Merging two data sets into one data set is a common requirement for analysts manipulating diverse data sources. Oracle Analytics Cloud Data Flow feature enables a friendly way to do this within the context of preparing data, just before building visualizations and deriving insights out of it.
There are numerous scenarios in which union rows step of the data flow can be leveraged. Let’s say you are a sales manager looking at employee performance. You may have collected data over time, and you want to compare different intervals for an upcoming quarterly business review. Or, let’s say you have collected data in a before-and-after project—where the analyst collects data before an event, and then again after. There is a step-by-step approach for this in Oracle Analytics Cloud. We’ll be covering them in this article.
Subscribe to the Oracle Analytics Advantage blog and get the latest posts sent to your inbox
Prerequisites for Using the Union Rows Step in Data Flows
The “Union Rows” step in the Data Flows feature can merge two data sets into one, provided the two input sources have the same structure. It operates in a similar way to the SQL union operation in the database, where result set of two queries are merged into a single output:
- Both the data sets should have same number of columns,
- The data types of the corresponding columns in data sets should match. For example, column number 1 of data set number 1 must have the same data type as column number 1 of data set number 2 and so on.
In other words, you can easily merge datasets that are of similar format. For example, sales data for different months are in different data sources, or HR data for various subsidiaries are in different files.
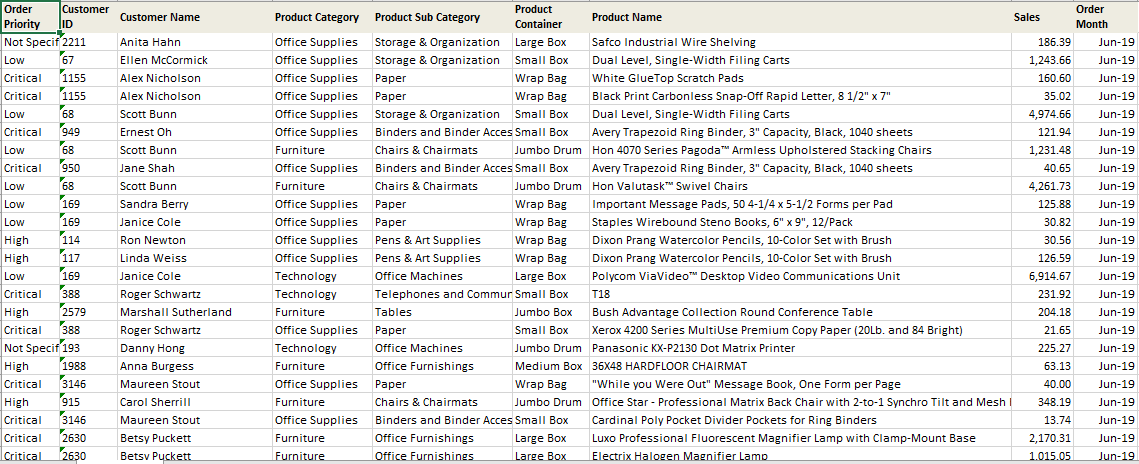
So, for our example, let’s consider two data sets with sales order information for two separate months: June 2019 and July 2019. This data has columns like Order Priority, Customer Name, Product Category, Product Name, and Sales as a metric. There are some customers in these data sets who have purchased the same product across the two months, as seen in the image below.
Data Set – June 2019 (100 rows)
Data Set – July 2019 (100 rows)
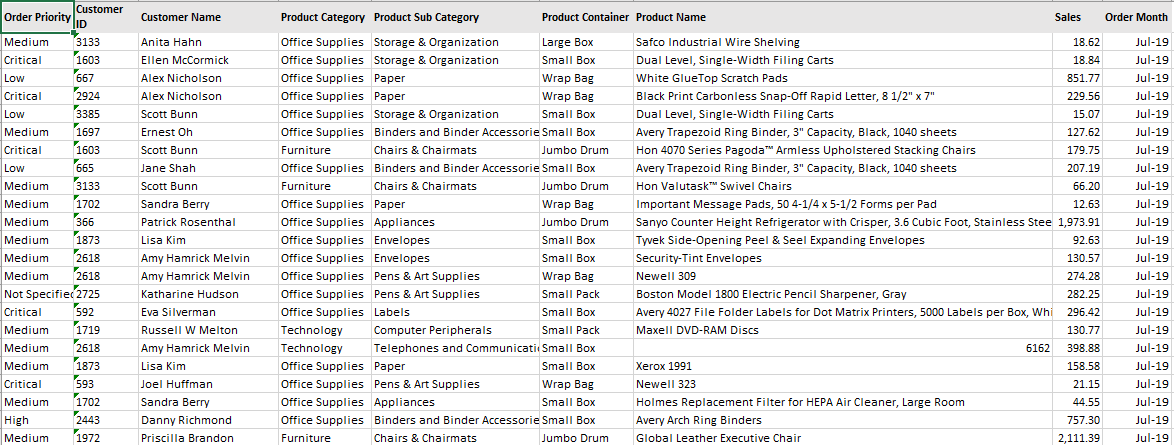
We have 10 rows of customers who have purchased the same products across the two months. We will see how these 10 rows of duplicate data across the two months are handled in the various Union operations discussed below.
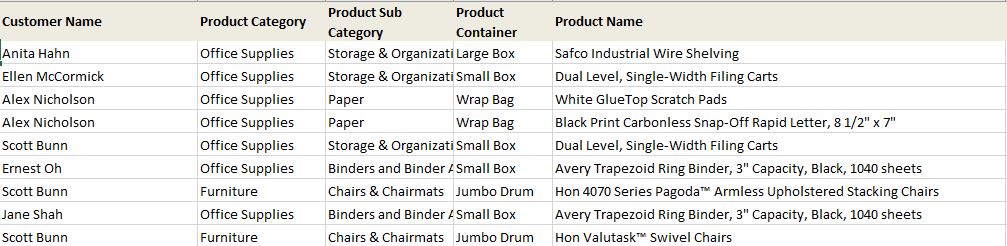
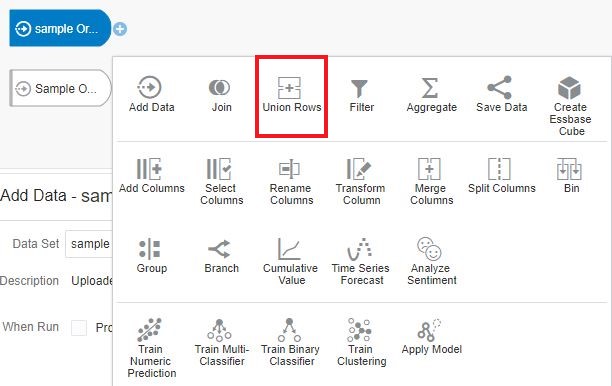
How to Create a Union Row Step in Data Flow
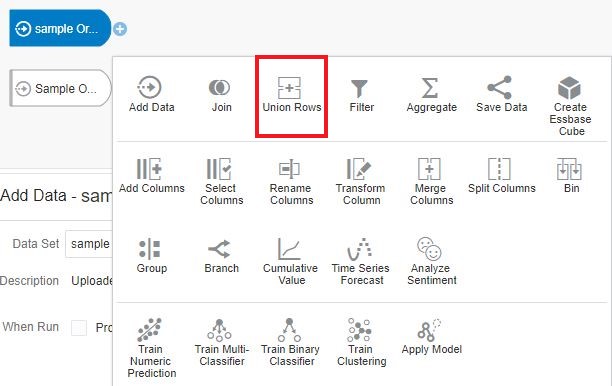
Let’s add both the data sets to an Oracle Analytics Data Flow, and further down in our Data Flow click on the “+” icon and choose Union Rows step. The Union Rows step gets enabled only when there is more than one data set added in the Data Flow.
As the step adds to the Flow, click on the suggested “second” data node to complete the Union Step. that is just to indicate which two data-sets we want to union.
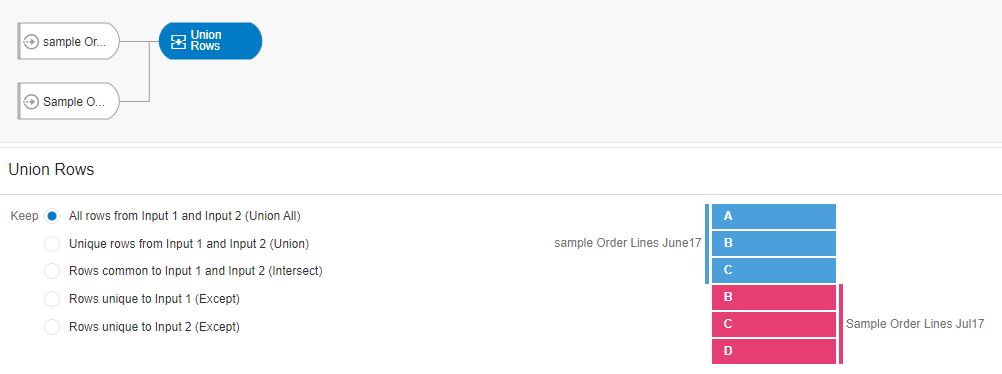
The details of this node present various options in which a Union operation can be performed are presented along with a visual representation of the chosen option. The visual representation clearly specifies what would be the resulting data set when the options are chosen. The Options available are as follows:
- All rows from input1 and input2 (Union All)
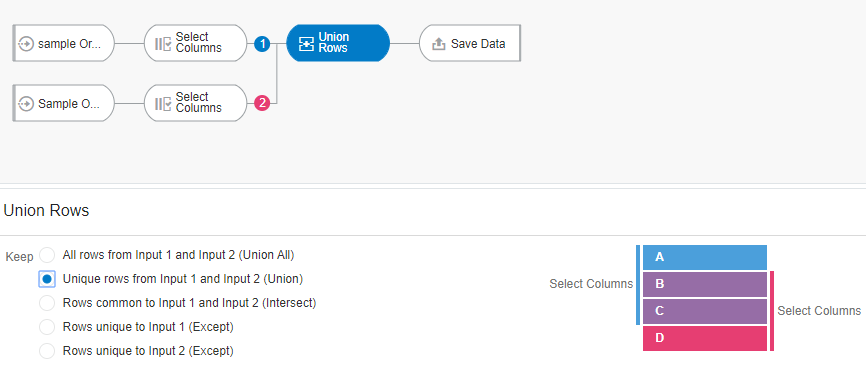
- Unique rows from input1 and input2 (Union)
- Rows common to input1 and input2 (Interesct)
- Rows unique to input1 (Except)
- Rows unique to input2 (Except)
Use Case 1: Merge Both the Data Sets
Let’s say we want to merge both sets into a single data set for reporting purposes and keep all the rows. In this scenario, all the rows from data set number 1 must be merged with all the rows from data set number 2 (equivalent to a Union All operation in SQL). This operation will not eliminate any duplicate records. The visual representation of this operation is shown on the right of the image below; explaining how the resulting data set would look like.
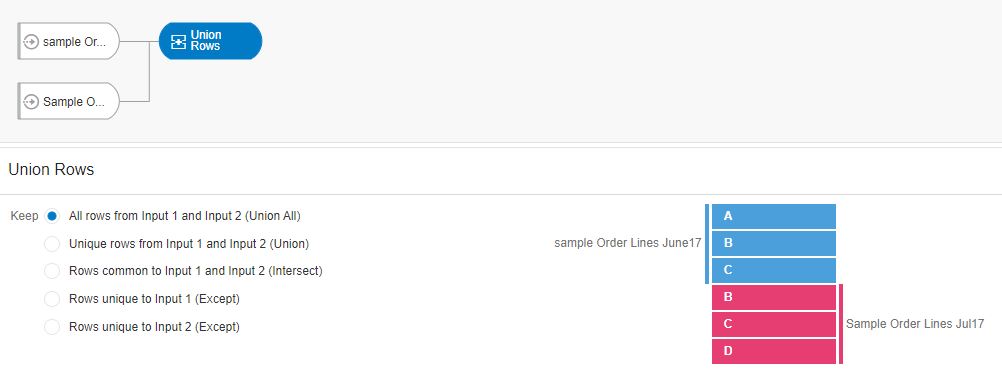
So, let’s complete our Data Flow with the two input data sets, use the Unions Rows node with the first option selected and execute the flow.
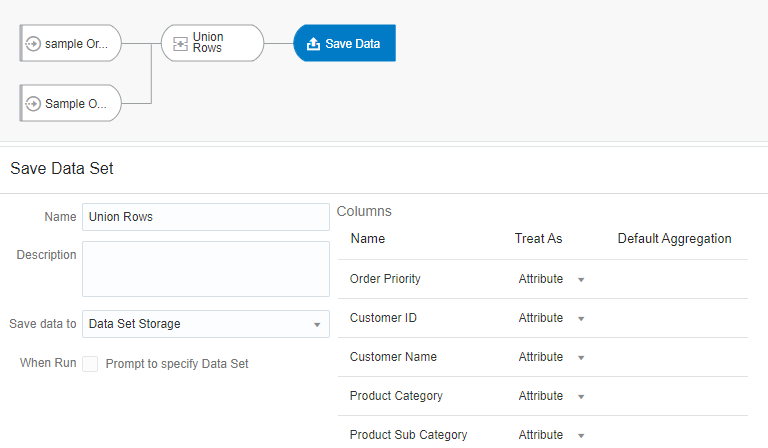
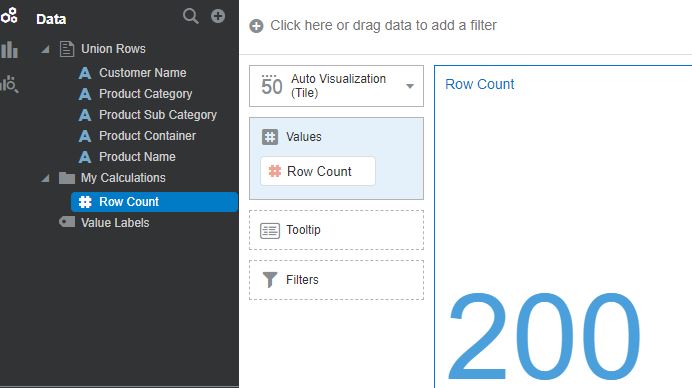
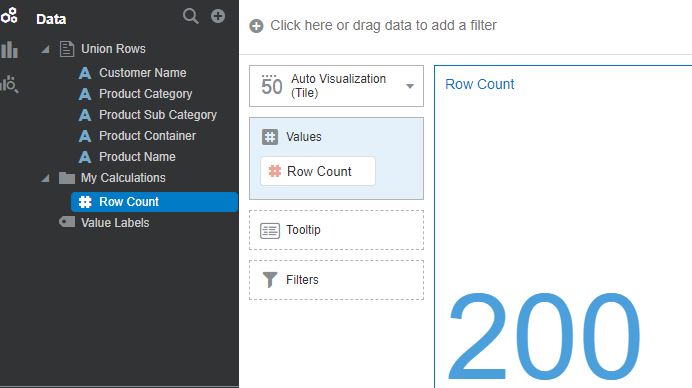
When the data flow is executed, a Data Set is created with the merged output, and its total number of rows (which can be calculated using a formula like sum (1)) is 200. This shows that the union operation merged both the data sets without removing any duplicates.
Use Case 2: Merge Without Duplicates
Let’s now say we want to merge both the data sets but only want to keep the distinct combinations of customers and products they purchased over the two months. In effect, we want to remove duplicates across the two data sets with these same combinations. This is similar to a Union operation in SQL. A Union operation merges the rows from both the data sets by eliminating the duplicates and retaining a single copy of the duplicate rows
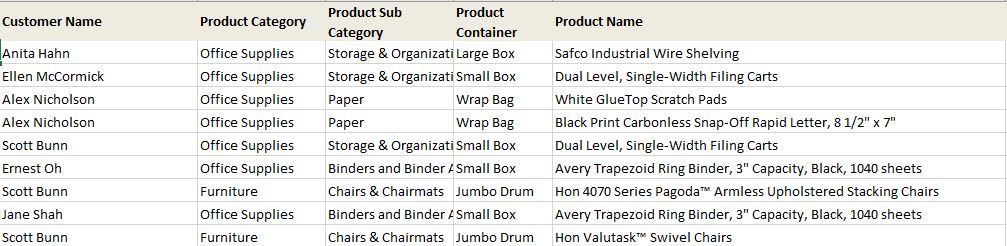
In order to achieve this, let’s trim down the data set by retaining only customer and product—related columns. So, we achieve this by using a “Select Columns” node just before our Union Rows node, and we keep only the following columns: Customer Name, Product Category, Product Sub Category, Product Container and Product Name. Let’s now perform a Union Rows on these two data-sets and select the second option which is “Unique rows from Input 1 and Input 2.”
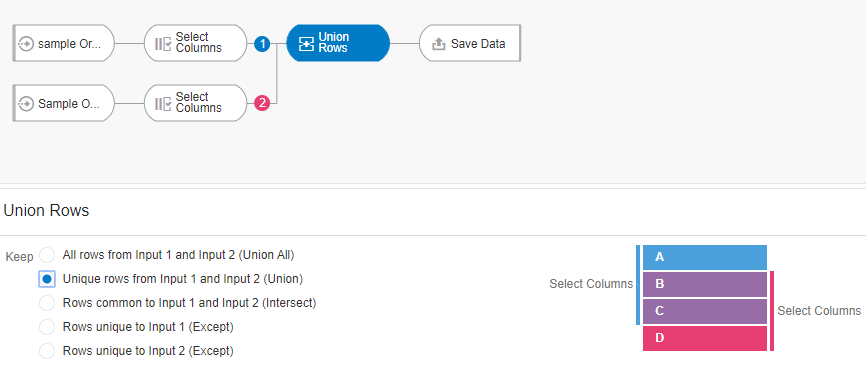
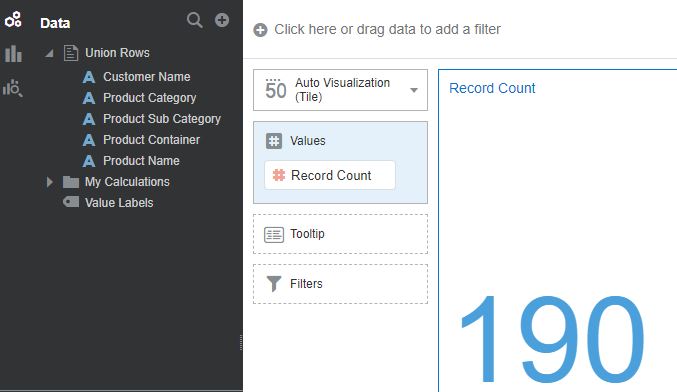
When the data flow is executed and creates the merged output, we notice that row count in the resulting data set is 190. This shows that only one copy of the duplicate records (10) were retained in the output.
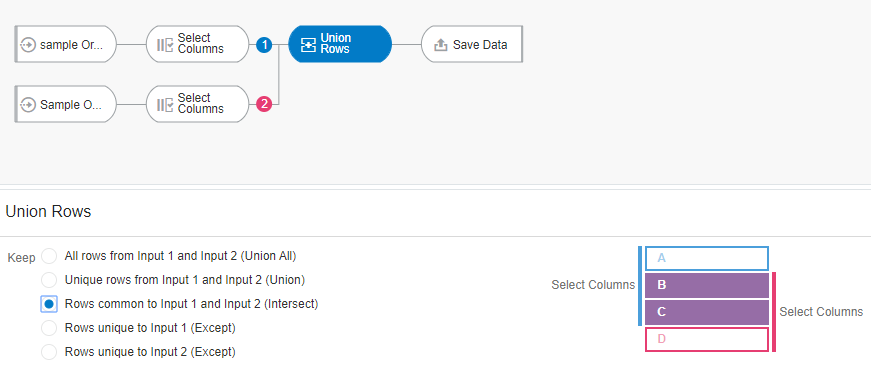
Use Case 3: Rows Common from Input1 And Input2
Now let’s say we want to find the list of customers who have ordered the same products twice, once in June and once in July. In this scenario, we must find the common records with the same customer and the same product between the two data sets. This is similar to an intersect operation in SQL.
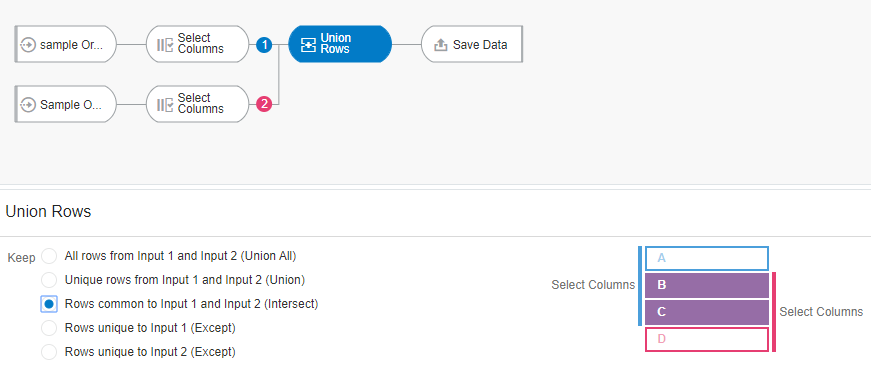
Let’s define the data flow similar to the one described in Use Case 2 with just the customer and product-related columns selected and apply a Union rows node with the third option “Rows common to Input 1 and Input 2.”
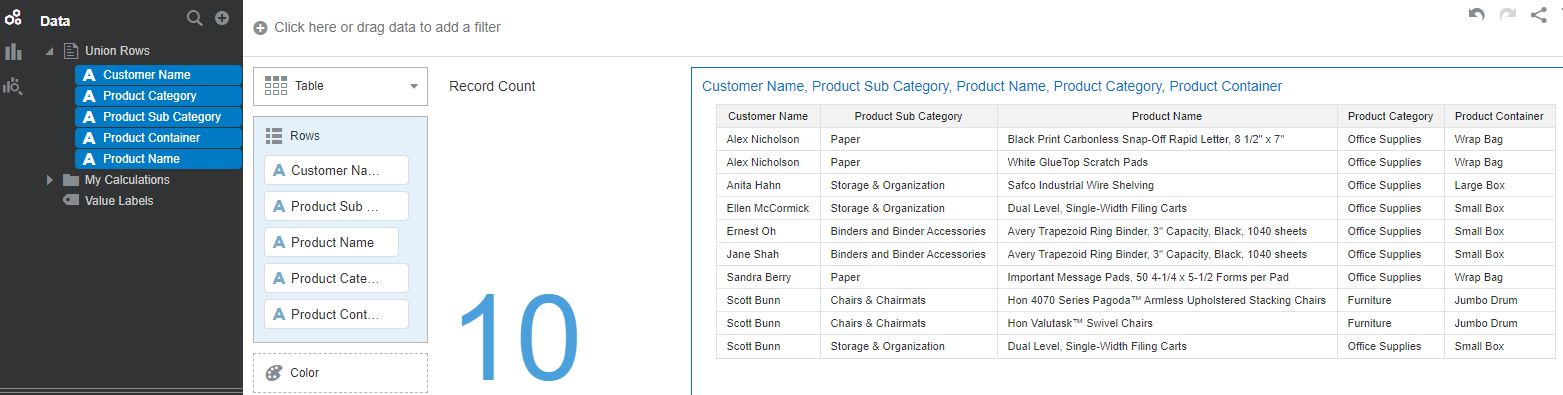
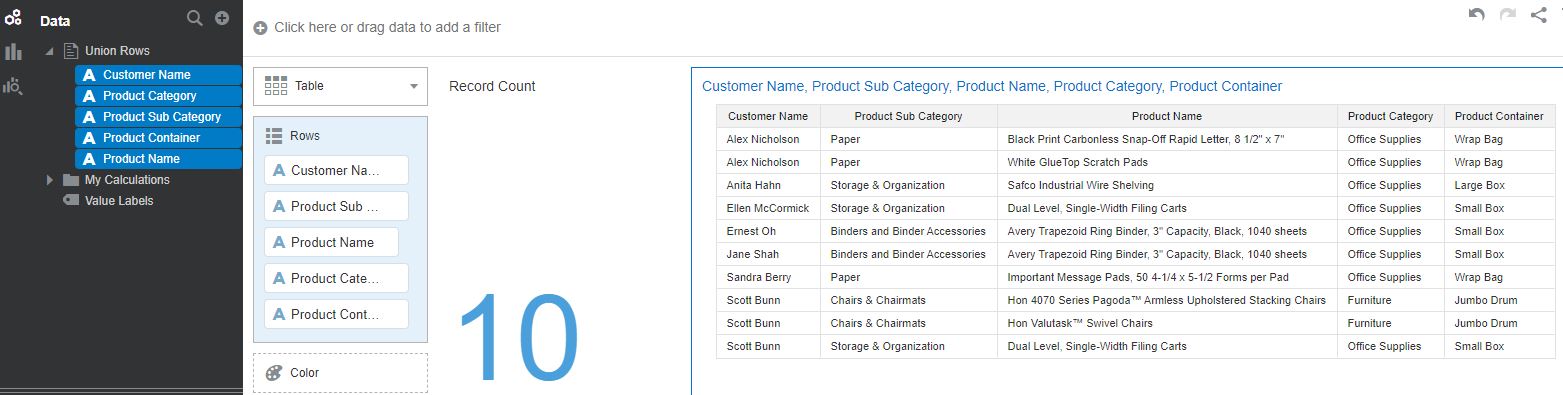
When the data flow is executed and creates the merged output, we notice that row count in the resulting data set is 10. Only one copy of the duplicate records was retained in the output. The detailed tabular reports show the exact intersecting records between the data sets.
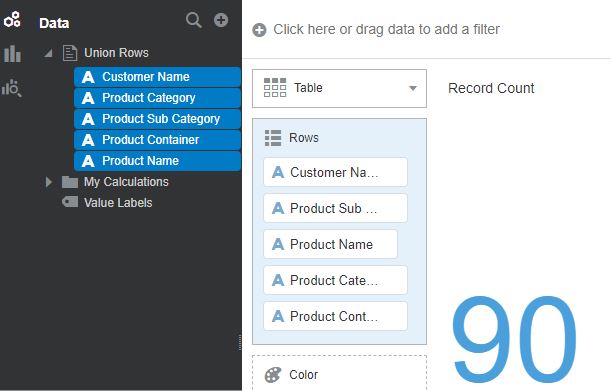
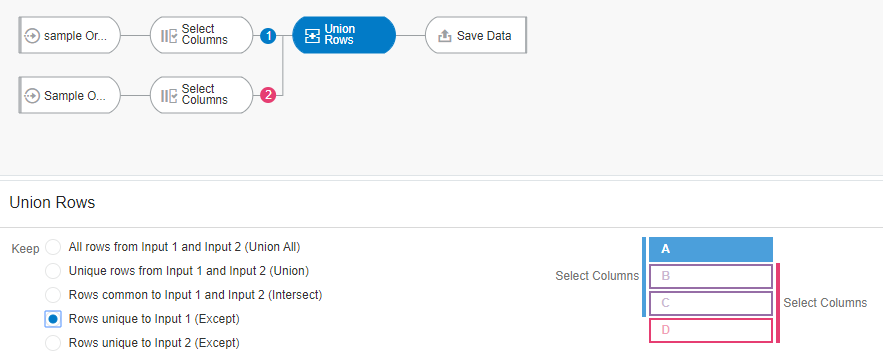
Use Case 4 and 5: Rows Unique to Input1 (Except)
Finally, let’s say we are interested in those customers and products that were ordered only in June but were explicitly not ordered in July. Both the data sets have to be merged by retaining only the unique records in the first data set. This is equivalent to an “except” operation in SQL.
Let’s again define the data flow and choose the option “Rows unique to Input 1”
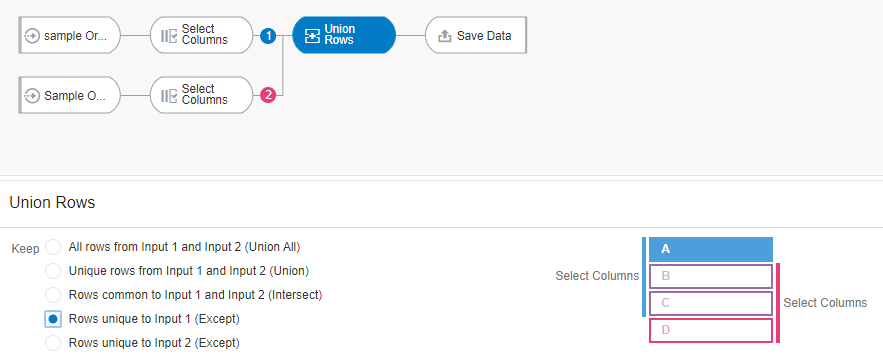
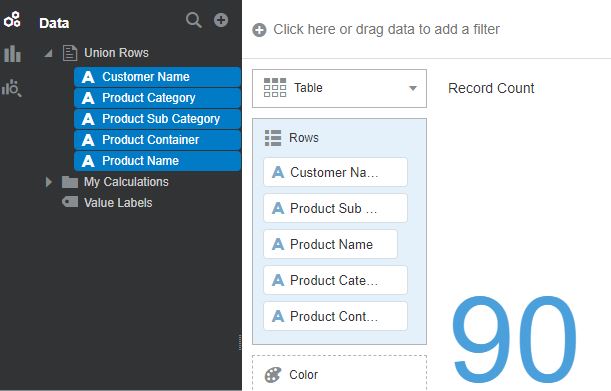
When the data flow is executed and creates the merged output, we notice that record count in resulting data set is 90, meaning only those records in the first data set except the records that are common to the second data set are saved in the output.
Note that if a user needs to merge more than two data sets, it can be done in multiple steps in the same Data Flow: first merge two data sets, then merge the output to the third data set and so on.
Union-Rows node allows a friendly way to merge two data sets in an Oracle Analytics Data Flow. It will work agnostic to the type of data source, as long as the respective structure of the data is identical.
To learn how you can benefit from the Oracle Analytics Cloud, visit Oracle.com/analytics.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}