Oracle Analytics allows you to easily create custom calculations in data visualization projects. It’s a simple process to extend your analysis or datasets with any calculations and aggregations you may need right while you are building your visualizations, irrespective of the type of underlying data. You can build a custom calculation on a data visualization project directly, or you can build it in the dataset using the Data Prepare tab.
But which one is the right one, since there are multiple places where custom calculations can be built? What is different between a custom calculation built in a data visualization project versus a custom calculation built in the Data Prepare tab of Oracle Analytics?
Understanding the main difference between these two should help you make the best choice on where to build your next custom calculation.
Subscribe to the Oracle Analytics Advantage blog and get the latest posts sent to your inbox
The flow of this blog entry is illustrated in the video below:
To illustrate the point, let’s demystify a simple example whose results may seem confusing. My dataset has order lines details, with sales value and quantity sold for each order line.
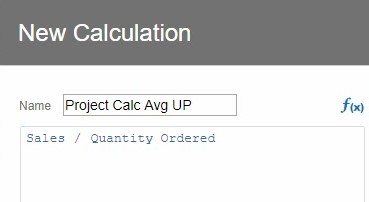
I built and made a copy of a custom calculation defined as Sales divided by Quantity Ordered. I placed one copy in my project using the Add Calculation menu, and the other in my Data Prepare tab using the Create Column menu. Both of these calculations are built with the identical formula as shown in the image below.
Yet when I add both calculations in the same data visualization and compare the results, I am getting different values for each calculation. This shows the two last columns in my result table, one for each custom calculation.

What Happened?
At first sight, this is puzzling. How can the exact same calculation return different results based on where it’s built in Oracle Analytics? And more importantly, which one is right, and which one is wrong?
The question behind this confusion comes down to how the sequence of aggregations and calculations are performed. Think about it. If in a spreadsheet file, you compute the sum in a total column at the far right of your table compared to computing the divisions on the bottom line, you might get different results. If you do it the other way around, you may also get different results with the same formula.
- In the case of the Project-based calculation (highlighted in black), Oracle Analytics will first run the initial query to fetch raw data needed in the view, and return the aggregated results set. Then it will run the calculation. So, for this example, it will first return sales and quantity by Product Category (3 rows) and only then will it calculate the division of Sales by Quantity ordered for each of the three Product Category lines. This will give us what we could call a “weighted unit price average.”
- In the case of the Data Prepare-based calculation (highlighted in red), Oracle Analytics will calculate it the other way around. It will first execute the calculation at the dataset detail level. So, first, since our dataset is at Order-line level (each row in the dataset represents an order line), Oracle Analytics will compute the division of sales by quantity distinctly for each order line.
Once that is done, it will run the query to fulfill the data visualization and will then aggregate the result-set data for each Product Category. So, since in our example we set an aggregation rule of AVG for our new Data Prepare calculated Unit Price column, it will take all the granular unit prices for all order lines in a given Product Category and return the average of these. It will do so for each Product Category (3 rows). We could call this an “unweighted unit price average.”
Here are the equations written out based on where the calculations are being made.

The video above also shows you how these calculations can easily be manually verified in a spreadsheet.
Note that in the case of a Data Prepare calculation, the result is exactly what we would have gotten if a Unit Price column had existed directly in the source dataset for each order line row (database table, CSV file, etc.). So in that sense, extending your dataset with new Data Prepare calculated columns is like extending it directly in your source file.
Which Calculation Is Correct?
It depends on what your analysis requires. In most of the cases, data visualizations require a level of calculation-aggregation on initial data (by country, by employee, by year, and so on). The most representative value here is a weighted average, so that’s produced using a Project-based custom calculation. This was our first example. So, in most of the cases, Project-based calculations are the safest way to go, particularly when you are not sure exactly what you need. You can’t go wrong with it. Build your calculations in the Project-based custom calculations directly, but be aware that if you want to persist them in the dataset for others to use, they may behave slightly differently if the calculations are aggregated in some visualizations later on.
But in some cases, like binning (a data preprocessing technique used to reduce the effects of minor observational errors), or running the Explain feature, you need to keep granular data in your calculation. That is where you want to use the Data Prepare level calculation.
In our example, let’s say that we also need to show sales by “ranges” of unit prices, as an example, bins of unit prices. We want to see the Sum of all sales where the unit price is between 0 and x, then x and y, etc. This will work easily with the Data Prepare calculation we have. We just need to drag it in the category axis of any chart and the binning will happen automatically. Note that this feature will not work with a Project-based calculation.
In conclusion, building custom calculations in a project or in a Data Prepare dataset are different things, potentially leading to different results. They each have a purpose within Oracle Analytics, and each can be leveraged based on your particular needs.
In general, using Project-based custom calculations will be used most frequently, while the Data Prepare-based calculation will help you cover more of your advanced aggregation needs.
To learn how you can benefit from Oracle Analytics, visit Oracle.com/analytics and follow us on Twitter @OracleAnalytics.

{kind=link}
{kind=link}