The demand for accurate, efficient speech-to-text solutions has never been higher. Whether building customer service applications, automating transcription workflows, or enabling voice-driven analytics, enterprises need robust AI services that are simple to deploy and manage. Oracle Cloud Infrastructure (OCI) Data Science continues to advance the frontiers of AI productivity, and with AI Quick Action, deploying speech-to-text tools is easier than ever.
AI Quick Actions is an Oracle Cloud Infrastructure (OCI) Data Science feature that offers a no-code solution for customers to seamlessly manage, deploy, fine-tune, and evaluate foundation models. With AI Quick Actions, data scientists and business users alike can quickly operationalize the latest AI innovations—without writing a single line of code.
End-to-End Speech Model Support in AQUA
With the latest enhancements, AI Quick Actions now supports multiple speech-to-text models. Customers can deploy leading models like Granite Speech 3.3-8B with just a few clicks—no coding, downloading, or manual configuration required.
- No-Code Experience: Launch, manage, and evaluate speech models through an intuitive interface.
- Cached Model Availability: Popular models are pre-downloaded and ready to use, so there’s no wait time or need to access external repositories.
- Comprehensive Model Choices: Supports a wide range of popular open-source models including models for text, image, speech and more
- Enterprise Experience: All model deployment and inference stay fully within the secure OCI Data Science environment.
Deploying the Model using AI Quick Action
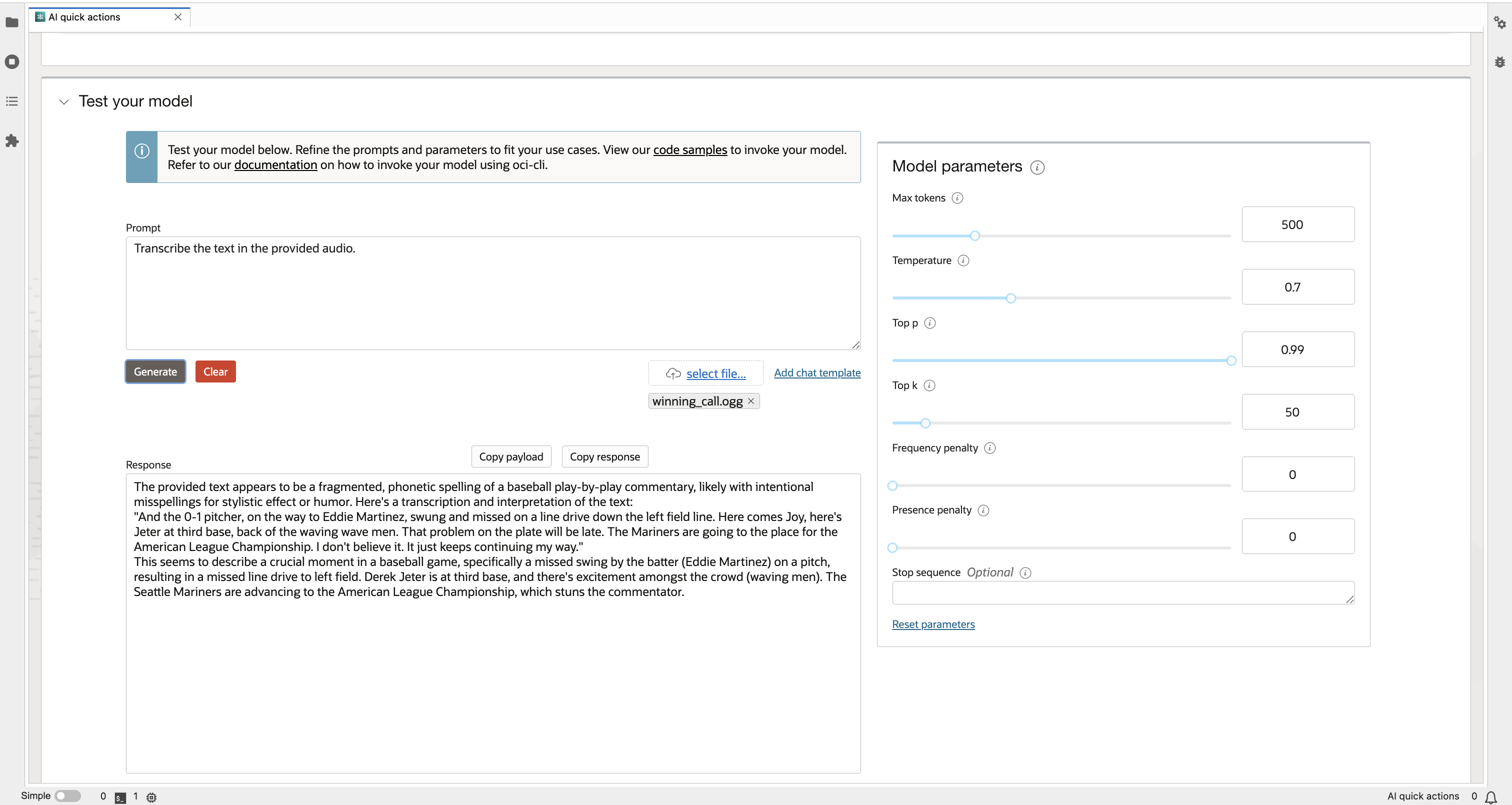
To get started, open AI Quick Actions from the Data Science Notebook and navigate to the Model Explorer. Select the Granite Speech model from the list and click Deploy. Once the model deployment is over and model is active, launch the deployed model in the Inference Playground and upload your audio file (≤10 MB).Run inference with a single click and receive your results—no manual setup, no code required.
You’ll also receive an endpoint URL for making predictions through a REST API. The deployment handles model loading, environment setup, and endpoint exposure automatically.
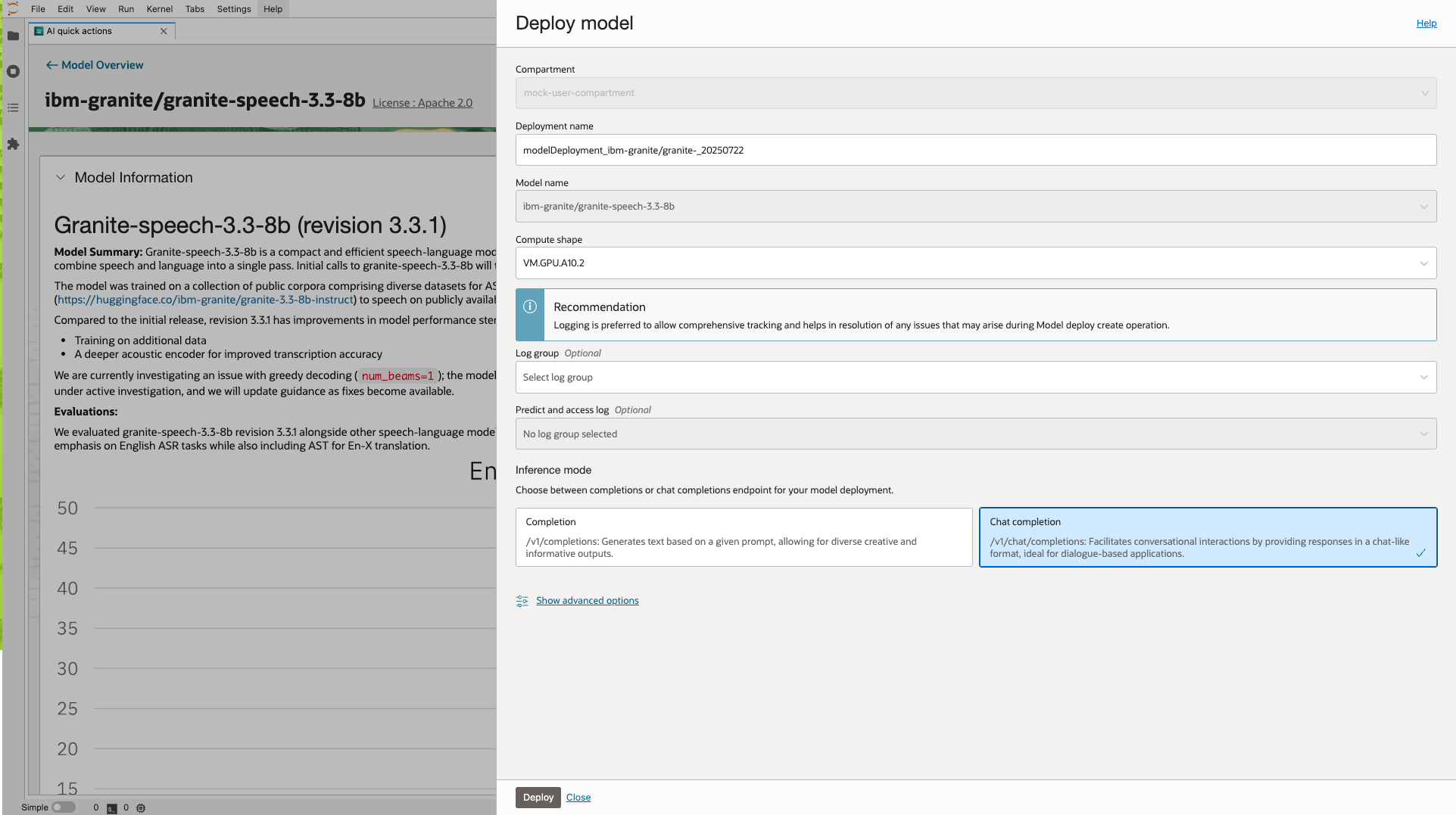
(Notes: In Model Deployment select Inference mode as Chat completion)
To make a inference request using the REST endpoint , simply send a POST request with a properly structured JSON payload.
import ads
import base64
from langchain_community.chat_models import ChatOCIModelDeployment
ads.set_auth(auth="resource_principal")
with open("provide-your-audio-file", "rb") as mp3_file:
encoded_string = base64.b64encode(mp3_file.read()).decode("utf-8")
# Provide your endpoint url here
endpoint = "https://
/ocid1.
/predict"
chat = ChatOCIModelDeployment(
model="odsc-llm",
endpoint=endpoint,
max_tokens=1024,
streaming=True
)
question = "explain the audio"
messages=[{
"role": "user",
"content": [
{
"type": "text",
"text": question
},
{
"type": "audio_url",
"audio_url": {
"url": f"data:audio/wav;base64,{encoded_string}"
},
},
],
}]
response = chat.invoke(messages)
print(response.content)
Explore:
