Under the ongoing collaboration with Oracle Cloud Infrastructure (OCI) and the associated funding, the Network-Based Computing (NBC) Laboratory, headed by Prof. Dhabaleswar K (DK) Panda and his team have optimized and enabled the MVAPICH2 MPI libraries to work on Oracle Cloud high-performance computing (HPC) shapes.
The OCI cluster uses RDMA over Converged Ethernet (RoCE) networking technology. Specific optimizations for MPI point-to-point and collective operations have been carried out. For high-performance intranode operations, the XPMEM mechanism with auto module detection has been used. This report provides in-depth performance evaluation of the latest MVAPICH2-X MPI library with other MPI libraries.
Performance evaluation
We conducted a comprehensive performance evaluation of the latest MVAPICH2-X MPI library on the micro-benchmark level and application level. On the OCI cluster network with HPC shape, we compared the performance of several common or OCI cluster network built-in MPI libraries like MVAPICH2-X, HPC-X, and IntelMPI.
Experimental setup
The following list shows the experimental setup, including the hardware configurations and software versions, for the performance evaluation.
-
Compute node shape: BM.HPC2.36
-
OS: Oracle Linux 7.8 OFED5.0
-
OCI cluster network version: oci-hpc v2.6.3
-
Versions of MPI libraries: MVAPICH2-X 2.3, HPC-X-2.8.1 (Built-in Module), and Intel MPI 2021.3
-
Applications: OSU-Microbenchmark-5.7.1 and miniAMR 2.2
Point-to-point communication performance
The following section shows the performance comparison between MVAPICH2-X, HPC-X, and IntelMPI using OSU-Microbenchmarks point-to-point communication tests.
Point-to-point latency
The following two plots show the point-to-point internode latency performance of MVAPICH2-X, HPC-X, and Intel MPI libraries. We observe that, for small message sizes (0–32 B), MVAPICH2-X performance is comparable to Intel MPI. For large messages (1 KB–4 MB), MVAPICH2-X delivers performance similar to HPC-X and is up to 50% better than IntelMPI.
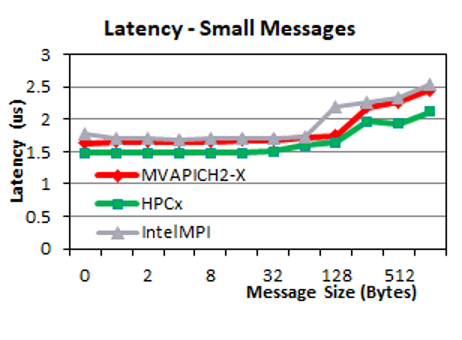
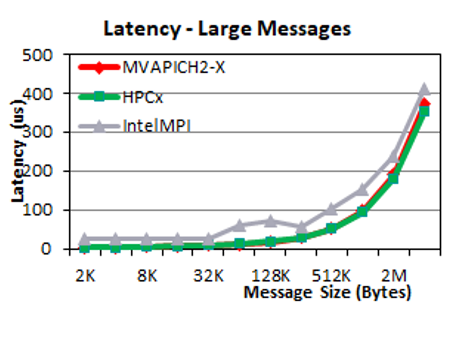
Point-to-point unidirectional bandwidth
The following two plots show the unidirectional bandwidth performance. For small messages, we observe that MVAPICH2-X and HPC-X have similar bandwidth and are up to two times higher than IntelMPI for medium-sized messages (around 1 KB). As the communication messages get larger, the three MPI libraries deliver similar performance.
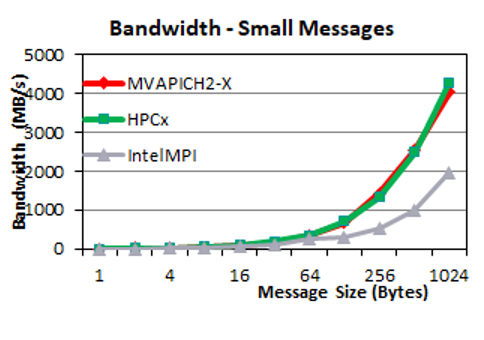
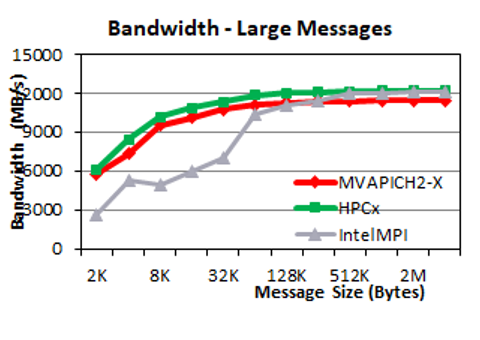
Point-to-point bidirectional bandwidth
For bidirectional bandwidth, MVAPICH2-X delivers much higher bandwidth for medium-sized messages (256 B–1 KB). For large messages, the three MPI libraries deliver similar performance.
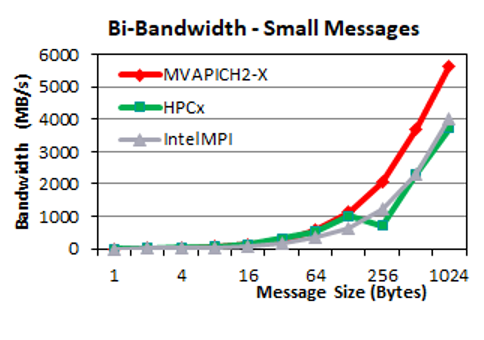
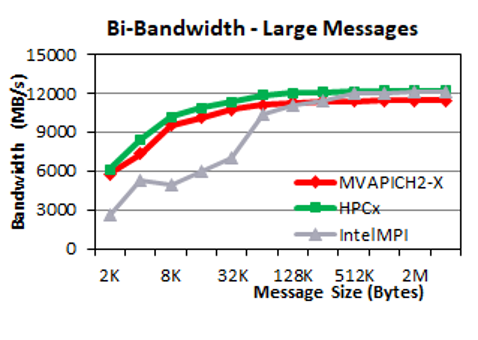
Collective communication performance
The following four plots show the performance comparison between the three MPI libraries using four common MPI collective communication patterns: Broadcast, allreduce, reduce, and scatter. We ran these experiments on eight OCI HPC nodes using the BM.HPC2.36 shape. Each node used 36 processes (ppn). This configuration guarantees that all physical cores are used. The overall collective operations involve a total of (36×8=288) processes.
Broadcast
We observe that MVAPICH2-X and Intel MPI deliver similar performance for small and medium messages (0–32KB). These numbers are better than HPC-X. As the message size grows up to 1 MB, MVAPICH2-X delivers up to 2.7-times lower latency than HPC-X and up to 8.3-times lower latency than Intel MPI.
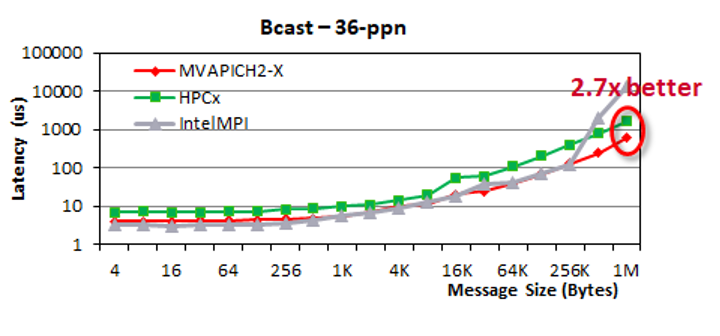
Allreduce
For small and medium messages, MVAPICH2-X delivers comparable performance to that of IntelMPI and HPC-X. But for messages larger than 512 KB, MVAPICH2-X delivers up to five times better performance compared to Intel MPI. In this message range, MVAPICH2-X has comparable performance to that of HPC-X.
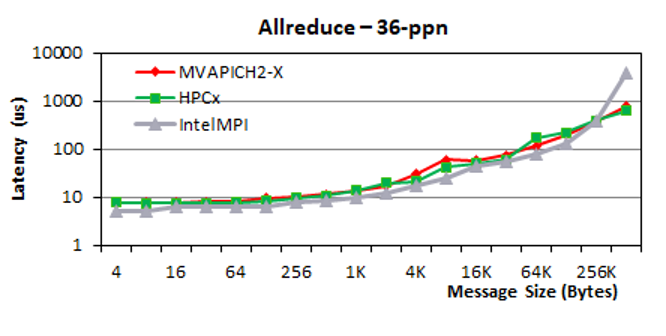
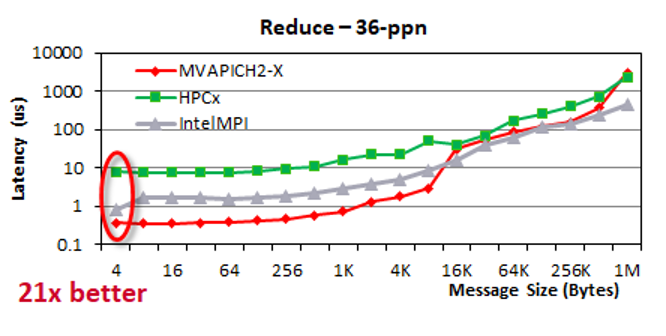
Reduce
For reduce operation, MVAPICH2-X has up to 21 times lower latency than HPC-X and up to four times lower latency than Intel MPI for small and medium messages. For larger messages, the performance of the MVAPICH2-X library converges with HPC-X.
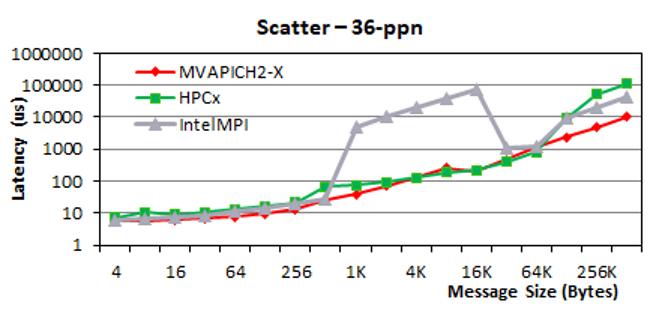
Scatter
For scatter operations, the three MPI libraries perform similarly in small message range (0–512B). For medium message sizes, MVAPICH2-X delivers significantly better performance than Intel MPI. For large messages (such as 512 KB), MVAPICH2-X delivers up to four times better performance compared to Intel MPI and up to 10 times better performance compared to HPC-X.
Applications-level evaluation
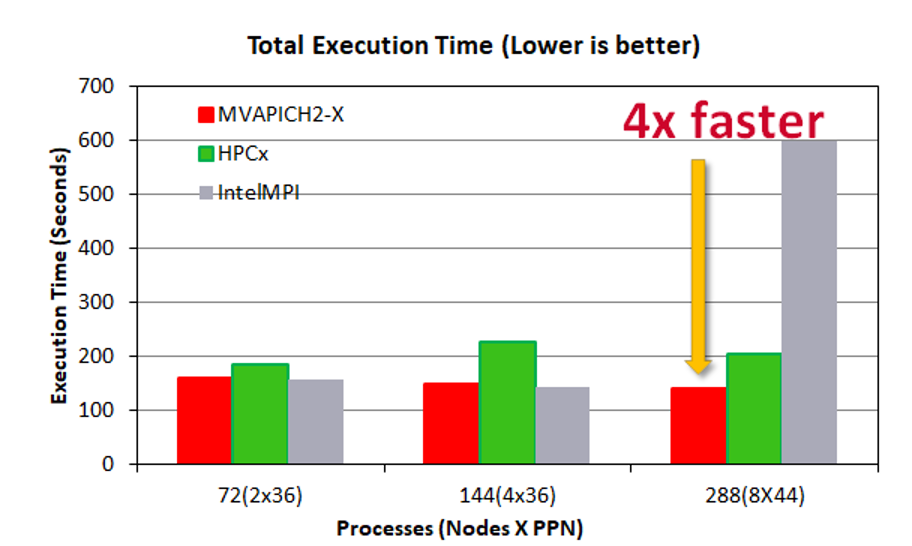
To reflect the performance difference that we observed in microbenchmark level, we conducted an application-level evaluation with the adaptive mesh refinement mini-app: miniAMR. We ran the application on two, four, and eight BM.HPC2.36 nodes with 36 processes per node. The following figure shows the performance of the three MPI libraries with different numbers of nodes.
On smaller configurations of two and four nodes, MVAPICH2-X delivers performance closer to that of IntelMPI. The performance is around 15% better than HPC-X for two nodes and about 35% better for four nodes. On eight nodes, MVAPICH2-X delivers 30% better performance than HPC-X and four times faster than Intel MPI.
Current state
The OSU team delivered an image of the latest version of MVAPICH2-X to the OCI team for more experiments and deployment. This image can be tested on different shapes but is optimized for the BM.HPC2.36. After that, the MVAPICH2-X version can be added to the Oracle Cloud Marketplace for use by OCI users.
Ongoing and future plans
Because the HPC technology is widely being adopted for AI, deep learning (DL) and machine learning (ML), the MVAPICH2 library has been enhanced and optimized to work for these applications. More details are available from High-Performance Deep Learning. These solutions are used on many on-premises GPU supercomputers and clusters, such as Summit at ORNL, Lassen at LLNL, Expanse at SDSC, and Longhorn at TACC.
The OSU team and the OCI Cloud Engineering team are working together to continue the collaboration and getting ready to deploy such solutions on the OCI shapes with GPUs to deliver high-performance, scalable, and distributed training for DL and ML applications.
The following list names the main collaborators for this project:
-
Sanjay Basu, director of cloud engineering at Oracle Cloud Infrastructure
-
Arun Mahajan, principal cloud architect at Oracle Cloud Infrastructure
-
Bryan Barker, research advocate at Oracle for Research
-
Alison Derbenwick Miller, vice president at Oracle for Research
-
Dr. DK Panda, professor and distinguished scholar at the NBC Lab at Ohio State University
-
Dr. Hari Subramoni, research scientist at the NBC Lab at Ohio State University
-
Shulei Xu, graduate scholar at the NBC Lab at Ohio State University
