Oracle Cloud Infrastructure (OCI) Data Science AI Quick Actions now supports inferencing of models in GPT-Generated Unified Format (GGUF) with OCI Ampere A1 CPU shapes. OCI Data Science already supports OCI Ampere A1 in the platform, and the shape is readily available in the regions that Data Science serves. Enabling the use of A1 Ampere CPU shapes for (LLM) inferencing and retrieval-augmented generation (RAG) provides more options for our customers to work with LLMs for their use cases. For more information on using A1 Ampere in generative AI (GenAI) applications, read the blog posts, From inference to RAG: Choosing CPUs for efficient generative AI application deployments and Introducing Meta Llama 3 on OCI Ampere A1: A testament to CPU-Based Model Inference.
GGUF Models in AI Quick Actions
GGUF is a file format that compresses the typically 16-bit floating-point model weights, optimizing the use of computational resources. The methodology is crafted to simplify the processes of loading and storing models, making it a more efficient, flexible, and user-friendly option for the inference of LLMs. Llama.cpp is a framework for LLM inferencing that aims to give minimal setup and state-of-the-art performance on a wide variety of hardware. Oracle and Ampere have partnered to optimize llama.cpp to work with Ampere Arm 64 CPUs.
In AI Quick Actions, you can perform inferencing of GGUF models with our service-managed container running the OCI Ampere optimized llama.cpp with A1 shapes. We performed benchmarking with the model Phi-3-mini-4k-instruct-q4.gguf using Llama.cpp python version 0.2.78 and A1 with 40 OCPUs. A1 supports up to 80 OCPUs with performance expected to scale linearly with the number of cores. Our tests produced the following results:
| Processing architecture |
Prompt tokens |
Output token |
Inference time (Seconds) |
Token per second (TPS) |
| Arm CPU A1 with 40 OCPUs |
10 | 50 | 1.257 | 39.77 |
| 100 | 2.51 | 39.84 | ||
| 200 | 5.119 | 39.07 | ||
| 20 | 50 | 1.263 | 39.9 | |
| 100 | 2.529 | 39.54 | ||
| 200 | 5.165 | 38.7 | ||
| 30 | 50 | 1.28 | 39.06 | |
| 100 | 2.572 | 38.88 | ||
| 200 | 5.227 | 38.27 |
You can use GGUF models in AI Quick Actions in two ways. In this release, we have added two GGUF models to our service cached models: Phi-3-mini-4k-instruct-q4.gguf and Phi-3-mini-4k-instruct-fp16.gguf. These models are ready to be used without the need to download the model artifacts. Figure 1 shows the A1 configuration options for working with a GGUF model.
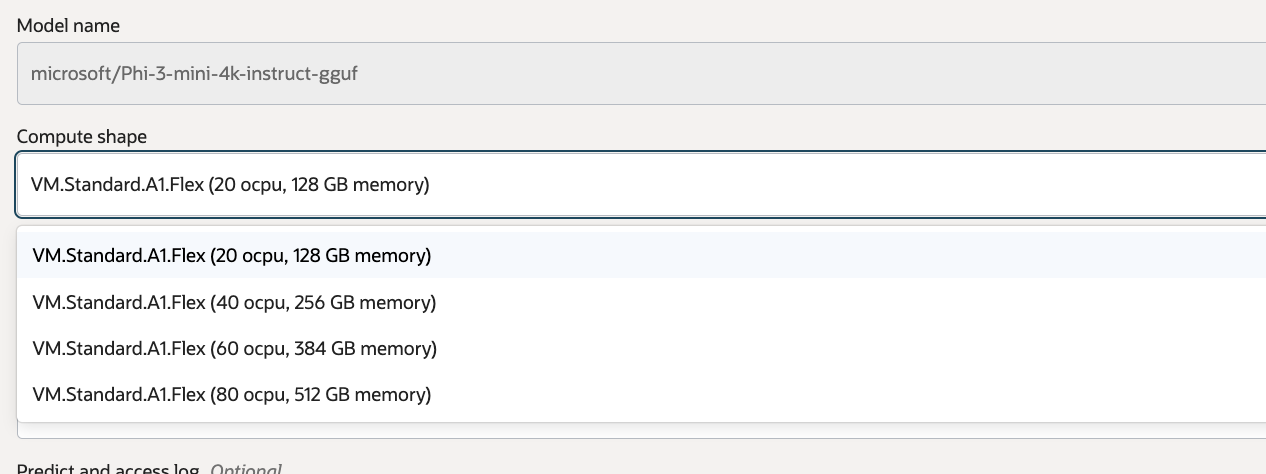
You can also choose to bring your own GGUF model into AI Quick Actions from Hugging Face. The model must first be registered in AI Quick Actions. After registering the model, when you choose to deploy the model, you can select the llama.cpp container under the Inference Container option in the Advanced Options section as shown in Figure 2.
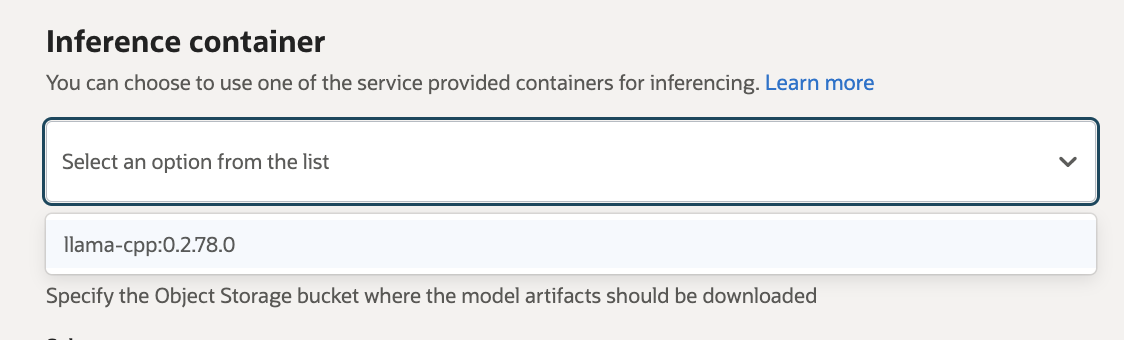
Conclusion
With the addition of Oracle Cloud Infrastructure Ampere A1 CPUs and llama.cpp framework, we broaden the options for customers to work with LLMs in AI Quick Actions.
For more information, see the following resources:
- Visit our service documentation.
- For more examples, go to OCI Data Science sample repository on GitHub.
- Watch our tutorials on our YouTube playlist.
- Try one of our LiveLabs. Search for “data science.”
- Question? Reach out to us at ask-oci-data-science_grp@oracle.com

