL operations. One of the metrics that the NCCL test captures is bus bandwidth, which ensures that NCCL runs at maximum hardware speed. The following image shows the result of 190 GB per second for the two nodes (BM4.8) cluster in the lab.
Conclusion
Combining NVIDIA NCCL software stack, OCI cluster networking hardware stack, and OCI NVIDIA GPU instance family, you can essentially build a giant GPU machine in the cloud to deliver the compute power for the most demanding deep learning training workload.
For more information, see the following resources:
