This blog post explores the cutting-edge architecture behind Oracle Cloud Infrastructure (OCI)’s latest file storage innovation, the high-performance mount target (HPMT), now generally available. Designed by the OCI Storage team, HPMT enhances OCI’s File Storage service to deliver optimized performance for network file system (NFS) storage, particularly for high-throughput and latency-sensitive applications. Using HPMT’s 80-Gbps bandwidth, we demonstrate how its integration into a high-performance computing (HPC) and storage architecture enables the efficient handling of large-scale workloads, such as training and fine-tuning large language models (LLMs) like Llama 3.1-70b and Llama 3.1-405b.
This post focuses on the innovative architecture and solutions that enable large-scale machine learning (ML) workflows using OCI File Storage and OCI HPMT as the data storage. Through a detailed exploration of the system’s components and their seamless integration, we give insights into how HPMT supports larger bandwidths for the efficient processing of training and fine-tuning jobs for LLMs, bridging the gap between compute-intensive tasks and high-speed storage requirements.
Architecture
We used the OCI GPU compute cluster with OCI File Storage and HPMT to fine-tune the Llama 3.1-70B and Llama 3.1-405B models. As part of the proof of concept and technical validation, we used 5 terabytes of sample data from Hugging Face, which was stored in OCI File Storage to run the fine-tune job for the LLM model.
We used the following cloud resources and software stack to perform the technical validation:
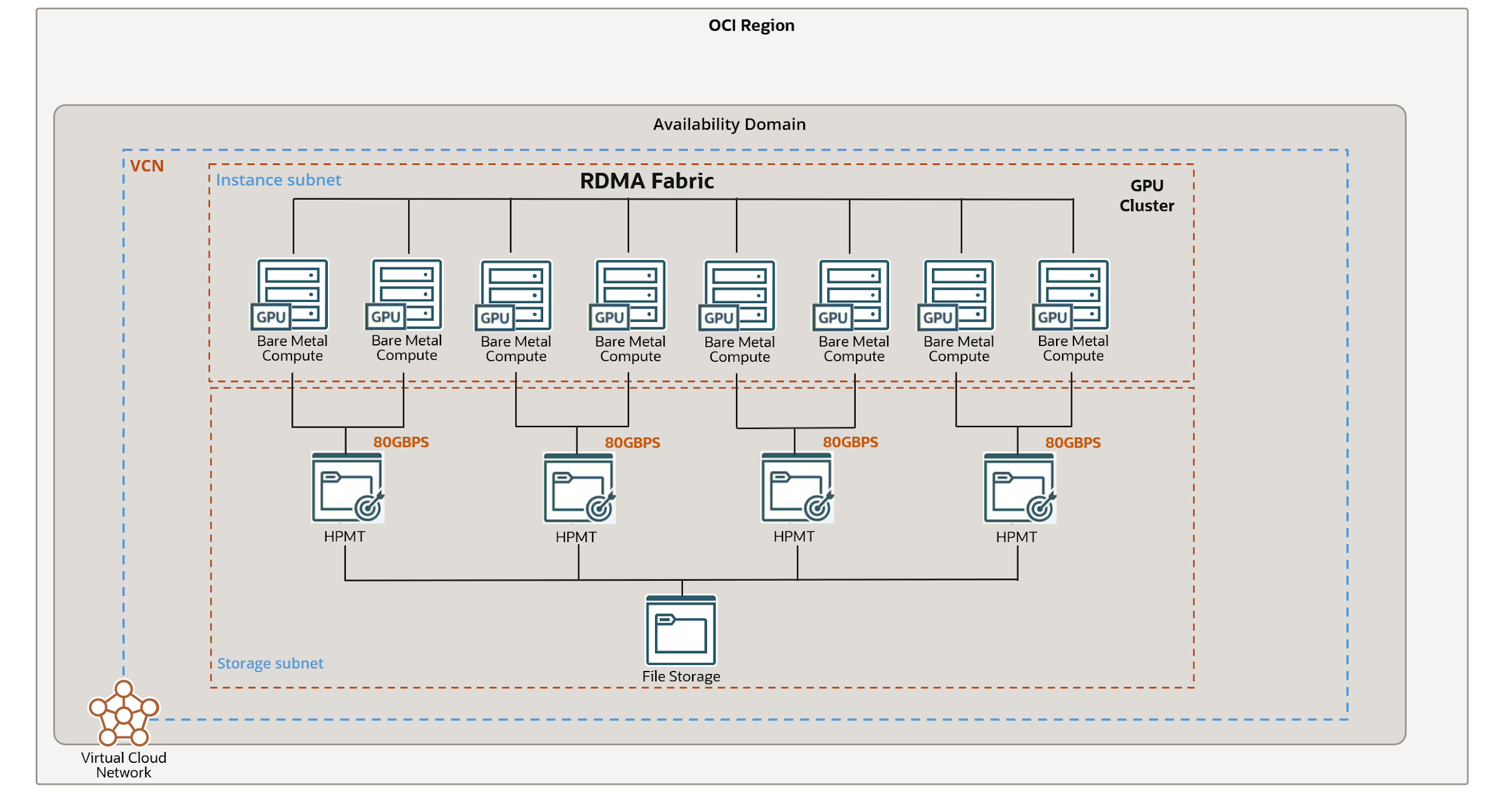
- Compute cluster: The architecture includes eight BM.GPU.H100.8 instances, each equipped with eight NVIDIA H100 GPUs, culminating in a 64-GPU cluster. A SLURM stack was deployed to manage the relationships between these instances, efficiently distributing tasks and ensuring resource allocation. The cluster uses remote direct memory access (RDMA) to facilitate high-speed communication and synchronization across nodes, enabling rapid data transfer and minimal latency during distributed operations.
- Storage system: As part of the technical validation, we used four 80-Gbps HPMTs, with each HPMT serving two GPU nodes. With a bandwidth of up to 80 Gbps per HPMT, this storage solution helps ensure that the system can handle the high-volume data exchange required for training and fine-tuning LLMs. The HPMT delivers consistent, high-throughput, and low-latency performance, which is crucial for storing and restoring model checkpoints efficiently.
- Workflow integration: The architecture facilitates seamless interaction between compute and storage cloud resources. As models are fine-tuned, checkpoints are generated and stored in the file storage service (FSS)using the HPMT. These checkpoints capture the model’s state at various intervals, enabling the process to be paused and resumed without data loss. This workflow highlights its scalability and reliability for enterprise-level AI tasks.
The following architecture diagram provides a comprehensive overview of this system, illustrating the integration of compute, storage, and orchestration layers.
Configuration and Validation
We tested the architecture by fine-tuning the Llama3.1-70B model using the SlimPajamas dataset from the Lit-GPT package. Fine-tuning was chosen over full training to focus on adapting a pretrained model for a specific task, requiring fewer resources and time while maintaining high accuracy.
Environment Setup
To set up the environment, we first deployed an OCI stack using the Oracle Cloud Console, provisioning eight NVIDIA H100 GPU nodes with Ubuntu as the operating system. Next, we installed the NVIDIA CUDA Toolkit and NVIDIA Fabric Manager across all OCI compute nodes to ensure proper GPU communication within and across the GPU nodes. We set up a file storage in the Console and configured four HPMT, each delivering 80-Gbps bandwidth for high-speed data access. In the next phase, we mounted the file storage using the configured mount targets, verified access, and proceeded with programming, using the shared storage for optimized workflows.
We utilized Lit-GPT, a repository tailored for implementing LLM functionalities like fine-tuning, pretraining, and evaluation. Lit-GPT provides enterprise scalability, developer-friendly debugging, and optimized performance for large-scale training. We used SlimPajamas dataset, providing high-quality data, which is perfectly suited for fine-tuning tasks and cloned the following repositories:
git clone https://huggingface.co/datasets/cerebras/slimpajama-627b data/slimpajama-raw
git clone https://huggingface.co/datasets/bigcode/starcoderdata data/starcoderdata-raw
When the Lit-GPT repository is cloned, install it with the command, pip install “.[all]”. To view all the models supported by Lit-GPT, use the command, litgpt download list.
Among the available models, we selected Llama 3-70B, a large-scale model designed for high-performance tasks. Lit-GPT supports both pretraining and fine-tuning functionalities. For fine-tuning, locate the appropriate configuration file, such as config.yaml in the config_hub directory, and modify it to suit your purpose.
Orchestration with SLURM
We used SLURM to coordinate the fine-tuning process across eight BM.GPU.H100.8 instances. Its job distribution capabilities helped ensure efficient utilization of the 64 GPUs, while RDMA-enabled interconnects minimized communication overhead. For multinode orchestration, SLURM takes care of all task distribution and processing. We used the following example SLURM script for pretraining:
Bash
#!/bin/bash
#SBATCH –job-name=litgpt_finetune # Job name
#SBATCH –ntasks-per-node=8 # Matches Fabric(devices=…)
#SBATCH –gres=gpu:8 # Request N GPUs per machine
#SBATCH –mem=0 # Use all available memory
srun litgpt pretrain \
–config=/mnt/my_fss1/l2/litgpt/config_hub/pretrain/config.yaml \
–data.data_path=/mnt/my_fss1/l2/litgpt/data/ \
–data.use_starcoder=False \
–train.max_tokens=100000 \
Llama-3-70B-Instruct
Checkpointing to File Storage Using HPMT and Restoring the Checkpoints
During the fine-tuning process, we updated model parameters to create versions with refined weights. We generated checkpoints at regular intervals and stored them in the File Storage access over the HPMT. This setup helps ensure seamless storage and retrieval of model states, enabling analysis, debugging, or continuation of training phases without retraining the model from scratch. The checkpoints included all essential data, such as optimizer states, learning rates, and model weights.
Similarly, for restoring checkpoints, the saved model states were retrieved from File Storage through HPMT. This retrieval helps ensure a fast and efficient loading process, allowing training to resume from the exact state where it was previously paused. Restoring checkpoints is critical in scenarios like scaling multinode systems, handling interruptions, or transferring training processes between environments.
We used the following sample Python code to capture the checkpoint time:
python
import time
import torch
def load_model_distributed(model_path, num_gpus):
print(“Starting to load the model…”)
start_time = time.perf_counter()
# Load the state dict from the model file
state_dict = torch.load(model_path, map_location=’cpu’)
# Create a list to hold the distributed state dicts
distributed_state_dicts = [{} for _ in range(num_gpus)]
# Distribute the parameters across GPUs
for k, v in state_dict.items():
gpu_id = hash(k) % num_gpus
distributed_state_dicts[gpu_id][k] = v
# Move each distributed state dict onto its respective GPU
for i, d in enumerate(distributed_state_dicts):
print(f”Loading state dict onto GPU {i}…”)
torch.cuda.set_device(i)
model_on_gpu = {} # Create an empty dict for this GPU
for key, value in d.items():
if isinstance(value, torch.Tensor): # Check if the value is a tensor
model_on_gpu[key] = value.to(f’cuda:{i}’) # Move tensor to GPU
else:
model_on_gpu[key] = value # Keep non-tensor values as is
end_time = time.perf_counter()
print(f”Model loaded successfully. Time taken: {end_time – start_time:.6f} seconds”)
# File path to the model
model_path = “/mnt/my_fss1/l2/litgpt/out/pretrain/tiny-llama/final/lit_model.pth”
num_gpus = 8
load_model_distributed(model_path, num_gpus)
By using Lit-GPT, SLURM, and HPMT, we created an efficient and scalable workflow for fine-tuning the Llama model.
Conclusion
The OCI File Storage service enabled with HPMT provides predictable throughput required for AI model training and fine-tuning. By integrating HPC clusters with state-of-the-art storage systems, this architecture not only supports the demands of training and fine-tuning large language models but also showcases HPMT’s potential to revolutionize enterprise-scale AI workflows. The findings demonstrate how HPMT can enhance performance, scalability, and efficiency, making it an indispensable asset for data-intensive applications.
Interested in trying Oracle Cloud Infrastructure File Storage? Sign up for a free trial or reach out to OCI sales. For more information, see the following resources:

