We’re excited to announce a new release of Oracle Cloud Infrastructure (OCI) Data Integration. This release expands more connectivity options using HDFS, Hive, Influx DB, and Amazon Aurora, introduces bulk data loader to support m:n data entities load, and allows you to provide parameters in data entity names.
Cloud native, serverless data integration
As a refresher, OCI Data Integration is a cloud native, fully managed serverless extract, transform, and load (ETL) service on OCI. Organizations building lakehouses for analytics and data science, AI and ML on OCI with Object Storage, and autonomous data warehouses can quickly deliver insights by simplifying, automating, and accelerating the consolidation of data from multiple data silos.
Data Integration provides a graphical, no-code design interface, with interactive data preparation and profiling. It also helps data engineers to design data pipelines using patterns and rules to handle schema evolution. It supports both Spark ETL and ELT push-down execution to the database. If you’re not familiar with this new service, check out this blog to find out more: What is Oracle Cloud Infrastructure Data Integration?
Data Integration is available in all OCI commercial regions.
Bulk data loader
We introduced bulk data loader as an enhancement to the existing data loader task. The bulk data loader task enables the use cases where n:n loading of data is required between two systems with minimal-to-no transformations. This task is required for data preparation, data migration, or loading diverse data into data lakes like OCI Object Storage.
With the bulk data loader task, the entire process is now done with a few clicks without worrying about the complexity of the underlying steps. All you need to do is create a data loader task, which entails having to specify the sources and targets with the option to specify transformations, mapping the attributes, publish, and run it.
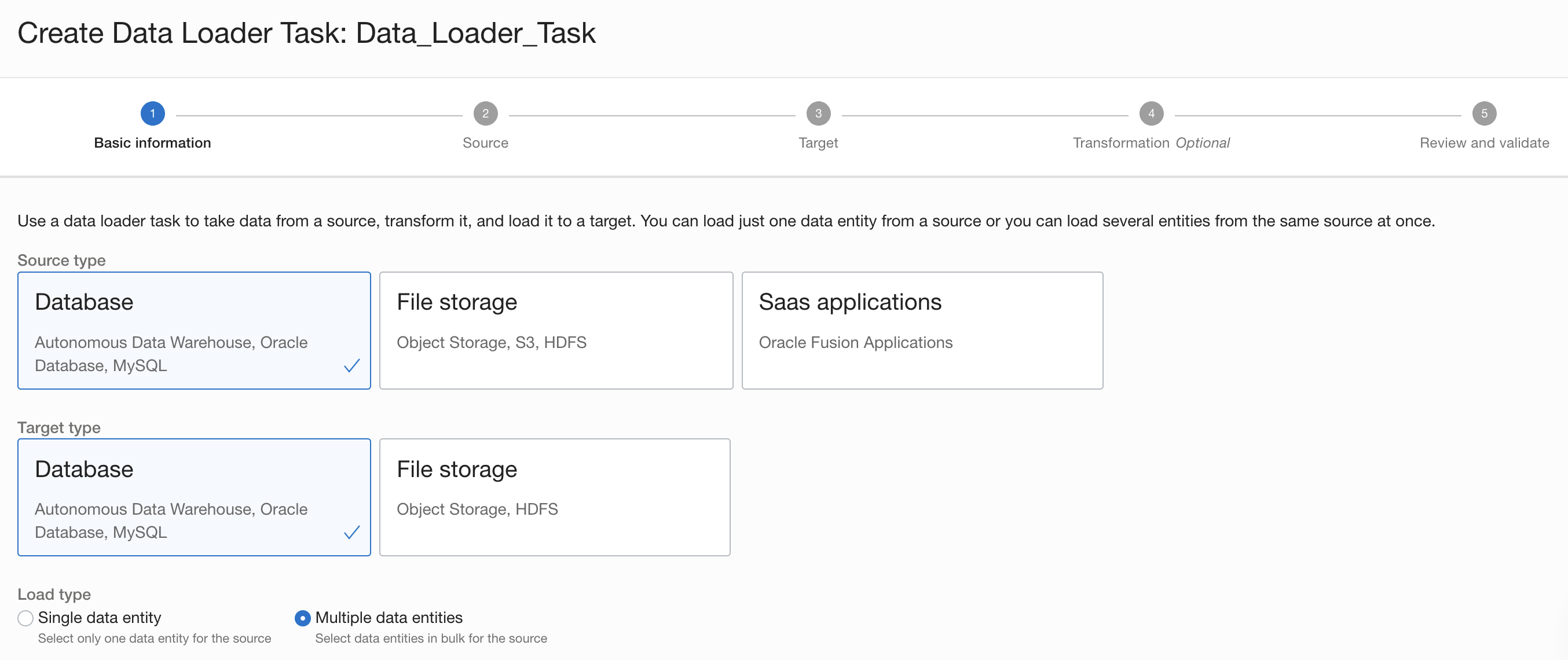
Figure 1: Bulk data loader
More features
In OCI Data Integration, you can now fetch the file metadata for the files residing in OCI Object Storage and AWS S3. While using REST task in OCI Data Integration, you can specify polling and deletion configuration for a REST task that calls a long-running API operation. You can also use parameters in the data entity names when you select a data entity for a source or target operator.

Figure 2: Parameters for source data entity
Want to know more?
Organizations are embarking on their next-generation analytics journey with Oracle lakes, autonomous databases, and advanced analytics with artificial intelligence and machine learning in the cloud. For this journey to succeed, they need to quickly and easily ingest, prepare, transform, and load their data into Oracle Cloud Infrastructure. Data Integration’s journey is just beginning! Try it out today!
For more information, review the Oracle Cloud Infrastructure Data Integration documentation, associated tutorials, and the Oracle Cloud Infrastructure Data Integration blogs.
