An OKE-first path to better latency consistency, stronger GPU efficiency, and lower infrastructure cost
Moving a large language model from a demo to a production service changes the conversation. Teams are no longer asking only whether a model can respond; they are asking whether it can stay responsive under uneven traffic, meet service-level objectives, and do so at a cost that makes business sense. Take for example, an agentic flow where the context window keeps bloating for every run, gobbling up more memory with every added user to serve.
That is where naive inference serving often starts to break down. A common approach is to deploy a pool of identical inference replicas, spread requests evenly, and scale out when performance drops. That model is simple, but it assumes LLM traffic behaves like a typical stateless web application, which is not the case. In inference, Input prompt lengths vary; output lengths vary, cache reuse varies, and some requests are far more latency-sensitive than others.
llm-d is a popular open-source project, originally founded last year by Red Hat alongside other industry leaders, to deliver a Kubernetes-native, open source framework that speeds up distributed large language model (LLM) inference at scale. It is part of the Cloud-Native Cloud Foundation (CNCF) sandbox projects bringing Kubernetes-native distributed inference patterns to large model serving, giving teams more control over how work is scheduled and where bottlenecks are removed. For Oracle customers, the natural operational home for that model is Oracle Kubernetes Engine (OKE) running on OCI bare metal GPU infrastructure. This article details llm-d serving on OCI with AMD MI300X Instinct GPUs, its performance and getting started on OKE.
How llm-d creates business value beyond naive serving
The core business value is straightforward: better latency consistency for end users, better GPU utilization for operators, and a clearer path to hit service objectives without throwing extra hardware at the problem. TL; DR – better performance per dollar.
In plain English, prompt ingestion (prefill) and output token generation (decode) are different jobs. Prompt ingestion tends to be compute-heavy. Output Token generation is more sensitive to memory bandwidth . When the same replica must do both equally well, operators often end up overprovisioning GPU capacity just to preserve responsiveness.
llm-d changes that equation by allowing teams to separate those phases, so prefill and decode can be sized independently and optimized for their distinct characteristics. This split referred to as disaggregated prefill-decode inference—or PD for short—allows prefill workers and decode workers to serve the model differently, optimizing their specific part of the workload individually. The result is a smoother user experience, more robust serving under sustained load, and better GPU utilization. This approach has become the industry standard for production LLM inference.
PD matters most in the middle ground where enterprise applications actually live. Many customer-facing copilots, search assistants, and document workflows do not need maximum theoretical token speed for a single user. They need dependable responsiveness for many users at once, with costs that remain predictable as demand grows.
Why an OKE-first approach matters on OCI
llm-d is Kubernetes-native, so the control plane matters. Oracle Kubernetes Engine (OKE) gives teams a managed Kubernetes foundation for deploying, operating, and scaling distributed inference patterns without requiring them to build a platform from scratch. That is important for enterprises that want open components and operational familiarity but also need a service that can be run consistently across environments.
Under that control plane, OCI provides the performance foundation. OCI bare metal AMD MI300X shapes give customers access to high-memory GPU nodes, while OCI RDMA networking supports the low-latency, high-bandwidth communication needed for multi-node inference. In practice, that combination makes OCI a strong environment for the kind of distributed serving patterns llm-d is designed to unlock.
That OKE-plus-bare-metal model is also a strong operational story. It lets teams standardize Kubernetes workflows while still taking advantage of specialized infrastructure for demanding inference workloads.
What the AMD MI300X results on OCI show
Our testing on OCI was designed to answer a practical production question: Can disaggregated serving deliver better efficiency and a better user experience than aggregated serving? To answer this, we designed an experiment with 8 BM.GPU.MI300X.8 nodes (72 GPUs total) connected via RDMA over converged ethernet (RoCE v2) with eight NICs each offering 400 Gbps node-to-node connectivity. Scale testing was done for both a sparse GPT-OSS-120B model and a dense llama-3.3-70b-instruct model, serving across 2, 3, 4, and 8 nodes with different serving configurations. Results are reported for 2, 3, and 4 node serving scenarios, as these were where the optimal serving configurations were found. While all 8 nodes could be used to serve the models, the best serving configuration would be to duplicate the serving setup at 2, 3, or 4 nodes to improve throughput.
Across GPT-OSS-120B, disaggregated deployments showed clear efficiency advantages in the mid-range throughput band, where customers typically care about serving many users well rather than optimizing for a single extreme.
To generate Figure 1, sweeps were performed to measure both throughput per GPU (GPU efficiency), and throughput per user (user experience), ranging from 4 concurrent users to 512. Higher user concurrencies are represented up and to the left, while lower user concurrencies are down and to the right. The sweet spot for these sweeps lies in the middle third of this graph from the 40 to 80 tokens per second per user range for enterprise use cases. This represents an area maintaining good user experience under heavy load. In this range, disaggregated PD maintains 10-30% improvement over aggregated on identical infrastructure—only the deployment model changed.
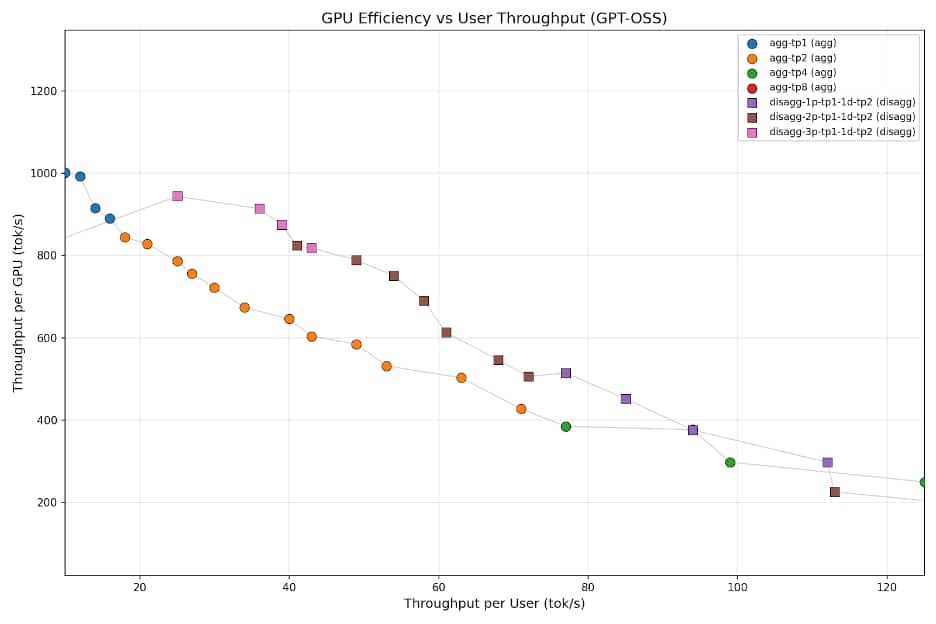
Figure 1: Pareto curve comparing aggregated vs disaggregated inference deployments for gpt-oss-120b on MI300X.
Figure 2 represents a more striking scale out result: while throughput showed reasonable improvements, latency improvements were staggering:
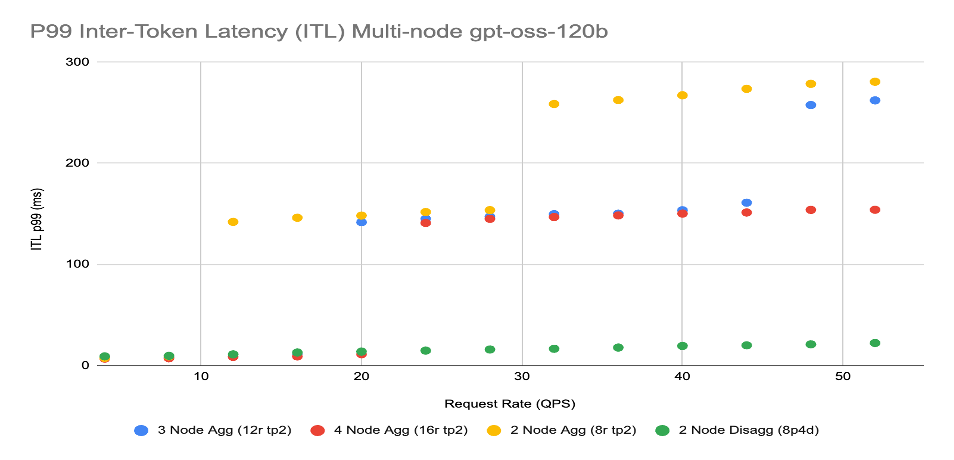
Figure 2: Scale out inter-token latency for gpt-oss-120b from 1-4 nodes with varying request rate.
As request rates scaled from 1 to 50 queries per second, a 2 node, 16 GPU disaggregated deployment remained virtually flat, outperforming a 4 node, 32 GPU aggregated deployment. This represents double the stability for half the price. Finally, Figure 3 shows that the 2 node, 16 GPU disaggregated deployment also maintained a lower end-to-end request rate than a 4 node, 32 GPU aggregated deployment:
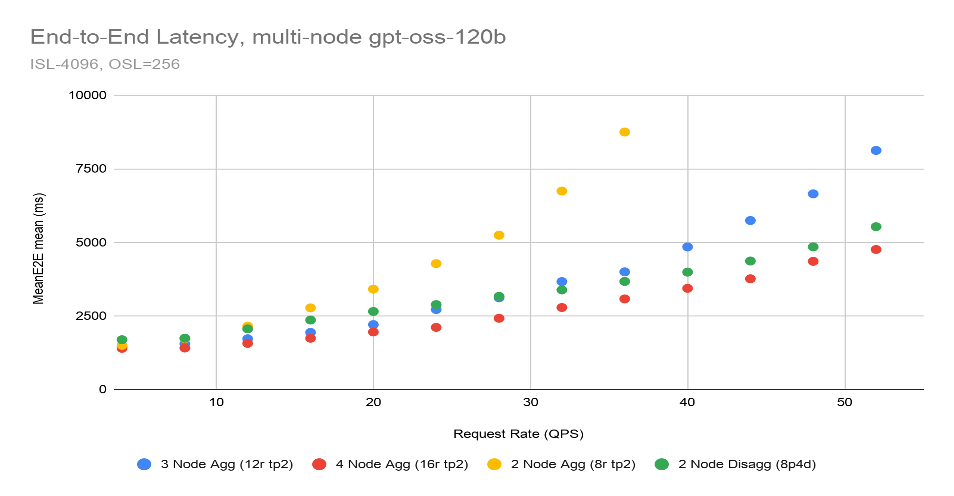
Figure 3: Scale out end-to-end request latency for gpt-oss-120b from 1-4 nodes with varying request rate.
Additional experiments were run on Llama-3.3-70B-Instruct representing a dense model architecture, which showed disaggregated configurations consistently deliver 10-38% higher throughput per GPU than aggregated deployments and better scale-out latencies. Essentially, the results were repeated on a completely different model architecture.
Ultimately, the results are clear. PD disaggregated inference enables more efficient utilization of GPUs and more consistent, reliable deployments which is exactly what enterprises need.
How Oracle is helping simplify the path
Oracle’s role in this effort is practical and customer-focused. The AMD-specific llm-d deployment guidance that now exists upstream was developed and validated on OCI compute infrastructure with collaboration between AMD, Red Hat’s llm-d team, and OCI teams with OCI providing the GPUs and OKE platform setup to do the work. Check it out here on the official llm-d GitHub.
That matters because customers do not just need benchmark results. They need a shorter path from idea to repeatable deployment. Upstream guidance such as the AMD-specific README and values files helps turn a promising architecture into something teams can actually stand up and learn from.
This is the right place for Oracle to add value in an open ecosystem: simplify adoption, validate real deployment patterns, and make it easier for customers to bring advanced inference serving to production on OCI.
What comes next for customers building on OCI
There is still meaningful room to go further. The next step is not simply more raw benchmark data. It is turning these patterns into repeatable OKE-first reference architectures for a broader set of enterprise models and workload shapes.
That includes deeper validation across additional models, more guidance for scaling mixed traffic patterns, and more automation around tuning, workload-aware scaling, and day-two operations. Over time, the opportunity is to make distributed inference on OCI feel less like custom performance engineering and more like a repeatable operating model.
For enterprise teams building generative AI services on OCI, that is the real promise of llm-d on AMD MI300X: a path beyond naive inference serving toward a platform that is more efficient, more predictable, and more production-ready.
Conclusion & Next Steps
The strongest story for customers is not a benchmark for its own sake. It is that production inference can be run more intelligently and the most cost-efficient manner. llm-d gives teams a Kubernetes-native way to do that, and OCI provides the OKE, bare metal GPU, and RDMA foundation needed to make those patterns real.
For organizations that want open infrastructure choices without sacrificing production discipline, this is a compelling path forward: deploy on OKE, run on AMD MI300X bare metal, and use llm-d to improve both responsiveness and efficiency where it matters most.
