Executive Summary
Enterprise agents do not fail like APIs. They fail across trajectories: plans, retrieval results, tool calls, policy decisions, recovery loops, budget trips, and external side effects. For these systems, observability cannot stop at logs, metrics, and request traces. It must produce decision-grade evidence, not merely telemetry.
Enterprise GenAI is moving from isolated model calls to systems that plan, retrieve, use tools, update memory, coordinate with other agents, and act against enterprise systems. That shift changes what observability must prove. In traditional software, a request trace can often explain what happened; in an agentic system, the primary unit of observability is the agent episode: the path from intent to outcome across model calls, retrieval snapshots, tool decisions, memory access, guardrail checks, recovery behavior, evaluator verdicts, budget events, and side effects.
A useful trace must explain not only what ran, but whether the run was authorized, evaluated, safe, cost-bounded, reproducible, and auditable.
Enterprise AI observability should become a durable evidence spine that makes agent episodes traceable, evaluable, debuggable, auditable, and governable without turning observability into the policy engine, eval orchestrator, runtime budget controller, approval workflow, or remediation system.
In short: observability generates evidence; runtime systems take action.
The Evidence Lifecycle: Capture, Score, Decide
A useful way to think about agentic observability is through a simple lifecycle:
- Capture: Agent telemetry is converted into trace-linked evidence: model calls, retrieval, tools, guardrails, budgets, side effects, and eval verdicts.
- Score: A Trace Integrity Score determines whether the trajectory is complete enough for debugging, release gating, RCA, or audit export.
- Decide: Guardrails, evals, budget controllers, approval systems, and security monitors consume trace-linked evidence and emit decisions back into the same evidence spine.
This is the difference between a dashboard and an evidence substrate. A dashboard shows symptoms. An evidence spine proves what happened, why it happened, whether it was allowed, and what should change next.
A Concrete Example: The Billing-Update Agent
Consider a customer-support agent that receives a request to update a billing record.
The agent interprets the request, retrieves policy context, checks memory for prior case history, and prepares a tool call to the billing system. Because the action is financial and irreversible, a boundary decision requires approval before the tool can execute. After approval, the tool updates the billing record, the system verifies that the external side effect occurred, and an evaluator verdict records whether the task satisfied the outcome rubric.
A conventional trace might show only a model call and a billing API call. That is not enough.
A decision-grade trace should show the agent intent, active policy version, prompt and tool hashes, retrieval context, approval reference, side-effect verification, eval verdict, and cost/latency outcome.
With the evidence-spine model, the episode becomes a linked trace:
turn.start
model.response
retrieval.snapshot
memory.read
boundary.enforcement
approval.grant
tool.call.request
tool.call.result
side_effect.verified
budget.consume
judge.verdict
turn.endIf the customer later disputes the action, the system can export an Evidence View containing the trace graph, artifact hashes, policy version, approval reference, side-effect verification, evaluator verdict, and integrity manifest.
Design implication: The point is not just to observe the agent. The point is to make the agent’s behavior defensible.
A Five-Plane Architecture for Decision-Grade Evidence
A production-grade observability architecture for agentic systems should separate five concerns: control, instrumentation and ingestion, evidence and storage, processing, and analysis and debugging. These planes describe how agent runtime signals move from raw telemetry to validated traces, then to durable evidence, derived analytics, and operator decisions.
The figure below shows the architecture as an evidence pipeline. The Control Plane governs the full lifecycle. The downstream planes progressively convert agent activity into evidence products: a validated trace stream, Evidence Views, derived evidence, and operator decisions.
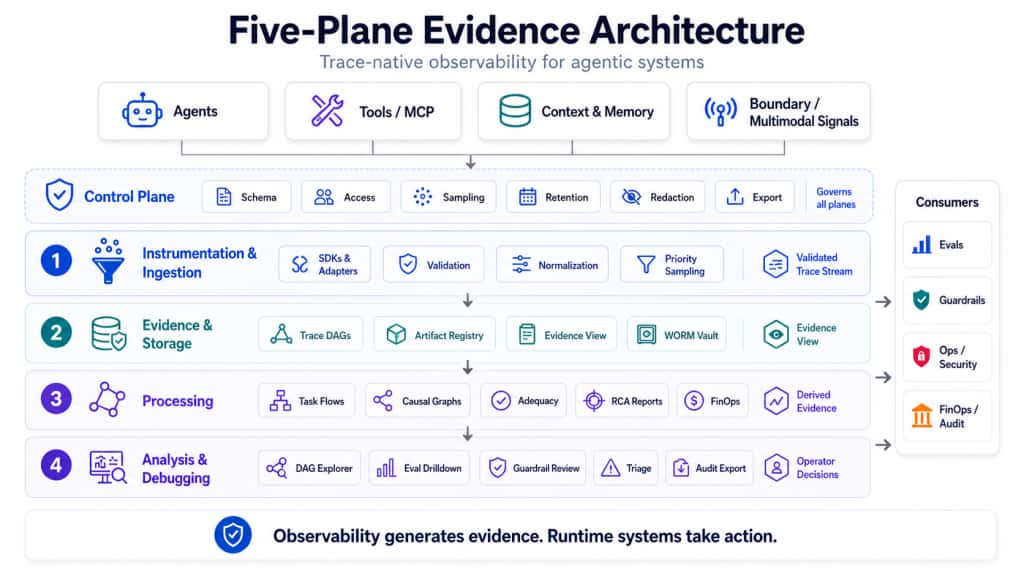
Figure 1. Five-Plane Evidence Architecture for Agentic AI. A trace-native observability model converts agent runtime signals into validated trace streams, audit-grade evidence, derived analytics, and operator decisions – while keeping observability focused on evidence generation and runtime systems responsible for action.
1. Control Plane
The Control Plane defines the rules of observability: schema governance, tenancy, sampling, retention, redaction, access policy, quotas, compliance states, and export eligibility. It determines which telemetry is valid, which payloads may be captured, which fields must be redacted, and which traces are eligible for eval or release-gate decisions.
This is what separates an enterprise evidence platform from a set of logging libraries.
2. Instrumentation and Ingestion Plane
This is where trace correctness begins. Agent SDKs and framework adapters emit spans for model calls, tool calls, retrieval, memory access, handoffs, boundary checkpoints, recovery loops, budget checkpoints, and side effects. The ingestion service validates schemas, normalizes attributes, applies redaction, enforces cardinality budgets, and records missing telemetry as an operational signal.
A trace missing a required boundary decision for a high-risk tool is not merely incomplete. It is a governance gap.
3. Evidence and Storage Plane
The Evidence and Storage Plane persists the durable record of what happened: graph-aware traces, span links, artifact references, decision records, audit events, and exportable Evidence Views.
This plane must balance auditability with data minimization. The default posture should be pointer/hash-first: prompt pack hash instead of full prompt text, tool schema hash instead of unrestricted payloads, retrieval IDs and content hashes instead of raw retrieved content, and media pointers instead of raw media by default.
For audit-grade preservation, sealed Evidence Views, export manifests, compliance-critical decision records, and audit events should be written to a WORM Evidence Vault. Hot trace stores support debugging; Write-Once-Read-Many evidence records support governance.
4. Processing Plane
Raw traces explain individual runs. Enterprises need to understand patterns across thousands or millions of runs.
The Processing Plane derives task-flow graphs, variant clusters, causal graphs, trajectory adequacy reports, guardrail effectiveness summaries, FinOps attribution, and RCA hypotheses.
This is where observability moves from “what happened in this trace?” to “which class of trajectories is failing, why, and under which release, model, policy, tool, or retrieval source?”
5. Analysis and Debugging Plane
The final plane turns evidence into operator workflows.
The system should let teams start from real triggers: a failed eval gate, guardrail spike, budget trip, security alert, customer escalation, latency SLO breach, or audit request. From there, operators should drill into affected slices, representative traces, variant clusters, suspect spans, RCA hypotheses, and exportable Evidence Views.
A good operator path looks like this:
Alert or gate failure
-> affected slice
-> representative traces
-> suspect span or trajectory pattern
-> RCA hypothesis
-> Evidence View
-> regression sample or policy updateThe Governance Perimeter: Evidence vs. Action
The most important architectural discipline is ownership clarity.
Observability must remain the evidence layer, not the runtime authority for every action. Guardrails, evals, approval systems, budget controllers, and security monitors may consume observability signals and emit decisions back into the trace. But the authority to block, approve, route, throttle, or remediate belongs to runtime or governance systems.
This perimeter matters for three reasons.
- Latency discipline: Observability should not accidentally become a synchronous policy engine on every step of every agent trajectory.
- Clean ownership: Evals own evaluation logic. Guardrails own enforcement. FinOps controllers own budget decisions. Security systems own boundary monitoring. Observability owns trace-linked evidence.
- Credible audits: The evidence layer records what each system decided, why, which version was active, and which span or artifact triggered the decision.
Principle: Observability generates evidence. Runtime systems take action.
The Non-Blocking Evidence Spine
A common concern is whether this evidence spine will slow down agent execution. It should not.
Most telemetry capture should follow a non-blocking, buffered pattern. The runtime emits span events to an in-process buffer, sidecar, OTel collector, or high-throughput stream while the agent continues execution. Durable persistence, evidence sealing, derived analytics, RCA, and audit export happen asynchronously.
| Path | Runtime behavior | Examples |
| Hot enforcement path | Synchronous only when policy requires a decision before action. | Pre-tool deny, approval check, high-risk data egress, irreversible side effect. |
| Evidence capture path | Non-blocking or buffered by default. | Model span, retrieval snapshot, tool result, budget consumption, eval verdict. |
| Evidence processing path | Asynchronous by default. | RCA, trajectory adequacy, variant clustering, audit packaging. |
The goal is not to make all governance asynchronous. Some high-risk decisions must happen before action. The goal is to ensure that audit-trail persistence and analytics do not sit on the agent p99 latency path unless policy explicitly requires synchronous enforcement.
Causal Consistency in Multi-Agent Workflows
Multi-agent systems create a harder evidence problem because no single runtime owns the full execution path. A supervisor agent may delegate to worker agents, workers may call tools asynchronously, and results may return out of order.
Without consistent context propagation, each agent emits a partial trace and the evidence spine loses coherence.
OCI should use a Global Governance Trace ID propagated across every handoff, task dispatch, tool call, memory access, and async join. Each participating agent should emit enough metadata to reconstruct the distributed trajectory: agent identity, parent agent, handoff ID, task ID, span hierarchy, span links, logical timestamps, risk tier, and deployment identity.
Logical timestamps and span links allow the system to reconstruct replayable causal execution lineage across distributed agents, even when work executes concurrently. This matters because failures often occur at delegation boundaries: unclear task handoff, lost context, conflicting tool use, repeated work, unsafe delegation, or partial completion hidden by a supervisor response.
The Trace Integrity Score should be computed over the full distributed trajectory, not just one local agent trace.
Telemetry-as-a-Contract
Agentic telemetry should be treated as a validated API, not a best-effort log stream.
| Span | Purpose |
| turn.start / turn.end | Defines the agent episode boundary and terminal outcome. |
| model.response | Records model invocation, parameters, token usage, latency, and output pointer/hash. |
| tool.call.request / tool.call.result | Records tool invocation before and after side effects. |
| retrieval.snapshot | Records RAG context: source IDs, scores, content hashes, retriever version. |
| boundary.enforcement | Records guardrail or policy-boundary decisions. |
| recovery.loop | Records retry, repair, fallback, handoff, or termination behavior. |
| judge.verdict | Records evaluator or monitor judgment linked to specific spans. |
OCI should publish an explicit Agent Observability Profile that maps OCI span names and attributes to OpenTelemetry GenAI semantic conventions and OpenInference span kinds.
Without such a profile, a system can be OTel-compatible in transport but still hard to use in external tools. The profile should define required attributes, optional attributes, schema versions, deprecation policy, sensitive-field behavior, and OCI extension namespaces.
Trace Integrity Score: Is This Trajectory Gateable?
The mandatory span contract should produce more than validation errors. It should produce a Trace Integrity Score.
Question answered by Trace Integrity. Does this trajectory contain enough evidence to support the decision being made?
A trace may be usable for debugging but not for release gating. It may be usable for aggregate metrics but not for audit export. It may be complete for model evaluation but incomplete for governance if a required boundary span is missing.
Trace Integrity should consider required span coverage, required attribute coverage, span-link integrity, artifact pointer/hash resolvability, governance span coverage, sampling and redaction declaration, and logical timestamp consistency.
Recommended outcome states:
evidence_complete
evidence_degraded
governance_incomplete
non_gateable
non_exportableThe practical rule is simple: if the trace does not contain enough evidence to support a decision, the platform should not pretend that it does.
Measuring the Evidence Spine
The success of an agentic observability system should not be measured by trace volume alone. More telemetry does not necessarily mean better evidence. The right question is whether the platform helps teams make better engineering, safety, compliance, and operational decisions.
| Metric | What it tells us |
| Trace completeness rate | Whether agent episodes contain mandatory spans and attributes required by workload type and risk tier. |
| Non-gateable trace rate | How often traces cannot support release gates, audits, or RCA because required evidence is missing. |
| Eval-to-span drilldown coverage | Whether failed evals can be traced to the exact model, retrieval, tool, guardrail, or recovery span responsible. |
| Guardrail decision traceability | Whether guardrail decisions include policy version, reason code, target span, enforcement outcome, and evidence pointer. |
| Critical-event evidence preservation rate | Whether evidence is retained for P0/P1 events: safety violations, unauthorized tool attempts, guardrail interventions, eval failures, side-effect failures, approval escalations, and budget trips. |
| Evidence export reproducibility | Whether Evidence Views can be regenerated with the same trace IDs, artifact hashes, policy versions, and integrity manifest. |
These metrics keep the system honest. They prevent the platform from optimizing for telemetry volume while failing to provide evidence that is complete, linked, reproducible, and decision-grade.
Target operating model: Every important eval failure, guardrail intervention, budget trip, side-effect failure, and high-risk agent action should be trace-linked, evidence-scored, and exportable for review.
Guardrails and Evals Belong on the Same Trace Spine
Guardrails should be represented as trace-linked decisions, not opaque middleware events.
| Observe -> Evaluate -> Decide -> Act -> Record |
The runtime guardrail system may own enforcement, but Observability owns the evidence trail: target span, policy version, detector version, decision, reason code, fail mode, enforcement outcome, and escalation reference.
Evals should follow the same principle. A judge verdict is not useful if it lives in a separate grading silo. It should be emitted back into the trace context and linked to the exact span or span range being judged.
| GateDecision -> metric -> sample -> trace -> offending span |
This turns eval failures into actionable engineering work instead of disconnected scorecards.
Advanced Evidence Modes
Once the evidence spine is stable, OCI can extend the same evidence model into advanced operating modes.
- Boundary tracing correlates agent intent with system-level effects such as shell commands, network calls, file writes, database changes, or MCP server interactions. It should be risk-tiered and opt-in because it is privacy-sensitive and deployment-dependent.
- Cognitive-surface observability captures reasoning-adjacent metadata such as plan summaries, tool rationales, confidence signals, self-check outcomes, and error classes. Raw private reasoning should remain disabled by default.
- Agentic FinOps records budget reservations, consumption, route decisions, budget vetoes, retry cost, and cost per outcome. Runtime controllers enforce budget policy; Observability explains what happened.
- Process observability and RCA discover task-flow DAGs, variation points, causal graphs, trajectory adequacy, and evidence-backed RCA hypotheses across cohorts.
- Multimodal and voice observability records media pointers, hashes, MIME types, transformation chains, detector verdicts, timecodes, and streaming metrics such as Time to First Audio or transcript confidence.
These are not separate observability products. They are extensions of the same evidence spine.
Data Governance and SRE
Agent traces may contain user prompts, retrieved enterprise content, tool arguments, PII, credentials, model outputs, memory references, media objects, and policy decisions. Observability must therefore be secure by design.
The default posture should be metadata, pointers, hashes, identifiers, scores, verdicts, and reason codes. Payload-bearing views should require explicit policy, scoped access, encryption, retention limits, and audit logging.
The service itself must also operate as a high-volume, high-cardinality, multi-tenant platform. Cardinality budgets should prevent tool arguments, user IDs, media IDs, prompt hashes, and retrieved chunk IDs from becoming uncontrolled aggregation dimensions. Sampling should preserve failures, high-risk traces, eval runs, guardrail events, budget trips, and side-effect evidence. A low global drop rate is not enough; drop-rate accounting must be broken down by priority class.
What to Build First: A Practical Adoption Path
The first milestone should not be every advanced capability. It should be the evidence spine itself.
- Make execution traceable. Define the mandatory span contract, align with OpenTelemetry/OpenInference, and validate traces at ingestion.
- Make traces governance-grade. Add Trace Integrity Score, pointer/hash-first storage, Evidence View export, and priority preservation for high-risk events.
- Make trajectories measurable and analyzable. Add eval-to-span drilldown, guardrail decision traceability, RCA hypotheses, causal graphs, trajectory adequacy, and regression sample promotion.
- Extend into advanced evidence modes. Add boundary tracing, Agentic FinOps, multimodal telemetry, cognitive-surface metadata, and side-effect verification once the core evidence model is stable.
The sequencing matters: build the evidence spine first, then expand into advanced analytics, safety, cost, and governance workflows.
Conclusion
OCI Observability for Agentic Systems should become the evidence foundation for enterprise GenAI production.
The right abstraction is not LLM monitoring and not merely distributed tracing. The right abstraction is a trace-native evidence substrate that connects runtime behavior, eval outcomes, guardrail decisions, budget controls, boundary effects, multimodal safety, and audit workflows.
The architecture is deliberately modular. Observability captures, validates, stores, derives, and presents evidence. Evals, guardrails, budget controllers, security monitors, and remediation systems integrate through trace-linked contracts. This separation keeps the platform clean while enabling a unified operational and governance experience.
For OCI, this creates a platform-level differentiation: customers can bring diverse agent frameworks, models, tools, and deployment patterns while OCI provides the governed evidence layer that makes those systems operable, auditable, and production-ready.
In the agentic era, the winning observability platforms will not be the ones that collect the most telemetry. They will be the ones that produce the most trustworthy evidence.
