Generative AI adoption is trending, and Fortune 500 leaders are eager to create adoption plans for their enterprise. This post is the second of a five-part series that equips you to harness generative AI’s potential effectively. In this blog post, we dive into key approaches to optimize the response from large language models (LLMs) for your application.
Although LLMs might appear magical in their capabilities, their results can sometimes be underwhelming or even unimpressive when they fail to meet the expectation. You can take several measures to maximize their effectiveness and achieve better outcomes for different use cases. In this article, we discuss four key techniques for optimizing LLM outcomes: Data preprocessing, prompt engineering, retrieval-augmented generation (RAG), and fine-tuning. To illustrate the application of these concepts, we include customer case studies demonstrating the effectiveness of these methods.
Data preprocessing
Important text data can be embedded within various file formats, accompanied by redundant or unnecessary information. Before utilizing LLMs, preparing the data first is often necessary so that you can provide the LLM with the required context to complete the desired task. This preparation might involve tasks such as converting PDFs to text, extracting text from images, and extracting relevant sections from large documents where necessary. Preprocessing the text can further enhance its cleanliness, making it more conducive to experimenting with an LLM and laying a strong foundation for utilizing the full potential of the LLM.
Requests for proposals (RFPs) are a common type of document stored within Oracle Construction and Engineering solutions. They contain information about construction projects and the scope of work that construction companies can bid on. These documents are usually received in PDF format. Using the Oracle Cloud Infrastructure (OCI) Document Understanding service, you can easily convert these PDFs to text using optical character recognition (OCR) and ML.
When you experiment with a LLM, providing only the information necessary to complete a task is helpful. Sending more concise data to the LLM can improve results, lower latency, and speed up inference times. For example, RFPs can range from compact 10-page documents to expansive 100-page-long manuscripts. This length doesn’t fit in the context window limits of most LLMs. To address this issue, you can either truncate the text to fit within your LLM’s context window or employ document chunking techniques to breakdown your document into parts.
Let’s consider the task of extracting certain dates and deadlines from the RFP. You might face difficulties because dates are usually presented in diverse, nonstandard formats and might be referred to using different labels that mean the same thing. Regular entity extraction models, such as pretrained spaCy models, tend to be insufficient for this task. For our date extraction use case, partitioning the RFP document into sections and then pinpointing the sections with abundant date references, using rule-based entity detection and named entity recognition (NER), and passing only those relevant sections to the LLM results in a more precise date extraction from RFPs. By reducing the amount of context to what’s necessary, we can improve the LLM’s ability to pinpoint the most important data, enhancing its performance. This reduction is especially useful when dealing with large documents that can’t reasonably fit into the LLM’s context window. The following example illustrates this use case with correct responses in green and incorrect responses in red.
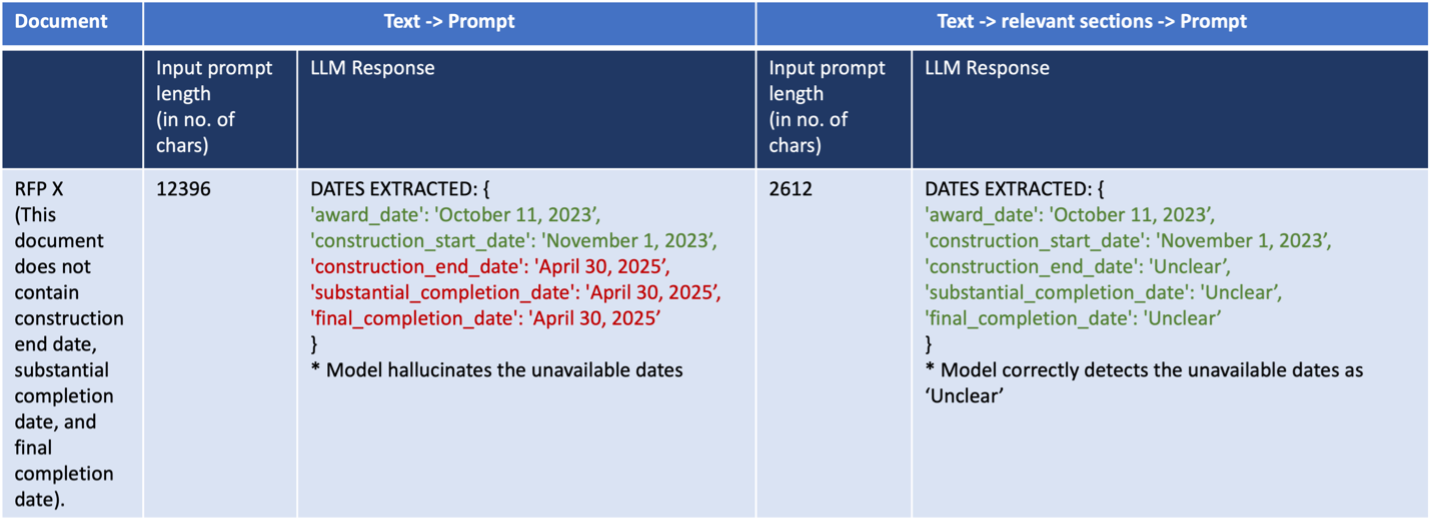
In-context learning and prompt engineering
Although the responses from a generative AI LLM model might seem promising, they might not always fulfill the required technical objectives. To improve the performance of the LLM for your specific use case, experimenting with different prompts within the context window is vital. Known as in-context learning, this process can significantly enhance the quality of the responses generated by the model. Try the following approaches:
- Ask the same question differently: Have you ever rephrased your search queries multiple times when using the internet, hoping to get more relevant results? Similarly, when asking questions to an LLM, phrasing your question in different ways can help the LLM provide you with better answers. Experiment with various versions of your question and see if the AI’s response starts to match what you’re looking for.
- Use a prompting technique: Methods including persona definitions, chain-of-thought prompting, ReAct, and others can support a LLM in comprehending the thought process behind generating a response. These techniques aid in outlining the steps undertaken to arrive at a response, and a LLM can witness this exemplar within the context window and subsequently attempt to provide answers to your queries following a similar sequential methodology.
- Zero-shot, one-shot, and few-shot learning: When you provide the LLM with examples, it helps improve its responses. Zero-shot learning refers to when you ask a question without providing any examples of prompt-completion pairs in the input to the LLM’s context window. In this case, the LLM answers based on its existing knowledge and understandings. On the other hand, one-shot learning requires you to give the LLM one example of a prompt-completion pair to provide more context. If you give the LLM multiple examples, this process is known as few-shot learning.
The following example shows obtaining the wanted response using few-shot learning for extracting most relevant feature codes from a document:

When you implement these techniques incrementally or in combination, you should start to see improvements in the LLM’s responses. If after five- or six-shot learning, you feel that the responses are showing promise but still fall short of your requirements, you might want to consider other approaches.
Retrieval-augmented generation (RAG)
RAG optimizes LLMs to generate more accurate responses by using external or custom knowledge bases that serve as authoritative fact-checking sources. RAG is useful when your goal is to augment the LLM’s existing knowledge base to apply its capabilities on custom data sources rather than give it any new or different core capabilities. It gives models sources to cite, which helps build trust with users by allowing them to fact-check claims made by the model. It helps reduce the chances of the model making wrong guesses or hallucinating.
RAG is a very powerful approach and can help overcome LLM challenges, such as knowledge-cut off. Because LLM operates solely based on the information it has been trained on, it can’t be retrained frequently because of the enormous computational power requirements. RAG helps address this issue and provides a mechanism to improve LLM’s performance.
Let’s consider the example where an Oracle Construction and Engineering user wants to ask questions about the RFP document and receive relevant answers. Providing the entire document as input to the LLM alongside the user’s question, which might only be pertinent to one or more small sections of the document, can lead to less accurate results. The LLM might become confused by the excessive context.
Instead, by using RAG, we can create embeddings for each section of the document. Subsequently, we can ask the RAG model questions, and it can identify the sections of the document that are most relevant to the user’s query. This process ensures that only the most pertinent information is added to the model’s context, resulting in more accurate responses.
The following example shows the RFP document shared with the LLM in context with the question, yielding less accurate responses, versus the RAG approach the yielding the correct responses:

Another use of RAG is in search application to locate answers to user questions that can be spread out across various documents. The system compiles relevant results and creates a single response for the user with a list of sources that contained the information. This method is useful when answers to questions are scattered in different places, and it helps provide transparency in the search process.
Fine-tuning
Fine-tuning entails tailoring a LLM for a specific purpose and calibrating it to excel at a particular task or set of tasks. Suppose your LLM demonstrates potential but still falls short of your expectations for your requirement. In that case, the fine-tuning process involves presenting the LLM with numerous prompt-completion examples specific to your use cases and adjusting the weights of the LLM in a way that enhances its performance on your prompt-completion pairs. Weights are an essential part of the inner workings of a LLM that influences the model’s predictions. The resultant LLM is now customized to optimally handle your task.
Because fine-tuning requires recomputations of LLM weights, it can be a very resource-intensive operation. Techniques, such as parameter efficient fine-tuning (PEFT), help limit the weights that get updated in the fine-tuning process. This technique helps retain a large majority of the benefits of fine-tuning while bringing down time and costs drastically. PEFT techniques, such as LoRA, are popularly employed for efficiently fine-tuning LLMs.
For example, let’s consider the goal of summarizing chat logs, where the chat is used to support and debug issues faced by users of Company X’s products. This data is highly domain-specific, and most LLMs don’t understand the jargon commonly found in the data with domain-specific nuances. If in-context learning doesn’t meet the expectation, fine-tuning a LLM for this specific use case can yield much better results and significantly improve the performance compared to using a default model.
OCI has designed more flexible and cost-efficient fine-tuning methods within OCI Generative AI Service. Read the First Principles: Exploring the depths of OCI Generative AI blog for a technical deep dive into these fune-tuning upgrades for enterprise efficiency.
Conclusion
LLMs have a wide range of applications and hold great potential. To get the most out of the LLM, finding the best approach for your application is important. Methods like data preprocessing and prompt engineering might be sufficient for some tasks. However, for more complex applications, RAG is a useful technique that allows you to use your own data sources with LLM capabilities, such as for Q&A. In some cases, fine-tuning is necessary because the LLM might not be able to perform certain tasks with its current capabilities.
Many more techniques are well-suited for completely different scenarios, such as Program-Aided Language (PAL) model for generating programs as reasoning steps. This space is rapidly expanding, and we recommend experimenting with different approaches, starting from the simplest and gradually moving to more complex ones.
Read part 1 of this five-part blog series – “Navigating the frontier: Key considerations for developing a generative AI integration strategy for the enterprise”
Read part 3 of this 5-part blog series – “Beginner’s Guide to Engineering Prompts for LLMs”
Read part 4 of this 5-part blog series – “Finetuning in large language models”
If you’re new to Oracle Cloud Infrastructure, try Oracle Cloud Free Trial, a free 30-day trial with US$300 in credits. For more information, see the following resources:
- Build your own RAG solution using Generative AI Agents
- Generative AI at Oracle
- Check out the First Principles blog on exploring the depths of OCI Generative AI Service
- Oracle AI
- OCI AI Services
- OCI Data Science
