Consulting Member of Technical Staff, Cloud Security and Identity
The mission: Make disaster recovery time much shorter
There’s a popular saying: Every Second Counts. In the Cloud Compute business it’s really: Every Microsecond Counts. With this mantra always at top-of-mind, I have worked on a range of projects at Oracle. I have spelunked the chaotic world of the Windows Kernel, quickly untangling driver call paths to find a one-line race-condition fix. I have also pushed a hyperscale, zero-downtime upgrade pipeline where raw speed was a top concern. My job is all about improving our timing.
When I joined the OCI Key Management Service (KMS), I was asked to put my familiar mantra into practice once more: Make disaster recovery time much shorter. As a tier-0 service, KMS sits at the root of OCI’s security chain. It’s a large network of distributed systems that control all encryption keys used to protect enterprise data. So… stakes are high, and interdependencies are plentiful—No pressure! By running the service under live fire (midnight pages, cascading faults, the works), I was able to discover failure modes not found in textbooks. These discoveries prompted us to take apart our replication layer and wire in a new snapshot pipeline without compromising our sub -10ms latency standard and integrate fast failover logic. This new installation cut disaster-recovery time down from days to a mere fifteen minutes. This blog details this snapshot work that saved considerable time for us and our customers. We’ll cover the edge-cases, trade-offs, and fixes that let us restore the fleet in minutes.
So, what’s KMS?
Every cloud workload depends on encryption, and encryption depends on keys. KMS is the service that keeps those keys out of harm’s way.
HSMs meet government standards like FIPS 140‑2. They’re great at security, but they’re small, pricey, and a bit fussy: unplug one at the wrong time and it wipes itself.
What does “Tier 0” mean?
Lots of other OCI services (Block Storage, Kubernetes, Object Storage, …) encrypt their data with keys held by KMS. If KMS goes down, the stack above it has a bad day—so we have to hit very high bars for uptime and latency.
The Fun Parts
Because KMS can’t lean on higher‑level services, we’ve had to roll our own:
replication across nodes
write‑behind logs
snapshots and fast restore
caching that never leaks keys
One tricky problem was asynchronous snapshots of HSMs. Early versions took hours to restore after a failure. After a rethink, we got that down to minutes. The rest of this post walks through what went wrong, what we changed, and what it looks like today.
The HSM Security Model (and Why It Matters)
Before we get into snapshot mechanics, it helps to know how an HSM keeps keys safe—even while multiple customers share the same hardware.
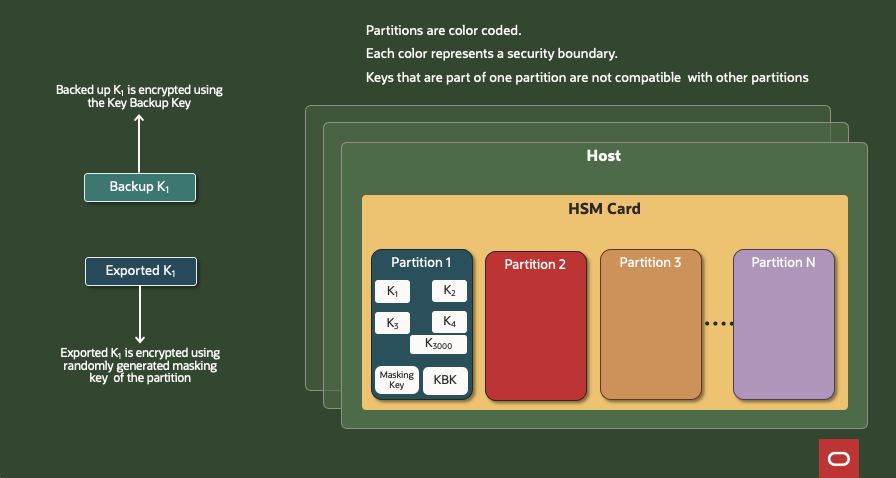
Partitions: one device, many tenants
Think of an HSM as an apartment building. Every tenant (customer) gets a partition—a walled‑off space with its own certificate and Backup Key (KBK).
Keys generated or imported into a partition never leave the device in plaintext.
Each key is tied to its partition for life.
Two ways to move keys off the box
Keys occasionally need to travel—for user backups or for KMS‑driven replication. The HSM supports two export paths:
Export Path
Who uses it
How it’s encrypted
When it’s used
Backup Key
Customer
Key Backup Key (KBK). It’s a key that is derived from Vendor Key and Adapter Owner Key
User Backups
ExportMaskedObject
OCI KMS
Masking Key (random AES key created with the partition, never exportable)
Internal replication and snapshots
For replication to another HSM, the destination device must already know the exact partition settings—including the Masking Key.
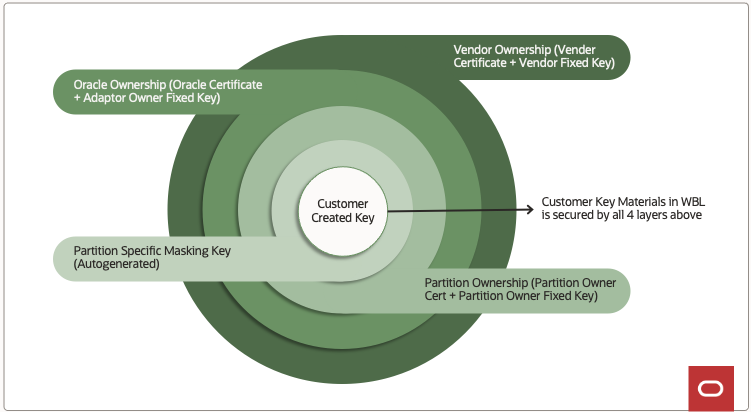
Layered ownership—how we keep rogue devices out
Partition ownership – customer certificate + KBK
Card (Adapter) ownership – OCI installs its certificate + KBK when the card is commissioned. Any key leaving a partition is re‑encrypted under this OCI KBK.
Vendor ownership – the manufacturer (e.g., Marvell) burns in its own certificate + KBK at the factory.
Figure 1: Concentric circle diagram with HSM security layers.
A BackupKey operation derives its final wrap key from all three layers. The key can be unwrapped only on a card where vendor and adapter ownership match exactly.
Snapshot or replication succeeds only if the target card carries the same Vendor and Adapter certificates.
Each OCI realm uses a different Adapter certificate set, preventing keys from crossing realm boundaries.
All ownership certificates and KBKs are loaded by a small, audited team and stored in physical safes.
Why this matters for snapshots
Because snapshots use ExportMaskedObject, they inherit the same three‑layer protection:
The key blobs inside a snapshot are useless on an untrusted card.
Even if the file is copied elsewhere, decrypting the payload still requires the matching HSM hardware and certificates.
In short, the layered ownership model lets OCI replicate and restore keys across devices (and data centers) without lowering the security bar for customer data.
Figure 2: OCI layered ownership model to replicate and restore keys safely.
Why KMS Uses a Write‑Behind Log (WBL) Instead of a Write‑Ahead Log (WAL)
Most database and storage systems lean on a Write‑Ahead Log (WAL): record the change first, then apply it to the main store. It’s a proven pattern for durability. OCI Key Management Service (KMS) flips that around and uses a Write‑Behind Log (WBL)—and the reason is security.
WAL vs. WBL in an HSM world
WAL → “log first, write later.” Works great when the system itself can see the plaintext data.
KMS → keys are born inside Hardware Security Modules (HSMs) and never leave them unencrypted. The HSM must finish the write (generate the key) before anything can be logged outside. That pushes us into a WBL model—“write first, log later.”
The flow in practice:
Key create request A customer asks for a new key. KMS picks one HSM in the cluster.
Key generation inside the HSM The device creates the key and immediately wraps it with a partition‑specific Masking Key.
Write‑behind log entry The encrypted key blob plus its metadata (ID, algorithm, etc.) is appended to the WBL.
Replication Other HSMs import the masked object from the log, keeping every replica in sync.
Because the blob is already encrypted when it hits the WBL, the log never holds plaintext key material. The security boundary stays intact.
Extra step: partition configuration first
Key blobs are useless if the destination HSM doesn’t share the same partition settings (owner certificate, Masking Key, KBK).
So KMS always:
replicates/creates the partition on peer HSMs, then
replays key entries.
That order guarantees each replica can unwrap the masked object without exposing the key.
Bottom line: WBL is designed to let KMS meet the strict “keys never leave the HSM unprotected” rule while still giving us an auditable, replayable log for durability and recovery.
Write‑Behind Log (WBL): How KMS Keeps Partitions in Sync
The Write‑Behind Log does two jobs:
Replicates partition configs so every HSM in the cluster knows the same “layout.”
Stores encrypted key blobs plus metadata for replay and recovery.
Partition spin‑up
A customer asks for a new partition.
KMS picks one HSM at random.
That HSM creates the partition and exports the config (already encrypted).
The config and its metadata—partition ID, CPU cores, storage quota, etc.—are appended to the WBL.
Why the WBL is trustworthy
Chained checksums – Each log entry includes a checksum that uses the previous entry’s checksum as a seed. Tamper with anything and the chain breaks.
HMAC on key blobs – Every encrypted key payload also carries an HMAC. The HMAC key lives only inside the partition, never leaves the device.
Together, the chain and the HMACs make the log immutable and verifiable—no silent corruption, no unnoticed edits.
So, the WBL is more than a change log; it’s a cryptographically protected ledger that lets OCI KMS replicate partitions and keys safely across all HSMs in the fleet.
The Concurrency Headache: Direct HSM Backups in a Distributed Cluster
Before snapshots ever come into play, we have to talk about durability in a distributed system. When any node writes data, the write isn’t considered “safe” until a quorum (more than half of the nodes) has the same data. If that quorum can’t be reached, the write is rolled back—no partial truth allowed.
OCI KMS follows that rule. A key‑create request can land on any node, but the key is officially born only after its record hits the Write‑Behind Log (WBL) and propagates to a quorum.
First try snapshot straight from the HSM
Our early backup flow looked like this:
Snapshot manager writes a “take snapshot” entry into the WBL.
Each node sees that entry, locks its local HSM (no new keys!), and dumps all masked keys to a blob.
All blobs are merged into a snapshot.
Sounds reasonable—until reality hits. Consider a key‑create that fires while a snapshot is in progress:
Concurrency Issue with Snapshot
T0 node‑1: start snapshot
T1 node‑2: create‑key
T2 node‑1: HSM dump done
T3 node‑2: quorum commit
Now the cluster has a snapshot that doesn’t know about the new key created on node 2. In practice we saw two patterns:
Key create finishes after snapshot → fine.
Key create finishes before snapshot → inconsistent snapshot.
Quick patch: hash‑and‑vote
We tried a checksum vote:
Each node hashes its dump.
Snapshop is “good” only if all hashes match at that LSN.
If they don’t match, throw the snapshot away.
Result: On a busy region we collided a lot. Snapshots could fail for days, and any restore meant replaying the whole WBL from the last good snapshot—hours or days of churn.
Time for a different strategy
The constant hash mismatches were a clear bottleneck. We needed a way to capture a consistent view without blocking key creation or relying on unanimous hashes. The rest of this post digs into the solution we ended up with—moving snapshot logic into the WBL itself, tightening integrity checks, and cutting recovery time from days to minutes.
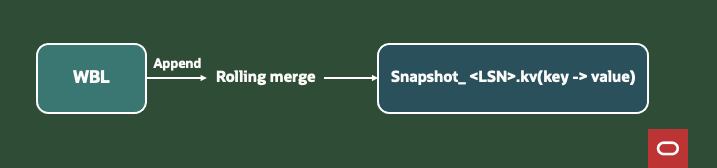
Rolling Snapshots — How Create, Update, and Delete Settle into One “Max LSN” File
We don’t freeze the cluster at a single log‑sequence number (LSN).
Instead, every node compacts its local Write‑Behind Log (WBL) continuously and produces an indexed key‑value file that represents its view up to maxLSN_node.
What goes into the log?
Operation
WBL Record
Effect during compaction
Create
{key‑id, blob, LSN}
Becomes the current value for key‑id
Update
{key‑id, new‑blob, LSN}
Replaces the previous value for key‑id
Delete
{key‑id, tombstone=true, LSN}
Marks key‑id as absent going forward
A delete is just another append; the tombstone survives compaction so the key stays “gone.”
Per-node compaction
Older records for the same key are dropped.
If the newest record is a tombstone, the key is omitted from the snapshot index.
The file carries an LSM‑style index (key → offset) plus a chain‑checksum footer for integrity.
Promotion logic
A lightweight “snapshot manager” polls nodes for their current maxLSN_node.
The snapshot with the highest LSN wins (maxLSN_cluster).
Why this is safe—even with deletes:
The WBL is totally ordered. If snapshot B has LSN b and snapshot A has a < b, then every mutation in A also appears (possibly overwritten or tomb‑stoned) in B.
For any key k, its state at LSN b is determined by the last record ≤ b:
latest CREATE/UPDATE wins
latest TOMBSTONE hides the key
Therefore, snapshot B is a complete, up‑to‑date superset of A.
This is the same monotonic‑superset property used by log‑structured stores like Kafka or RocksDB to drop old segments safely.
Rolling Snapshots and Layered Recovery
As every node in the KMS cluster keeps its own compacted snapshot instead of relying on a single, cluster‑wide dump. That choice gives us three recovery layers:
Recovery Tier
When we use it
Why it’s fastest
Local Snapshot
Node restarts but still has its SSD
Already on disk; no network hop
Peer Snapshot
Local snapshot lost (disk failure)
Fetch from another node in the rack
Durable Store
Whole rack gone (fire, flood, etc.)
Pull encrypted snapshot from Object Storage
Why this layering matters
Fast restart – most crashes are single‑node; using the local file avoids GBs of network traffic.
Graceful degradation – if the SSD is toast, grabbing a peer’s snapshot beats replaying the whole log.
Last‑ditch durability – even in a rack‑level loss, the encrypted object‑storage copy gets us back online.
This multi‑tier approach is designed to keep recovery times short for common failures while still covering the worst‑case scenarios.
What we get out of it
No global pause – nodes keep serving key‑creates while compacting.
One file to keep – the max‑LSN snapshot subsumes earlier ones, so older files can be discarded or aged out.
Consistent delete semantics – tombstones ensure a key removed at LSN d is absent from any snapshot where LSN ≥ d.
Why “Max‑LSN Wins” Works — A CRDT View of WBL Snapshots
The promotion rule “take the snapshot with the highest LSN” sounds simple; the guarantee behind it comes from treating the log as a Conflict‑Free Replicated Data Type (CRDT).
The log as a CRDT
Operations
ADD(key, blob, ts) – create / update
DEL(key, ts) – tombstone
Order All operations are totally ordered by the log sequence number (LSN) assigned at commit time.
Commutative – order of merging replicas doesn’t change the result.
Associative – (A⋃B)⋃C = A⋃(B⋃C)
Idempotent – merging the same state twice is a no‑op,
any node can build the same final state from any superset of the log.
Snapshot = reduce(log)
A snapshot is simply the deterministic reduction of the log up to some LSN_n.
Snapshot Compression
snapshot_n = reduce(log[0..n])
It is an unordered bag (key‑value map) that already applied the CRDT rules above.
Proof that snapshot_max subsumes earlier ones
Let n < m. For every key k, two cases exist in snapshot_n:
k is present with record op_n(k) at LSN≤n.
If there is no later op for k, then op_m(k) = op_n(k) – no change.
If there is a later op (create/update/delete) at LSN > n, then op_m(k) overwrites it.
k is absent (tombstoned) in snapshot_n.
Same argument: either it stays tomb‑stoned or a new ADD later re‑introduces it.
Therefore snapshot_m contains every mutation reflected in snapshot_n, possibly with newer overwrites. snapshot_m is a superset in LWW‑Set semantics, which justifies the “pick the highest LSN file” promotion rule.
Practical outcome
No global pause or two‑phase commit is required; nodes compact locally.
The highest‑LSN snapshot is always sufficient for full restore; older ones are redundant backups.
Deletes (tombstones) participate naturally—they are just another op with a higher LSN.
Conclusion
With OCI constantly raising the bar on security and performance, our pivot to Write‑Behind Log snapshots does more than tick a resilience checkbox, it fundamentally rewrites our recovery playbook. By keeping every key operation locked inside the HSM, collapsing days of log replay into minutes, and shrinking snapshot size by 5×, we’ve turned disaster recovery from a marathon into a sprint.
For customers, this means quicker failovers and unwavering confidence that their most sensitive cryptographic material stays protected, even when the unexpected strikes.
Ready for the next layer? In Part 2 we’ll peel back the covers on the multi‑layer integrity checks and TPM‑anchored encryption that harden these snapshots against everything from bit‑rot to major outages. Stay tuned and, as always, tell us what you think in the comments or reach out to the OCI KMS team.
This blog series highlights the new projects, challenges, and problem-solving OCI engineers are facing in the journey to deliver superior cloud products. You can find similar OCI engineering deep dives as part of Behind the Scenes with OCI Engineering series, featuring talented engineers working across Oracle Cloud Infrastructure.
Authors
Rakesh Ganimineni
Consulting Member of Technical Staff, Cloud Security and Identity
Rakesh is a software and security architect with 16+ years of experience in distributed systems. He’s the architect for Oracle Cloud’s Key Management Service, where he’s spent the past five years scaling secure, global infrastructure. When not wrangling distributed systems, he’s usually wrangling steep trails, sometimes pushing through 20-mile backcountry hikes, but more often chasing strenuous climbs just for fun.