![]()
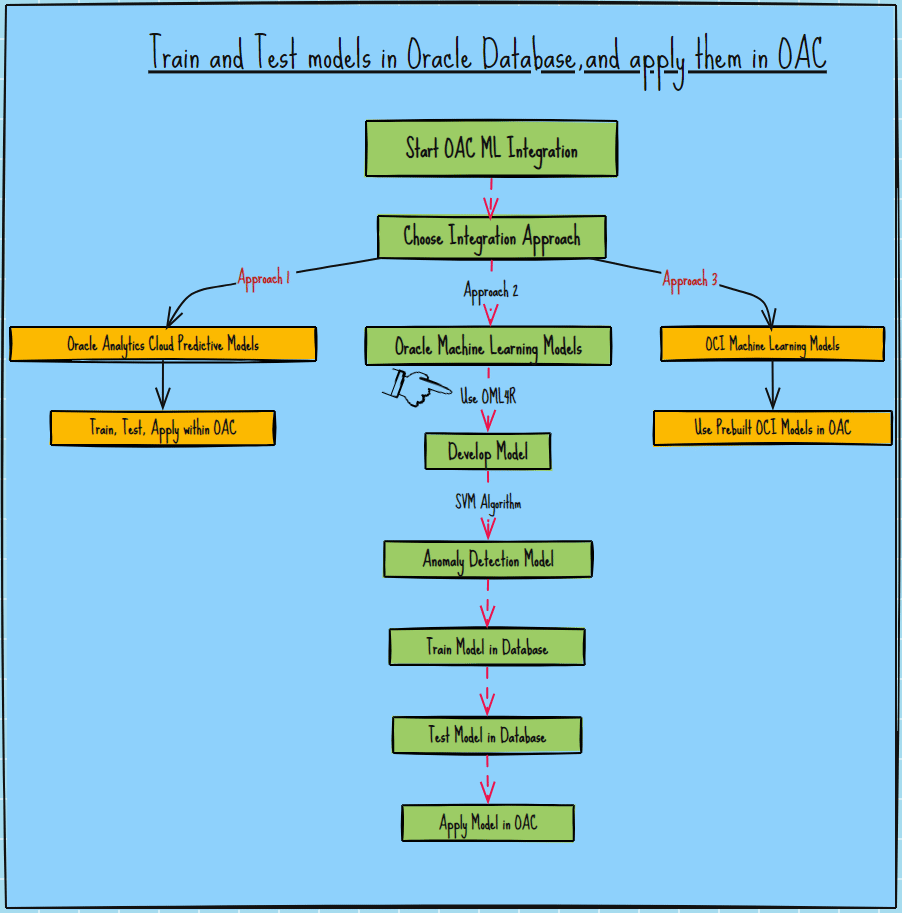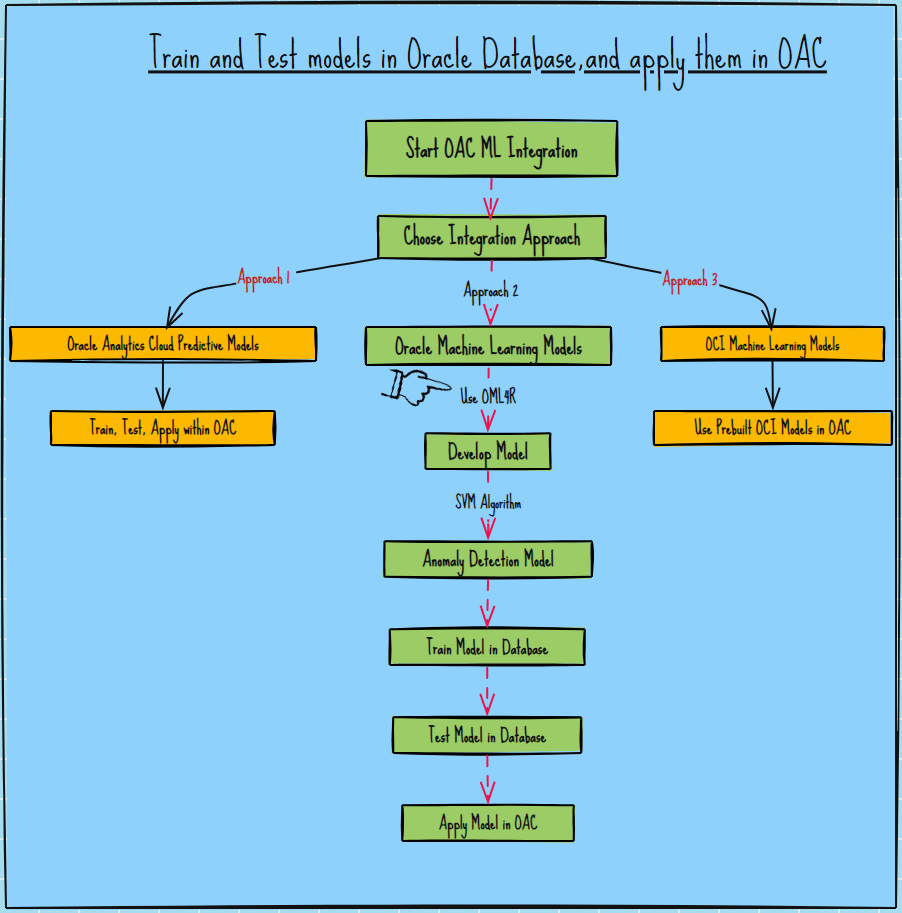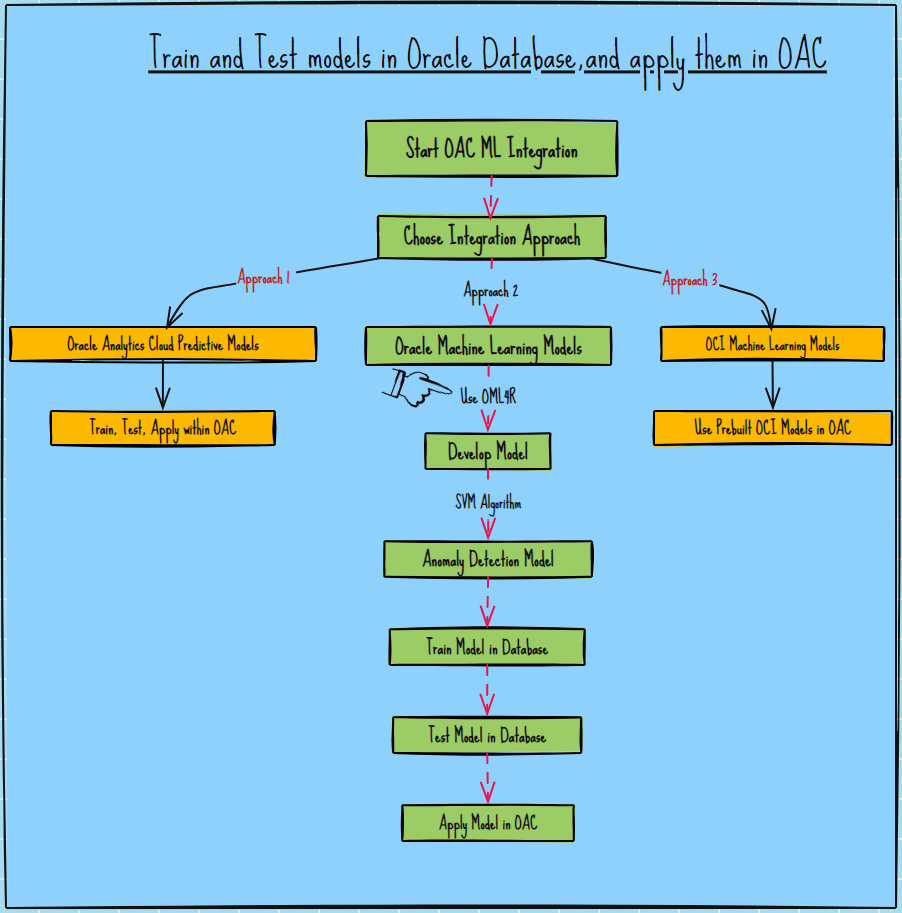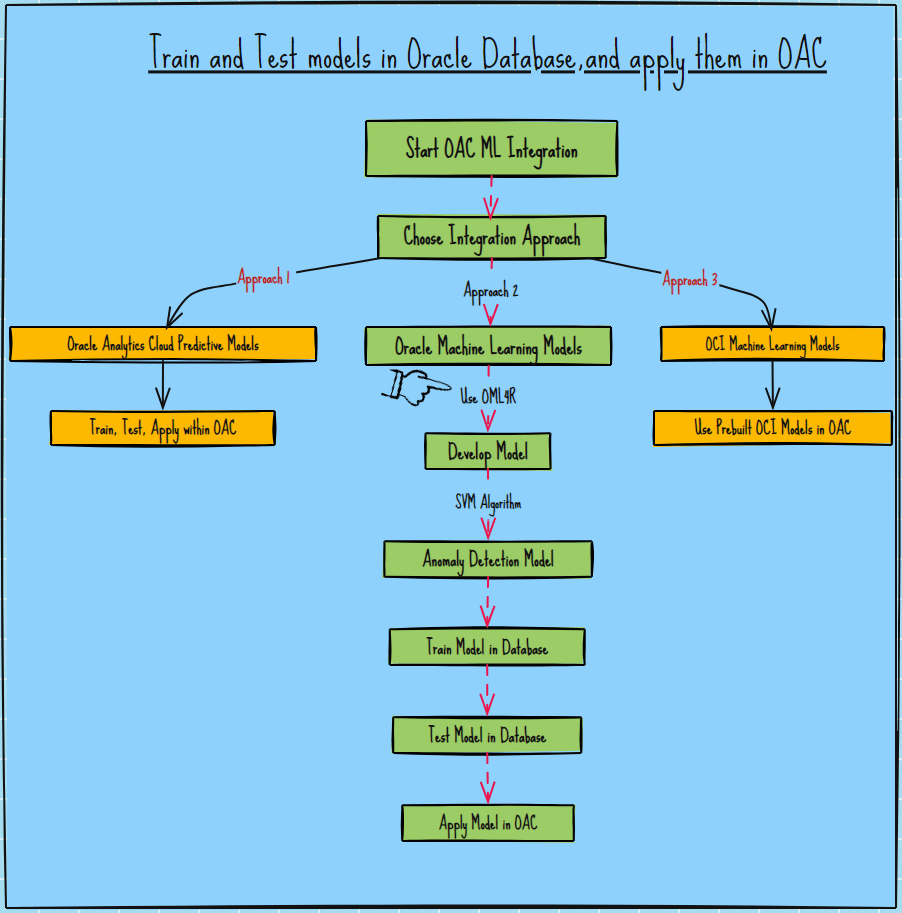
Oracle Analytics Cloud (OAC) offers various approaches to integrate machine learning models, ensuring flexibility and efficiency in your data analysis processes. The three primary approaches are:
- OAC Predictive Models: Train, test, and apply models in OAC.
- Oracle Machine Learning Models: Train and test models in the Oracle database and apply them in OAC.
- OCI Machine Learning Models: Use prebuilt models and apply them in OAC.
This article guides you through using Oracle Machine Learning for R (OML4R) to train and test models in the Oracle database and deploy them in OAC.
What’s the Goal?
This blog describes developing and deploying a machine learning model for anomaly detection. Anomaly detection is essential in various fields such as finance, manufacturing, and IT for identifying rare events or observations that deviate significantly from the norm. The primary challenge in anomaly detection is the lack of labeled training data, which makes supervised learning approaches less effective.
The Example in this Blog
The blog uses a dataset of insurance claims to identify fraudulent claims. Fraudulent claims are anomalies in this dataset, as they’re rare compared to most legitimate claims. Since the example is based on not having labeled data indicating which claims are fraudulent or sufficient data to train a model, the blog describes an unsupervised learning approach.
Choosing the Right Algorithm
The blog uses the Support Vector Machine (SVM) algorithm configured for anomaly detection. SVM is effective in high-dimensional spaces, robust to outliers, and flexible with different kernel functions. It’s well suited for scenarios where the data has a clear margin of separation between normal and anomalous observations. Additionally, SVMs are scalable for large datasets and seamlessly integrate with Oracle Machine Learning, optimizing performance in Oracle Autonomous Data Warehouse (ADW).
Get Started
To run R commands in a notebook, you must make use of the R interpreter. To use OML4R, you must load the omlR library, which automatically establishes a connection to your database.
Using the default interpreter bindings, OML Notebooks automatically establishes a database connection for the notebook. To verify the R interpreter has established a database connection through the omlR library, run the command:
library(omlR)
oml.isconnected()
This command returns True when your notebook is connected.
Part 1: Train the Model
Step 1: Set Up the Environment
Ensure you have the necessary libraries and an active connection to your Oracle ADW instance.
library(omlR)
Step 2: Load the Dataset
The ‘INSURANCECLAIM’ table contains sample data.
Load the dataset from an existing table INSURANCECLAIM in Oracle ADW.
dataset <- oml.sync(table=’INSURANCECLAIM’)
print(head(dataset))
Step 3: Split the Dataset
Split the dataset into training and testing sets.
%R
set.seed(32)
train_idx <- sample(seq_len(nrow(dataset)), size = 0.8 * nrow(dataset))
train <- dataset[train_idx, ]
test <- dataset[-train_idx, ]
Step 4: Save Training and Testing Data to Separate Tables
Save the training and testing datasets to separate tables.
%R
oml.create(train, table=’INSURANCE_CLAIM_TRAIN’)
oml.create(test, table=’INSURANCE_CLAIM_TEST’)
print(head(train))
print(head(test))
Step 5: Set Anomaly Detection Parameters
Define the settings for the SVM model. These settings specify how the model behaves but don’t include the model name.
%R
odm_settings <- list(svms_outlier_rate = 0.01)
print(odm_settings)
Step 6: Instantiate the Anomaly Detection Model
Create an instance of the SVM model using the settings defined in odm_settings.
%R
model <- oml.svm(“anomaly_detection”, settings=odm_settings)
Step 7: Train the Model
Train the model using the training dataset and assign a name to the trained model.
%R
model <- oml.train(model, data = train, model_name = “InsuranceClaimDetection”)
InsuranceClaimDetection: This is the trained model itself. This is what you would register and use within OAC to apply the model for making predictions.
Part 2: Test the Model
Step 1: Make Predictions on the Test Dataset
Use the trained model to predict anomalies in the test dataset.
%R
predictions <- oml.predict(model, newdata = test)
print(head(predictions))
Step 2: Apply the Model to the Entire Dataset and Save Predictions
Use the model to make predictions on the entire dataset and save the predictions to a new table in the database.
%R
predictions <- oml.predict(model, newdata = dataset)
oml.create(predictions, table = ‘INSURANCE_CLAIMS_PREDICTIONS’)
print(head(predictions))
Explanation
- INSURANCE_CLAIM_TRAIN: Contains the training data used to train the model.
- INSURANCE_CLAIM_TEST: Contains the testing data used to evaluate the model.
- INSURANCE_CLAIMS_PREDICTIONS: Contains the predictions made by the model on the entire dataset or new data. This table stores the results of applying the model.
InsuranceClaimDetection: This is the trained model itself. This is what you would register and use within OAC to apply the model for making predictions.
Part 3: Apply the Model in OAC
Register Oracle Machine Learning Models in Oracle Analytics
You must register Oracle Machine Learning models in Oracle Analytics before you can use them to make predictions. You can register and use models that reside in your Oracle Database or Oracle Autonomous Data Warehouse data sources. For detailed steps, refer to the Oracle documentation.
Apply the Model in OAC
- Register the Model in OAC:
- In OAC, navigate to the machine learning model management section.
- Register the model InsuranceClaimDetection. This makes the model available for use in OAC.
- Use the Model for Predictions:
- In OAC, create a data flow.
- Add a step to use the registered model InsuranceClaimDetection.
- Apply the model to a new dataset to get predictions.
- Analyze Predictions:
- The output dataset, which contains predictions, can be stored back in the database or used directly in OAC for further analysis and visualization.
By following these steps, you ensure that the model is appropriately used within OAC to make predictions and analyze results.
Conclusion
This blog post describes how to use Oracle Machine Learning for Python (OML4Py) to develop a model for anomaly detection using the Support Vector Machines (SVM) algorithm. The blog covers how to train and test the model in the Oracle Database and apply the model in OAC. By following these steps, you can seamlessly integrate predictive models into your applications, incorporating machine learning (ML) and artificial intelligence (AI) capabilities without the need for extensive ML or AI expertise.
Call to Action
Now that you have information about how to build and deploy SVM based anomaly detection models using OML4Py in Oracle Analytics Cloud, it’s time to apply this knowledge to your own datasets. Here are a few steps you can take:
- Experiment with Different Datasets: Try using different datasets to see how SVMs perform in various scenarios. Adjust the parameters and observe the results.
- Optimize Parameters: Fine-tune the svms_outlier_rate and other model parameters to improve the accuracy and reliability of your anomaly detection.
- Explore Other Algorithms: While SVMs are powerful, explore other anomaly detection algorithms available in Oracle Machine Learning to find the best fit for your data, such as Isolation Forest, DBSCAN, or Autoencoders.
- Share Your Findings: Connect with other data analysts in the Oracle Analytics Community and share your experiences and insights.
![]()
