Elastic graphics processing unit (GPU) scaling, also known as on-demand GPU clusters and burstable clusters, empowers users to dynamically scale their GPU resources to help meet the rigorous demands of their high-performance computing (HPC) or artificial intelligence (AI) or machine learning (ML) workloads. This capability is crucial for on-premises GPU clusters used in HPC, AI, or ML deployments, where computational requirements can fluctuate significantly based on the specific task or model being trained. Embracing this approach helps ensure that organizations are always prepared to effectively handle varying high-performance computational needs.
Challenges in Scaling On-Premises GPU Infrastructure
On-premises GPU infrastructure can offer several benefits, including higher performance compared to conventional CPU processing, excellent data security, and complete control over data access. However, because organizations manage their own on-premises GPU infrastructure, they’re solely responsible for maintaining and updating their GPU infrastructure. This issue requires ongoing attention and often necessitates a dedicated staff for GPU infrastructure maintenance and related tasks, which can increase overall costs.
Organizations performing computationally intensive HPC or AI workloads might eventually encounter several scaling challenges. To meet these scaling needs, the operational department must purchase more hardware to support the cluster and hire staff to install and manage it. This hardware typically includes entire infrastructure required to support the extra compute nodes. Furthermore, the supporting department must secure data center capacity and power to support expansion and accommodate the extra GPU infrastructure.
Expanding this infrastructure can be complex because of the amount of planning needed for the expansion, network topology issues, parallelism schemes, rack layouts, and the overall bill of materials for these systems. After organizations expand their GPU infrastructure, the extra capacity becomes a permanent addition, and associated capital expenditures can’t be recovered, even if the need for increased GPU capacity is temporary or seasonal. These limitations can hinder decision-making for users when considering scaling options for on-premises GPU infrastructure, especially when the necessity for more GPUs is occasional.
Choosing the Proper GPU Depends on the Use Case
Each GPU model is designed for specific use cases, including hyperparameter optimization, distributed training, large-scale inference, video processing, scientific computing, and so on. Because of the varying approaches that HPC, AI, and ML teams use to train, tune, test, and deploy their AI models, selecting or designing an optimized GPU infrastructure based on these use cases can be challenging. In addition, as new and more powerful GPUs become available, the department responsible for the cluster faces increasing pressure to optimize their GPU resources.
GPU Infrastructure Utilization
Organizations aim to maximize the efficiency of their on-premises GPU infrastructure. However, GPUs often remain idle during nonbusiness hours, such as nights and weekends, or when HPC and AI teams are building a model. Increasing GPU utilization and minimizing idle times can significantly improve GPU infrastructure’s return on investment. Unfortunately, achieving this goal for dedicated on-premises GPU infrastructure can be challenging and almost impossible.
Bursting HPC and AI Workloads to the Cloud
Cloud service providers (CSPs) offer a pay-per-use pricing model, allowing users to pay only for the GPU time utilized. Organizations can select from various types and manufacturers of GPUs, which differ in memory size, processing power, and suitability for applications such as machine learning training, inference, and high-performance computing. This model can reduce costs compared to maintaining on-premises GPU infrastructure and provides flexibility for scaling the number of GPUs based on workload requirements. This adaptability allows organizations to access appropriate GPU resources and improves operational efficiency. Leading cloud service providers offer advanced cloud GPU infrastructures, including OCI, Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). These CSPs utilize extensive data center resources to deliver powerful GPU capabilities, often employing hardware from leading GPU and CPU manufacturers. Their services typically include flexible virtual machine (VM) instances or containerized environments, giving users remote access to GPU infrastructures through APIs or web browsers. Organizations should assess the offerings of various cloud providers to determine which best meets their GPU cluster needs.
Types of Workloads to Harness the Power of Elastic GPU Scaling
While GPU scaling provides significant advantages for organizations, not all HPC and AI workloads are ideal candidates. To maximize the benefits, run entire simulations or complete AI training run within the designated clusters. This approach helps ensure optimal workload distribution, efficient node data transfer, and seamless synchronization across multiple GPUs. Attempting to split workloads across remote clusters can lead to suboptimal performance, as intercluster network latency can become a bottleneck, limiting overall efficiency. Challenges of elastic GPU scaling include the following examples:
- Latency and bandwidth: Workloads split across remote clusters can experience delays from intercluster communication.
- Data transfer overhead: Moving large datasets between clusters can introduce bottlenecks.
- Workload suitability: Not all workloads benefit from elastic GPU scaling. Tightly coupled workloads the require frequent communication can suffer performance degradation.
To effectively address challenges in elastic GPU scaling, running entire simulations or complete AI training job within designated clusters is essential. This approach keeps workloads localized, minimizing data transfer overhead and reducing network latency between remote clusters. By performing computations within a single high-performance GPU environment, you can take full advantage of high-speed interconnections, such as remote direct memory access (RDMA) or RDMA over converged ethernet (RoCE), significantly improving communication between GPUs.
Furthermore, running entire jobs in a single cluster ensures efficient synchronization of multiGPU workloads, preventing performance degradation that can occur when processing is fragmented across multiple locations. This method also helps maintain checkpoint consistency, reducing the risk of failures requiring a complete restart. For optimal outcomes, utilize workload managers, such as OCI Kubernetes Engine (OKE) with Node Manager, to allocate GPU resources dynamically. This setup helps ensure that AI training and HPC simulations run seamlessly within the designated cluster.
Why is OCI One of the Top Choices for Elastically Scaled HPC and AI Workloads in the Cloud?
OCI GPU clusters offer numerous advantages over other cloud service providers’ GPU clusters. The comparison among these options hinges on various factors, including performance, networking, scalability, pricing, and overall cloud ecosystem integration. Following a detailed breakdown that includes the following factor can help you choose the best option for your workload:
- GPU hardware availability: All CSPs offer cutting-edge GPUs from leading GPU manufactures. However, OCI frequently provides faster access to newer GPUs and offers bare metal options. As the only primary cloud provider to offer bare metal GPUs from all leading GPU manufactures, OCI provides exceptional flexibility. With industry-leading core counts (up to 192 cores), 2.3 TB of RAM, up to 1 PB of block storage, and high bandwidth, OCI Compute bare metal instances deliver significant performance improvements over other clouds.
- Superior network performance: High-performance networking and interconnects are vital for AI, HPC, and deep learning workloads. While OCI and other major cloud providers offer high-speed InfiniBand networking, OCI provides bare metal networking with lower latency tailored explicitly for HPC workloads, achieving up to 3,200 Gb/sec of RDMA cluster network bandwidth.
- Pricing and cost efficiency: Cost can be a decisive factor, and OCI generally offers better pricing for GPUs. OCI is often more cost-effective for GPU-intensive workloads than its competitors, with bare metal instances optimized for performance, flexibility, and cost. Bare metal instances from other cloud providers can be up to 67% more expensive than comparable options from OCI.
- Ability to offer shorter contract terms: In the last few years, Oracle has invested heavily in OCI and its GPU infrastructure. Because of these significant investments, OCI is in a great position to offer more attractive GPU pricing and shorter-term GPU contracts than other CSPs.
- Scalability and elasticity: OCI supports larger GPU clusters (more than 32 GPUs per node), while other clouds have limitations on cluster sizes. See how much the OCI Supercluster can scale up to here.
- Full control: Oracle doesn’t install software on its bare metal instances, which sets it apart from other cloud providers. This approach gives customers complete control over their cloud stack, just as they would with on-premises setups. This factor is particularly important for organizations utilizing burstable clusters, enabling them to maintain the same software stack and access as their on-premises GPU clusters.
- Faster storage: OCI provides superior storage performance with bare metal NVMe SSDs.
- Lower data transfer fees: OCI provides low networking prices, allowing enterprises to move significant volumes of data at a minimal cost. This feature is particularly advantageous for services requiring high bandwidth, such as HPC and AI training. Like other cloud providers, OCI offers free inbound data transfer. OCI also allows for free 10 TB of outbound data transfer each month. FastConnect has no egress fees, and the outbound bandwidth costs are up to 25% lower than those of other major cloud providers. This benefit is significant for services that demand extensive bandwidth, such as HPC.
- Security and compliance: While all leading cloud providers offer enterprise-grade security, OCI stands out with a stronger approach through its zero trust architecture. Features like shielded bare metal instances, a hardware root of trust, and ready-to-go virtualization are designed to reduce the risk of malicious attacks and ensure secure application performance.
If you require scalable and cost-effective bare metal or VM GPUs, OCI is the optimal choice for HPC, AI training, and deep learning workloads.
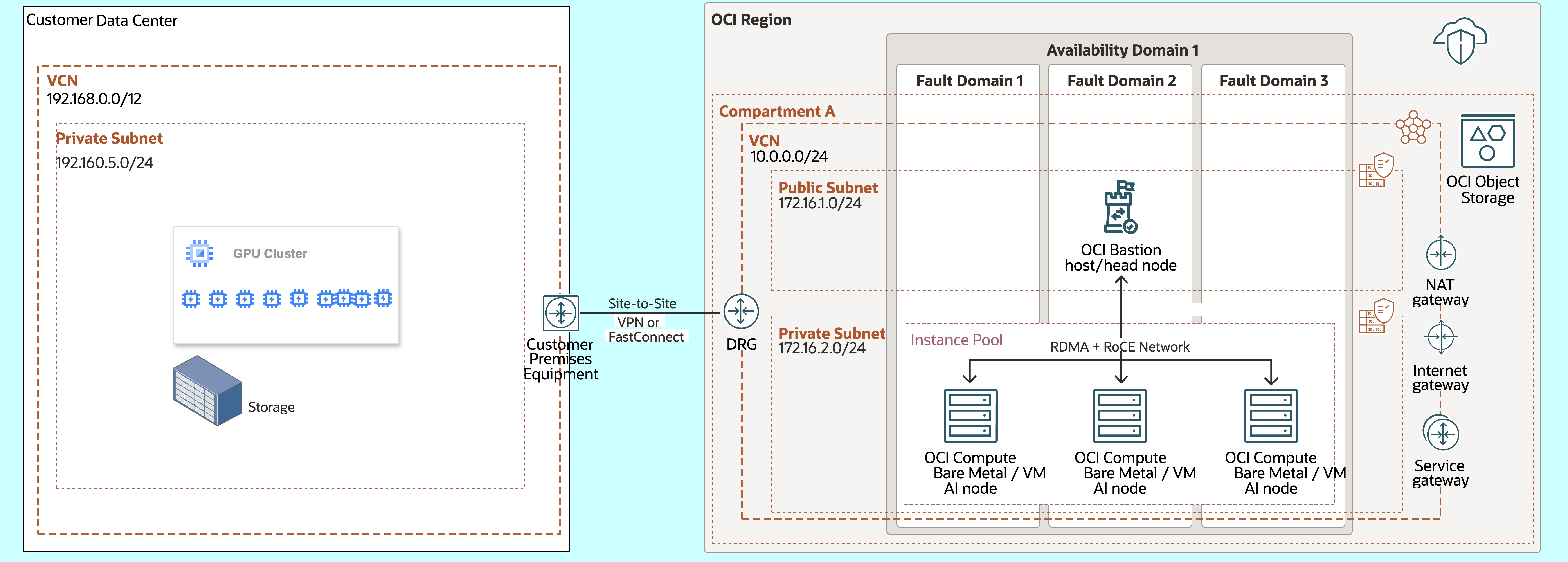
Sample Architecture
This architecture illustrates the relationships among various components in a typical system with a core HPC GPU cluster. In GPU clusters, especially for large HPC, AI, and ML workloads, having a configuration that allows hundreds of GPUs to work together efficiently is essential. A cluster file system supports this setup, which encourages high input or output operations per second (IOPS) and optimal latency. OCI achieves low latency and high bandwidth through low-latency cluster networking using RoCE, which offers less than 10 microseconds between nodes. OCI offers various high-performance storage solutions for HPC, AI, and ML workloads. The bare metal server is equipped with NVMe SSD local storage, which can support scratch network file system (NFS) or parallel file systems like BeeOND or Weka for temporary files. With the OCI Block Volume multiattach feature, a single volume can hold entire training datasets and connect to multiple GPU instances.
In conjunction with balanced performance-tier block storage, bare metal servers and VMs can effectively create file servers using NFS or parallel file systems. Training results are stored in OCI Object Storage. You can quickly provision and deprovision OCI GPU clusters on-demand, delivering a flexible and scalable solution for HPC, AI, and ML workloads. When on-premises GPU clusters are fully utilized for existing workloads, OCI enables enterprises to deploy more GPU resources in the cloud quickly. This capability helps ensure the seamless processing of AI training, inferencing, and other compute-intensive tasks. This approach prevents delays and optimizes resource utilization by dynamically expanding compute capacity as needed.
Example architectural diagram of a deployment of GPU cluster on OCI:
Conclusion
Access to on-demand GPU resources when needed can be a significant challenge for organizations that rely mainly on traditional on-premises GPU infrastructure. Whether you require extensive deployments across thousands of GPUs or just a few, on-premises fixed GPU clusters and legacy cloud providers with rigid GPU solutions can make managing costs difficult for many organizations. OCI offers bare metal and VM GPU solutions that provide exceptional performance, scalability, and cost efficiency for those running AI training models, deep learning inferences, high-performance simulations, or complex data analytics. With industry-leading networking capabilities, high-throughput GPUs, and flexible pricing options, Oracle Cloud Infrastructure stands out as the optimal cloud platform for enterprises seeking on-demand, high-performance GPU computing at a lower total cost.
For more information, see the following resources:
