Meta Llama 3, the latest advancement in open-source Large Language Models (LLM), is now available for inference workloads using Ampere Altra, ARM-based CPUs on Oracle Cloud Infrastructure (OCI). Released by Meta on April 18th, Llama 3 models have been hailed as “the most capable openly available LLM to date,” offering unprecedented performance and flexibility for language processing tasks.
Back in March 2024, we explored the role of CPU in the field of Generative AI and shared promising llama 2 7B inference results on OCIs Ampere A1 Compute Shapes (see blog). Building upon the existing llama.cpp open-source project optimization, we can now support Llama 3 8B Instruct model on OCI Ampere A1 shapes with optimal results. This provides an additional proof point on the value of CPU-based inference for small (< 15B) parameter LLMs.
Performance of Llama 3 8B
Building upon the success of previous validations, OCI and Ampere computing partnered closely to further fine-tune llama.cpp for optimal performance on Ampere Altra ARM-based CPUs. Today, Ampere A1 can provide optimal support for Llama 3 8B Instruct model. Performance benchmarks conducted on OCI Ampere A1 Flex shapes demonstrate the impressive capabilities of Llama 3 8B model, even at larger batch sizes. With throughput reaching up to 115 Tokens Per Second (TPS) on a single-node configuration, the inference speeds underscore the suitability of Ampere A1 serving for production workloads. Moreover, the widespread availability of Ampere shapes across OCI regions ensures accessibility and scalability for users worldwide.
The table below details from concurrent (batch) 1 to 16 with 128 input token size and 128 output token size on a single-node OCI Ampere A1 Flex machine with 64 Oracle CPU Unit (OCPU) & 360 GB memory. The performance of Llama 3 8B is on par/better to that of Llama 2 7B on OCI Ampere A1 Flex Shapes.
| Concurrency Size/Batch | 1 | 4 | 8 | 16 |
| Throughput in Token Per Second (TPS) | 30 | 72 | 94 | 115 |
| Inference Speed (IS) per user in TPS | 30 | 18 | 12 | 7 |
See it in action
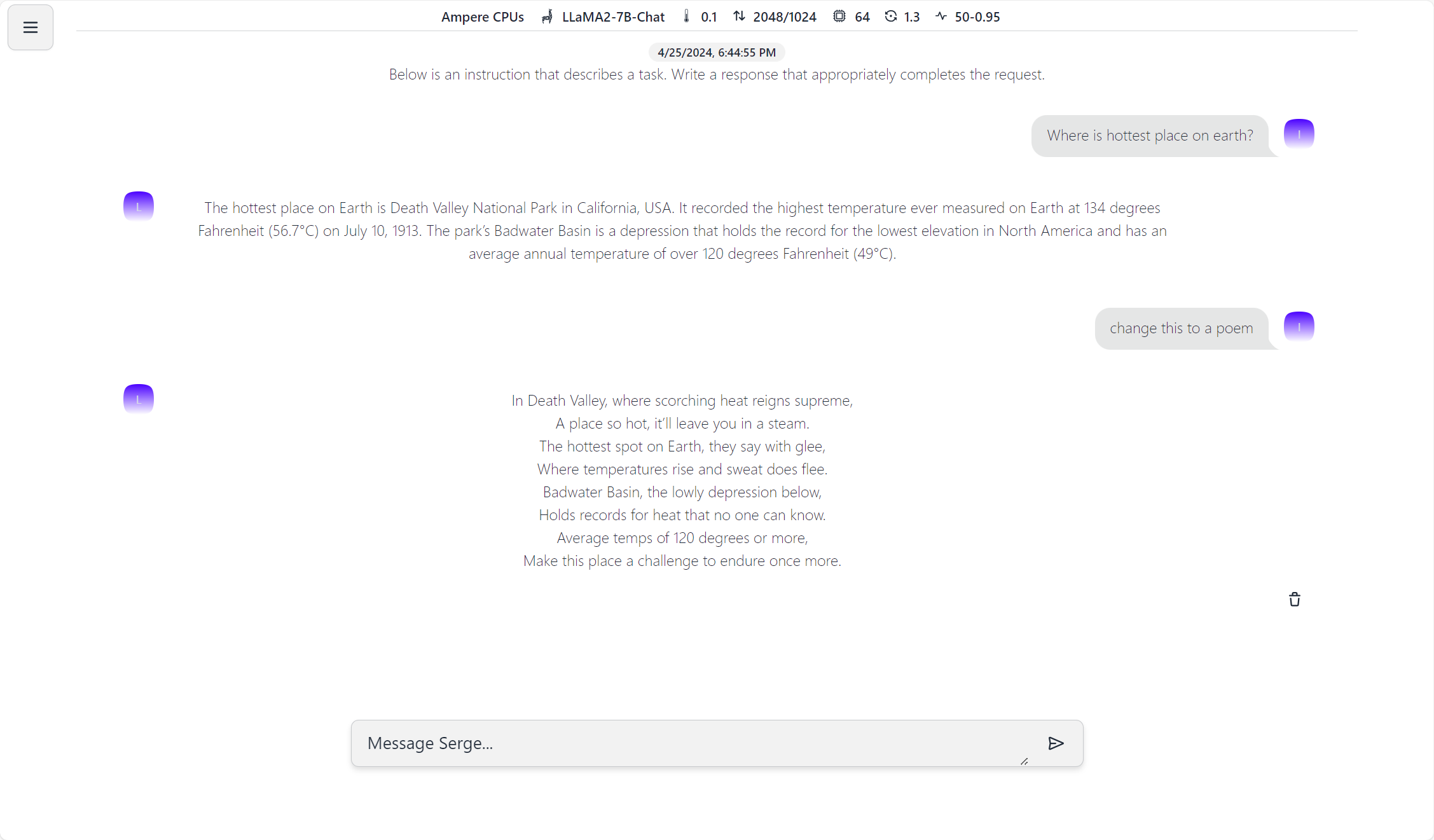
To streamline the deployment process and facilitate experimentation, OCI has introduced a custom marketplace image in OCI Marketplace, offering an easy-to-use LLM inference chatbot powered by Ampere-optimized llama.cpp and Serge UI open-source projects. This enables users to deploy and test Llama 3 on OCI with minimal effort, providing a seamless experience for both beginners and experienced practitioners alike. For more details on this deployment operating system (OS) image that is deployed in your own OCI tenancy read here.
A glimpse of the UI included with this OS image.


Next Steps
As part of our ongoing commitment to innovation, OCI and Ampere are actively working on expanding scenario support, including integration with Retrieval Augment Generation (RAG) and Lang chain functionalities. These enhancements will further elevate the capabilities of Llama 3.
If you are an existing OCI customer, get started today by launching OCI Ampere A1 LLM Inference marketplace Ampere A1 LLM Inference Getting Started Image. We are also offering free credits of (up to 3 months of 64 cores of Ampere A1 and 360gb memory) to assist with validation of AI workloads on Ampere A1 flex shapes with credits ending before December 31, 2024.
The availability of Meta Llama 3 serving with OCI Ampere A1 represents advancement in CPU-based language model inference, offering unparalleled price-to-performance, scalability, and ease of deployment. As we continue to push the boundaries of AI-driven computing, we invite you to join us on this journey of exploration and discovery. Stay tuned for more updates as we explore new possibilities to unlock Generative AI with Ampere ARM-based CPUs.
Additional References
- Democratizing Generative AI with CPU-based Inference (oracle.com)
- Ampere A1 Compute | Oracle
- Ampere A1 LLM Inference (Open-Source) – Oracle – Oracle Cloud Marketplace
