This blog summarizes the general principles that define a disaster recovery strategy to protect VMware based workloads with the use of Oracle Cloud VMware Solution as the recovery site. You have options for workloads hosted on-premises, within a data center, or a VMware based cloud solution in case a disaster should strike these environments. We cover baseline disaster recovery considerations, but a complete disaster recovery strategy includes many more factors and requires extensive planning.
In the end, the customer, partner, or managed services provider is responsible for picking the best disaster recovery solution for them, if that disaster recovery tooling is compatible and supported by VMware to guarantee a successful replication of virtual machines (VMs) to Oracle Cloud VMware Solution.
What is Oracle Cloud VMware Solution?
Oracle Cloud VMware Solution is a native Oracle Cloud Infrastructure (OCI) service that provisions a VMware software-defined data center (SDDC) in a customer’s tenancy. The customer provides all the required networking infrastructure such as virtual cloud network (VCN), SDDC, and workload CIDRs to successfully deploy the Oracle Cloud VMware Solution SDDC. As a result, Oracle Cloud VMware Solution creates Compute instances on behalf of the customer, connects virtual network interface cards (VNICs) to subnets and VLANs, and installs VMware components to create a VMware SDDC.
Considerations for designing a disaster recovery solution
You have many influential factors to consider for a successful replication and recovery process of the critical workloads. A complete disaster recovery strategy requires more factors and detail, but some high-level considerations include the following examples:
-
Identifying workloads that require disaster recovery protection
-
Recovery point objective (RPO) and recovery time objective (RTO) of workloads that require disaster recovery protection
-
Network bandwidth requirements to replicate workloads
-
Network failover
-
Oracle Cloud VMware Solution disaster recovery sizing and scaling
-
Oracle databases
Identifying workloads that require disaster recovery protection
Identifying the workloads that require disaster recovery protection is the first and most important task, although not all workloads require this protection (test and staging systems, for example). By creating specific inventories of the workloads that you must protect, you can save resources and money in terms of vCPU, vMEM, and Storage. During a disruptive event, you must first recover mission and business critical systems to keep the core business running.
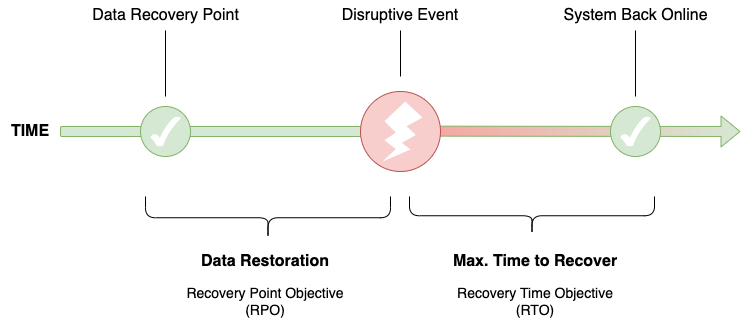
RPO and RTO of disaster recovery workloads
RPO is defined as the maximum amount of data, measured by time, that can be lost after a recovery from a disaster, failure, or comparable event before data loss exceeds what’s acceptable to an organization. RTO is the amount of real time that a business must restore its processes to an acceptable service level after a disaster to avoid intolerable consequences associated with the disruption.
Deciding the PRO and RTO requirements of the workloads that you have chosen to protect has an impact on the network bandwidth, as these factors define how often and within what time frame the data is replicated to the protected site.
Network bandwidth requirements
As mentioned, network bandwidth is a major consideration in a disaster recovery solution because the bandwidth defines how much data can be replicated in each amount of time. You can configure VMware vSphere Replication to compress the data that it transfers through the network, which saves network bandwidth and can reduce the amount of buffer memory used on the vSphere Replication server. However, compressing and decompressing data requires more CPU resources on both the source site and the server that manages the target datastore.
To help you calculate the required bandwidth to replicate your workloads to Oracle Cloud VMware Solution, the VMware vSphere Replication Calculator does some of the work for you, by comparing the following parameters:
-
Total number of VMs to be replicated
-
Average number of virtual disks per VM
-
Average size of virtual disks (GB)
-
Average capacity utilization of virtual disks (Percent)
-
Replication compression enabled
-
Average daily data change rate (Percent)
-
Largest data change burst (Percent)
-
Average RPO in minutes
Network failover
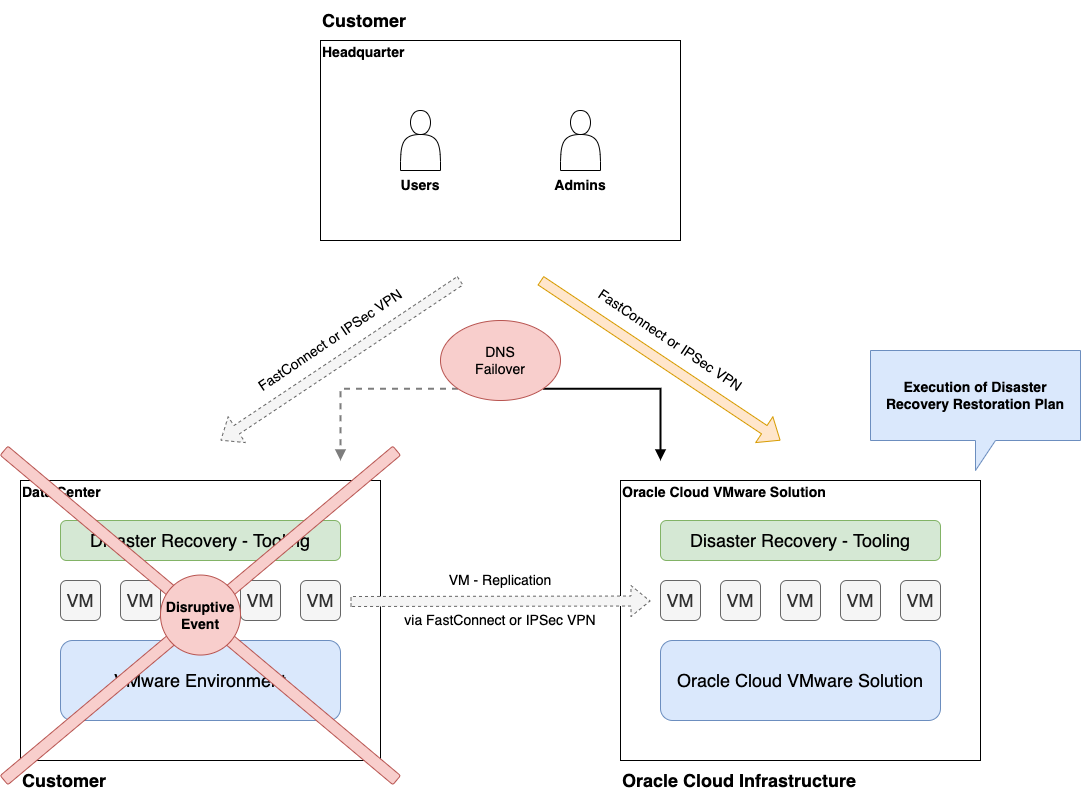
One of the most essential parts of a disaster recovery is the network failover. Sometimes a disruptive event occurs at the primary site and the systems can’t be brought back online within a given amount of time in the primary location because of a data center outage or network connectivity problem.
A solid network concept is key to protect mission critical systems and ensure that end-users and administrators located in the headquarters, remote locations, or home offices have access to the workloads in a disaster recovery scenario, right after the restoration process and network failover to the disaster recovery site.
You have the following options for network interconnectivity:
-
Redundant FastConnect or IPSec VPN connection from customer locations to customer data center with failover detection
-
Redundant FastConnect or IPSec VPN connection from customer locations to OCI with failover detection
-
Redundant FastConnect or IPSec VPN connection from customer data center to OCI with failover detection
Disaster recovery restoration plan
Your disaster recovery restoration plan runs when the disaster scenario strikes and you can’t bring the primary site back online in a given amount of time. In this case, for example, VMware SRM begins the restoration plan, starts up the VMs, and reconfigures networking and domain name system (DNS) of the VMs to work within the disaster recovery environment. You must configure and test this process several times a year as part of the disaster recovery test plans to verify a successful run when a disaster strikes.
Oracle Cloud VMware Solution disaster recovery sizing and scaling
Rightsizing your Oracle Cloud VMware Solution deployment is an essential part of your disaster recovery strategy and involves deciding the number of VMs, RPO and RTO requirements, and prioritizing which VMs start up during a disruptive event. For more detailed information about vSAN sizing and scaling, see the blog post, Oracle Cloud VMware Solution – vSAN Sizing & Scaling.
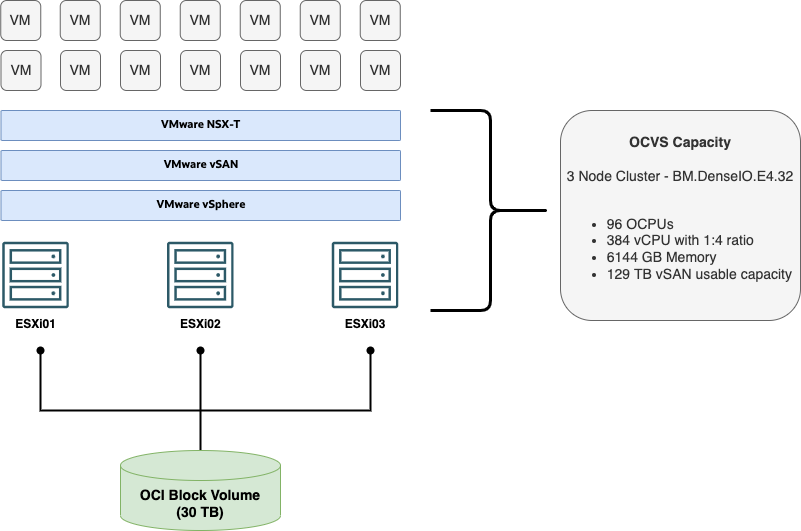
For example, a customer has the requirement to replicate all VMs in his environment with the following resource usage to Oracle Cloud VMware Solution:
-
VMs: 400 VMs
-
vCPUs total: 500 vCPUs
-
vMEM total: 7,000 GB
-
Storage total: 160 TB
Production, test, and development VMs are replicated to Oracle Cloud VMware Solution. However, in a disaster recovery event, the customer only requires the production VMs to be powered on at the disaster recovery site. These VMs only require 250 vCPUs, 4,500 GB vMEM, and 110 TB of storage.
For this scenario, the base Oracle Cloud VMware Solution deployment with a three-node cluster, as shown in the diagram, is fully sufficient. The disaster recovery workloads only require a subset of the available resources. As the storage requirement for all VMs is higher than the 129 TB that the Oracle Cloud VMware Solution vSAN Cluster can offer, an OCI Block Volume was added as an extra VMFS datastore to cover the storage requirements for all VMs. This setup eliminates the requirement to provision another Oracle Cloud VMware Solution ESXi host to extend the storage capacity and results in lower cost.
If the vCPU and vMEM resources aren’t sufficient in the future with the growth of the source environment, one solution is to reserve Oracle Cloud VMware Solution ESXi instances to be ready to scale the environment on demand in a disaster recovery scenario. You can also add OCI Block Volumes for future storage expansion without the need to scale up Oracle Cloud VMware Solution ESXi Hosts.
Best practices for Oracle databases
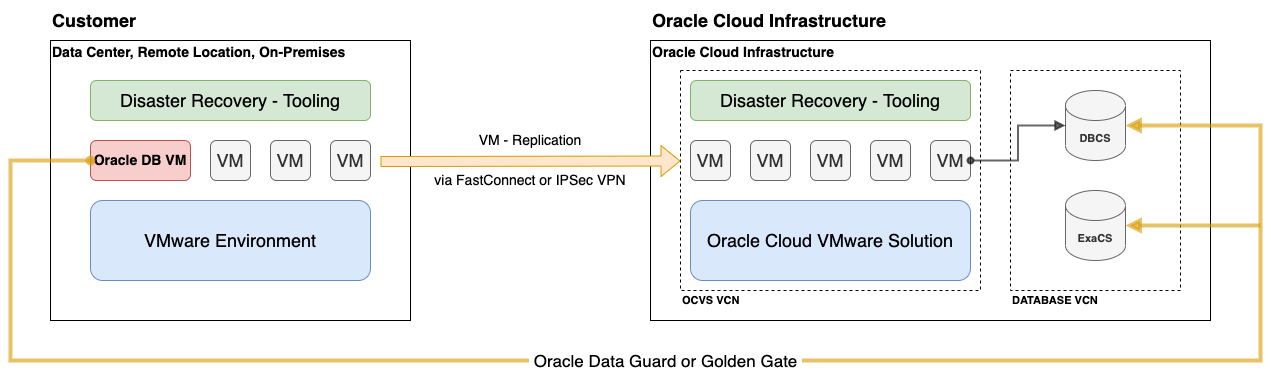
Disaster recovery for Oracle databases from a customer’s VMware environment to Oracle Cloud VMware Solution can contain some challenges, such as Oracle Database licensing on Oracle Cloud VMware Solution and separation of Oracle Cloud VMware Solution clusters for Oracle databases, database management overhead, maintenance operations, and disaster recovery tests.
The best approach to overcome these challenges is to replicate all VMs to Oracle Cloud VMware Solution except the Oracle Database VMs. You can replicate the Oracle databases with Oracle Data Guard or Golden Gate to native OCI Database services like Database Cloud Service, Exadata Cloud, or Autonomous Database. This approach eliminates the requirement for a separate Oracle cluster within the SDDC and reduces licensing costs and brings a lot of operational advantages.
Disaster recovery solutions and resources
Many disaster recovery solutions in the market provide protection of mission-critical workloads. Besides VMware vSphere Replication with VMware Site Recovery Manager and RackWare for VMware and non-VMware based workloads, Oracle Cloud VMware Solution supports any VMware-supported disaster recovery solution to protect workloads from any location to Oracle Cloud VMware Solution.
We have summarized the general principles that define a disaster recovery strategy to protect VMware based workloads with the use of Oracle Cloud VMware Solution the recovery site. A complete disaster recovery strategy requires more detail and personalization for your specific needs. With the overview that we’ve provided, the following resources can give you more insight about VMware on Oracle Cloud Infrastructure:
