Natural language processing (NLP) is at the mixed discipline intersecting with linguistics, computer science, artificial intelligence, and machine learning. Common applications of NLP and large language models (LLMs) include the following examples:
-
Spam detection
-
Virtual assistants
-
Chatbots
-
Machine translation
-
Sentiment analysis (Social media)
-
Text summarization
-
Semantic search
The philosophy of NLP is simple: imbue an AI with the same linguistics abilities humans use to interact with one another. In the 2010s, with the availability of deep learning systems at scale, NLP entered a new era of exponential growth with LLMs. GPT-3 from Open AI is the first cutting-edge LLM providing pretrained models accessible through APIs for business applications.
In this blog, keeping GPT-3 as the context, we delve into why Oracle Cloud Infrastructure (OCI), offering NVIDIA GPU shapes, is the platform of choice for LLM developers providing similar or superior services like that of Open AI’s GPT-3.
Large language models
Language models are getting bigger and better with the generic goal of assigning a probability to a sequence of words in a specific language text. These models are key components in applications using natural language processing. LLMs are developed to carry out generic NLP tasks like text generation, summarization, and classifications. Before GPT-3, specific models used various machine learning algorithms to carry out a specific task. LLMs like GPT-3 with hundred billion plus parameters require large data sets for training AI algorithms.
Parameters and LLM performance are intrinsically related. For a high-performance model, a specific set of variables are trained to determine the ideal parameters. The parameter values are incorporated within the model through successive training runs. In his book Outliers, Malcolm Gladwell came up with the theory that to become an expert in any field, practicing the relevant skills for 10,000 hours is sufficient. Keeping in line with this theory, a pre-trained model (like GPT-3) is the first skill that is developed which in turn can help acquire successive skills faster. This would eventually lead to exponential returns.
Datasets
As mentioned, training LLMs requires large datasets. The five common datasets are Common Crawl, WebText2, Books 1, Books 2, and Wikipedia. This body includes more than a trillion words. For example, GPT-3 contains the following top ten language datasets:
| Rank |
Language |
Number of documents |
| 1 |
English |
235,987,420 |
| 2 |
German |
3,014,597 |
| 3 |
French |
2,568,341 |
| 4 |
Portuguese |
1,608,428 |
| 5 |
Italian |
1,456,350 |
| 6 |
Spanish |
1,284,045 |
| 7 |
Dutch |
934,788 |
| 8 |
Polish |
632,959 |
| 9 |
Japanese |
616,582 |
| 10 |
Danish |
396,477 |
The larger the training corpus of languages, the better the performance and accuracy of LLMs. These LLMs can run many diverse tasks.
Architecture of an LLM
The basis of LLMs is deep neural network, a circuit of neurons processing information in tandems. The model that revolutionized NLP is the Transformer, which can process an entire sequence of text instead of one word at a time like pre-Transformer NLP algorithms. The idea of a transformer model was introduced in a 2017 paper:
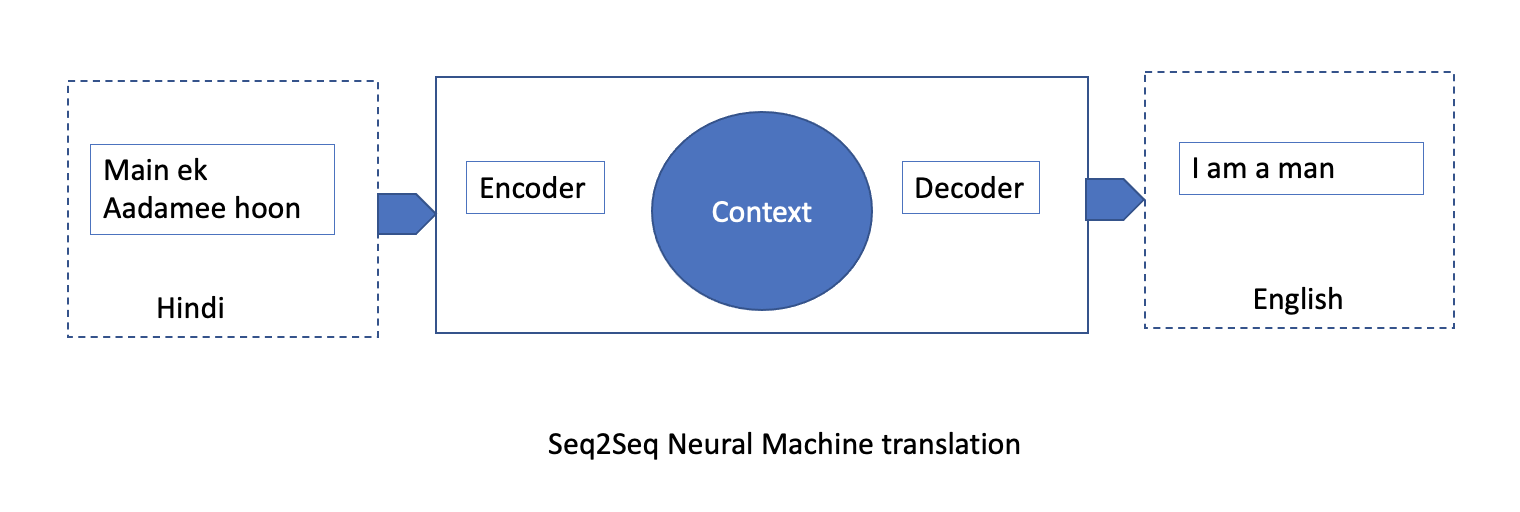
The foundation of a Transformer is sequence-to-sequence (seq2Seq) architecture, which can transform entire elements of a sequence into another sequence. For example, words in a sentence can be treated as elements of a particular sequence (the sentence). Seq2Seq models are comprised of two components: encoder and decoder. These models are good translators. The processing model is that the encoder translates a language like Hindi into Spanish and passes the context (Spanish translation) to the decoder, which in turn converts Spanish to English. In this case, Spanish acts as the Rosetta Stone.
The Sec2Sec architecture is used by LLM like T5 using both encoder and decoder. There other models use a decoder or an encoder only architecture as well.
Attention mechanism
One of the important underlying concepts of the transformer model is attention mechanism. This technique imitates cognitive attention. It scans the entire input sequence element by element and uses probability theory to identify important pieces of the sequence after each step. For example, “The dog climbed on the sofa after it ate the food.” What does ‘it’ represent, the dog or the sofa? Attention is when the model strongly associates “it” with the dog and not the sofa.
If we take this concept of attention in our encoder-decoder construct, the encoder passes the important semantic key words of the sentence with the translation. The decoder infers which parts of the sentence are important using the combination of the keywords and the translation and gets the sentence context right.
The transformer model has two types of attention: Self-attention, which is the connection between words within a sentence, and encoder-decoder attention, which is the connection between words from the source sentence to words from the target sentence.
Larger architectures and more data are beneficial to transformer models. The results are improved by training on large datasets and fine-tuning for specific tasks. So, the underlying compute, storage, and network infrastructure becomes critical.
OCI differentiation
Unlike other cloud providers, the unique architecture of OCI cluster networks hosting bare metal NVIDIA A100 Tensor Core GPUs using RoCE v2 offers a high-bandwidth, low-latency options across multinode multi-GPU instances. So why are NVIDIA GPUs more performant on OCI? A Ferrari has a differentiated performance when it’s driven on a country road versus on a racetrack. You can think about OCI cluster network infrastructure, off-box virtualization, and other cloud infrastructure level innovations as the racetrack.
The architecture is simple, more stable, and better performing, resulting in lower cost per GPU hour. This configuration gives a unique economic advantage to the end customer without sacrificing performance.
The key component of the architecture is the cluster network supporting RDMA over ethernet (RoCE v2 protocol). For this setup, I have used this high-bandwidth, low-latency RDMA cluster network consisting of 64 GPU bare metal shapes (8 GPUs per shape) connected directly to an RDMA switch. There is about 1.5 µs latency between bare metal shapes . It has no hypervisor, no virtualization, and no jitter. The inter-node bandwidth is 1600Gbps, delivered through 8, 200Gbps RDMA connections.
For a visual example, see the following diagram, courtesy of Seshadri Dehalisan and Joanne Lei.
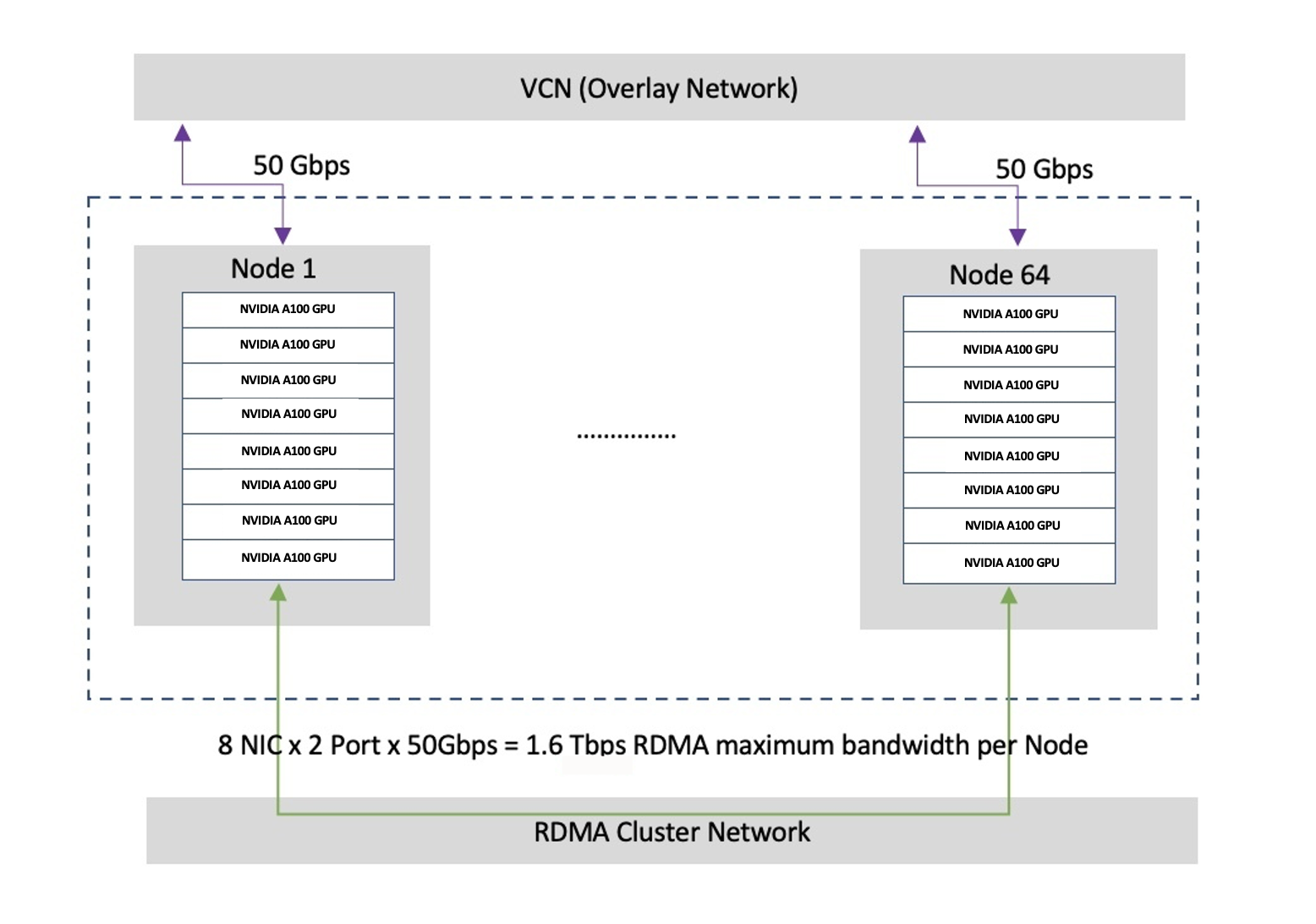
The flagship of the bare metal GPU series is the BM.GPU.GM4.8, as presented on the Oracle Cloud Console or provisioned using API or software development kits (SDKs). BM.GPU.GM4.8 features eight NVIDIA A100 Tensor Core GPUs with 80 GB of memory each, all interconnected by NVIDIA NVLink technology. This GPU has twice the amount of GPU memory and 30-percent faster memory bandwidth compared to the A100 40GBGPUs, which is ideal as AI models continue to grow in size. The CPU on board doubles the physical CPU cores to 8×64 physical cores of AMD Milan processors supported by 2,048 GB of RAM and 27.2 TB of NVMe storage to support model checkpointing and nearby fast storage for large multimodal models.
| BM.GPU.GM4.8 (OCI GM4 instance) | Components |
|---|---|
| Number of GPUs | 8 |
| GPU memory | 640 GB |
| GPU memory bandwidth | 8×2 TB/s |
| CPU | 8×64 cores AMD Milan |
| System memory | 2 TB DDR4 |
| Storage | 4×6.8 TB NVMe |
| Virtual cloud network (VCN) network interface card (NIC) | 50 Gbps |
| Cluster NICs | 8x2x100 Gbps |
With these enhancements from our first generation of NVIDIA A100 40GB Tensor Core GPU customers can expect to see performance improvements for any model that can’t fit entirely onto the memory of a single A100 40GB GPU. It has the following capabilities:
-
Up to 3X higher AI training for LLMs, deep learning recommendation models (DLRM), and computer vision (CV)
-
Up to 1.25X higher AI inference for workloads, such as real-time conversational AI, manufacturing inspection, and autonomous driving.
-
Up to 1.8X higher performance on scientific HPC applications
-
Up 2X faster delivered insights on big data analytics
Clusters in this shape are key to accelerating time-to-market (TTM) for customers training NLP, computer vision, and multimodal models. For more information, see our customer earnings highlights: NLP startup Adept.
Conclusion
Running GPT-3 for large language models has the following key benefits:
-
Each node has a consistent throughput of 1,480 Gbps with 1,520 Gbps across 1,600 Gbps internode RDMA connectivity (validated using NCCL benchmarks)
-
Clusters are ideally suited for large language models with more than 200 billion parameters, computer vision models for autonomous driving, and other deep learning model trainings
-
Data science machine image installed with deep learning frameworks is available for quick start.
-
Clustered GPUs optimized for single-region distributed LLM training and multi-region SWARM trainings, including edge cases
In the next few blogs, we will discuss other large language models, like HuggingFace Bloom, and some benchmarks across infrastructure, training, and inferences.
Call to Action
We have published a preconfigured NVIDIA GPU enabled Data Science Image on Oracle Cloud Marketplace. Here is the link to the marketplace and documentation. Please try it out with any NVIDIA GPU shapes and drop us an email with questions, comments or results. Here are some of the blogs with additional backgound information:
1. https://blogs.oracle.com/cloud-infrastructure/post/oracle-announces-nvidia-a100-tensor-core-gpu-availability-startup-program-collaboration-data-science-vms-and-more
2. https://blogs.oracle.com/cloud-infrastructure/post/oracle-partners-with-nvidia-to-solve-the-largest-ai-and-nlp-models
3. https://blogs.oracle.com/cloud-infrastructure/post/accelerate-distributed-deep-learning-with-oci
4. https://blogs.oracle.com/cloud-infrastructure/post/machine-learning-at-scale-with-oci-and-kubeflow
