Forecasting systems become more useful when they recognize that a collection of time series is not one uniform signal.
A retailer might forecast demand for thousands of products across stores. Some products sell steadily, some spike around holidays, some are intermittent, and some respond strongly to promotions, price, or weather. An operations team might forecast compute usage across services, where one metric follows a weekly rhythm while another changes sharply after a release. In both cases, the dataset is a panel of related time series, but each series can carry a different statistical signature.
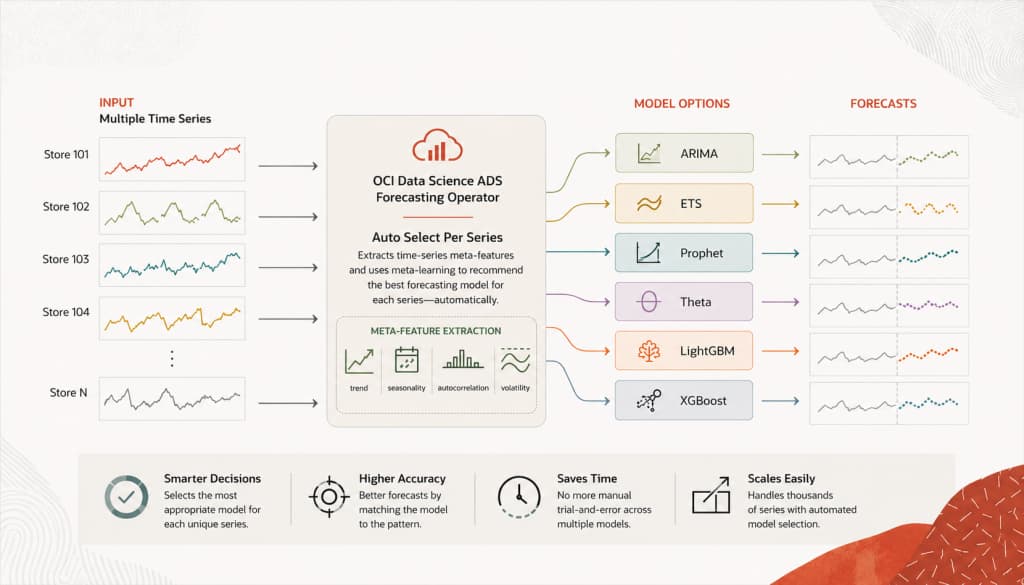
Oracle Cloud Infrastructure (OCI) Data Science provides Accelerated Data Science (ADS), whose Forecasting Operator includes Auto Select Per Series, a low-code capability that recommends a forecasting model independently for each series. Instead of applying one modeling framework to every group in a multi-series dataset, ADS extracts characteristics from each series, performs model selector inference, and routes each series to the forecasting framework that best matches its observed pattern.
This gives users a practical path to per-series model choice without manually benchmarking every algorithm for every series.

Why Per-Series Model Selection Matters
Many forecasting workloads contain heterogeneous series. Two stores can sell the same product with different demand curves. Two cloud metrics can share the same timestamp column but have very different autocorrelation and volatility. A forecasting model that works well for smooth seasonal behavior might not be the best fit for noisy, sparse, or highly nonlinear behavior.
This is why model selection is not only a configuration decision. It is also a learning problem.
In validation over a vast amount of time-series data spanning multiple frequencies, horizons, and signal patterns, the best-performing model varied across series. Some groups aligned better with classical statistical models, some with exponential smoothing style methods, some with decomposable trend and seasonality models, and some with tree-based machine learning forecasters.
The lesson is not that one framework is always better. The lesson is that the series itself carries clues about which modeling assumptions are likely to work well.
Auto Select Per Series is designed around that idea.
Introducing Auto Select Per Series
The ADS Forecasting Operator already simplifies forecasting by handling data ingestion, preprocessing, model training, backtesting, reporting, and output generation through a declarative configuration. Auto Select Per Series adds a model selection layer at the series level.
The selector can recommend one of the following supported forecasting frameworks:
arimaetslgbforecastprophetthetaxgbforecast
The feature is especially useful when:
- The dataset has many category groups, such as product, store, region, account, or service.
- Series have different lengths, seasonalities, volatility patterns, or trend behavior.
- Running every candidate model for every series would be too expensive.
- Users want model selection to stay inside the same low-code Forecasting Operator workflow.
The Meta-Learning View
A useful way to understand Auto Select Per Series is through meta-learning.
In ordinary supervised learning, a model learns from rows of data. In meta-learning for forecasting model selection, the learning unit is a time series. Each series is treated like a small forecasting task. The system describes that task using meta-features, and the target label is the forecasting model that performed best for that series during selector training.
Conceptually, the training data for the selector looks like this:
| Series Descriptor | Learning Target |
|---|---|
| Meta-features for series A | Best-performing forecasting framework for series A |
| Meta-features for series B | Best-performing forecasting framework for series B |
| Meta-features for series C | Best-performing forecasting framework for series C |
The selector then learns a mapping:
series characteristics -> recommended forecasting framework
At inference time, ADS does not need to rerun every forecasting candidate to make the recommendation. It computes the same family of meta-features for each incoming series and uses selector inference to recommend the framework.
This is the key abstraction: the system learns from prior forecasting tasks how to recommend a model for a new forecasting task.
What Are Meta-Features?
Meta-features are compact descriptors of a time series. They are not forecasts themselves. They are signals that describe the structure of the data before a forecast model is trained.
Auto Select Per Series uses feature families that capture different aspects of the series:
- Distributional features, such as length, mean, variance, skewness, kurtosis, min, max, and coefficient of variation.
- Shape features, such as trend strength, slope, curvature, nonlinearity, and last observed value.
- Dependence features, such as autocorrelation and partial autocorrelation at different lags.
- Difference-based features, which describe how the series behaves after first or second differencing.
- Stationarity indicators, which help identify whether the statistical properties of the series are relatively stable over time.
- Seasonal features, which capture recurring structure at frequencies such as weekly, monthly, or yearly periods.
- Residual-style features, which capture leftover autocorrelation after simple trend structure is removed.
- Exogenous summaries, when additional regressors are provided, such as missingness, scale, and correlation-like summaries against the target.
- Forecast context, including the forecast horizon and inferred or provided frequency.
These signals help the selector reason about model fit at a higher level. For example, a strongly autocorrelated series may favor a different modeling family than a highly nonlinear series with useful external regressors. A short, smooth seasonal series may behave differently from a long, noisy series with complex changes in level.
The goal is not to expose every statistic to the user. The goal is to let ADS build a compact fingerprint of each series and use that fingerprint to guide model selection.
Why Different Models Prefer Different Series
Every forecasting framework carries assumptions, even when those assumptions are not written directly into the user configuration.
ARIMA-style models are often useful when autocorrelation and differencing behavior provide strong signal. Exponential smoothing methods can be effective when level, trend, and seasonality evolve smoothly. Prophet-style models are designed around decomposable trend and seasonal components and can work well when those structures are prominent. Gradient boosting forecasters can be useful when lagged values and exogenous signals carry nonlinear relationships. Theta-style approaches can be strong baselines for certain trend and extrapolation patterns.
These are broad intuitions, not fixed rules. Real-world performance depends on data quality, horizon, frequency, transformations, missing values, and the available regressors. But those broad modeling biases explain why per-series selection can help: the same panel can contain series that naturally align with different model families.
Auto Select Per Series makes that alignment part of the operator workflow.
Getting Started
On an OCI Data Science notebook session, install and activate the Forecasting Operator conda environment:
odsc conda install -s forecast_p311_cpu_x86_64_v15
conda activate /home/datascience/conda/forecast_p311_cpu_x86_64_v15For local development, install ADS with the forecasting extras:
pip install "oracle_ads[forecast]"From the user’s perspective, the configuration is intentionally small. The feature is enabled in the Forecasting Operator model field:
kind: operator
type: forecast
version: v1
spec:
datetime_column:
name: Date
historical_data:
url: oci://<bucket>@<namespace>/sales_history.csv
additional_data:
url: oci://<bucket>@<namespace>/sales_additional.csv
target_category_columns:
- Store_ID
- SKU_ID
target_column: Sales
horizon: 14
model: auto-select-series
output_directory:
url: oci://<bucket>@<namespace>/forecast_output/Then run the operator:
ads operator run -f forecast.yaml The same workflow can also be invoked from Python:
from ads.opctl.forecast import ForecastOperatorConfig, operate
spec = {
"kind": "operator",
"type": "forecast",
"version": "v1",
"spec": {
"historical_data": {
"url": "oci://<bucket>@<namespace>/sales_history.csv",
},
"additional_data": {
"url": "oci://<bucket>@<namespace>/sales_additional.csv",
},
"datetime_column": {"name": "Date"},
"target_category_columns": ["Store_ID", "SKU_ID"],
"target_column": "Sales",
"horizon": 14,
"model": "auto-select-series",
},
}
config = ForecastOperatorConfig.from_dict(spec)
result = operate(config)The important field is target_category_columns. Auto Select Per Series is designed for multi-series forecasting, where ADS can identify each series from one or more category columns and make a model recommendation for each group.
What Happens During an Operator Run
At a high level, the operator follows this flow:
- ADS loads the historical data, optional additional data, and forecasting configuration.
- The operator groups the historical data into individual time series using
target_category_columns. - Meta-features are computed for each series.
- The selector performs inference and recommends a forecasting framework for each series.
- ADS groups series by recommended framework.
- Each group is trained with the appropriate forecasting implementation.
- Forecasts, metrics, and reports are merged into a single Forecasting Operator output.
For example, a single run can produce a routing pattern like this:
| Series | Recommended Framework |
|---|---|
| Store 1, SKU A | ets |
| Store 1, SKU B | prophet |
| Store 2, SKU A | xgbforecast |
| Store 2, SKU B | arima |
Users still interact with one operator configuration and one output directory. ADS handles the model routing internally.
Data Requirements and Practical Tips
The Forecasting Operator can read data from local files, HTTPS, OCI Object Storage, Oracle Database, data lakes, and any source supported through fsspec. The same data rules that apply to the Forecasting Operator also apply when using Auto Select Per Series.
For best results:
- Provide
target_category_columnsfor multi-series forecasting. - Ensure every series has enough history for the requested horizon.
- Keep timestamps consistent and sorted within each series.
- Use
additional_dataonly for variables known over the forecast horizon, such as holidays, planned promotions, pricing, or calendar features. - Include the same category columns in
additional_datathat are present in historical data. - Review the generated
report.html,metrics.csv, andforecast.csvoutputs after the run.
For example, in a retail forecasting workload, assume the forecast horizon is 2, the historical dataset might contain:
Store_ID,SKU_ID,Date,Sales
101,A12,2025-01-01,84
101,A12,2025-01-02,91
101,A12,2025-01-03,88The additional dataset might contain known future drivers, including two extra rows for the forecast horizon:
Store_ID,SKU_ID,Date,Promotion,Holiday,Price
101,A12,2025-01-01,0,0,19.99
101,A12,2025-01-02,1,0,17.99
101,A12,2025-01-03,0,0,19.99
101,A12,2025-01-04,1,0,18.99
101,A12,2025-01-05,0,1,19.99For multivariate forecasting, additional_data must cover the forecast horizon because the model needs those future values at prediction time.
Why This Is Useful for Enterprise Forecasting
Enterprise forecasting workloads are often broad, not just deep. Teams forecast across products, stores, regions, service queues, infrastructure metrics, financial accounts, and supply-chain nodes. The same organization may have fast-moving daily series, sparse weekly series, highly seasonal monthly series, and long yearly planning series.
Auto Select Per Series helps in three ways:
- It reduces manual model selection work across large panels of time series.
- It avoids forcing one modeling assumption onto every series.
- It keeps the workflow inside the same low-code ADS operator interface already used for forecasting jobs and reports.
The recommendation should be understood as a learned starting point that reflects prior benchmark behavior and series characteristics. Users should still review the resulting forecasts, metrics, and reports, especially for high-impact business decisions. The benefit is that the first modeling choice can be made automatically and consistently across many series.
Putting It All Together
Auto Select Per Series brings per-series model intelligence to the ADS Forecasting Operator. Users provide the same kind of forecasting configuration they already use in ADS, enable the feature in the model field, and let the operator inspect each time series before choosing the most suitable forecasting framework.
Behind that simple configuration is a meta-learning workflow: benchmarked historical series provide the training signal, meta-features capture the behavior of new series, and model selector inference recommends the framework that best matches each pattern.
For data science teams, this means fewer manual model selection heuristics and fewer expensive benchmark loops. For business teams, it means forecasts that are better aligned to the diversity of real-world operations. And for platform teams, it keeps forecasting model selection packaged inside the repeatable, low-code ADS operator workflow.
Explore OCI Data Science
Ready to learn more about the Oracle Cloud Infrastructure Data Science service?
- Configure your OCI tenancy with these setup instructions and start using OCI Data Science.
- Star and clone our new GitHub repo! We’ve included notebook tutorials and code samples.
- Visit our service documentation
- Read the ADS Forecasting Operator documentation
- Watch our tutorials on our YouTube playlist
- Subscribe to our Twitter feed
- Visit the Oracle Accelerated Data Science Python SDK documentation
- See another end-to-end forecasting example in the bike-sharing demand forecasting blog
- Try one of our LiveLabs. Search for data science.
