From Model Access to Governed Production
The first era of Generative AI was defined by model access.
Enterprises needed scalable inference, managed model endpoints, secure access to foundation models, and fast developer paths to experiment. That era proved an important point: organizations could bring large language models into enterprise workflows and deliver inference at scale.
But model access is no longer enough.
As teams move beyond demos and proof-of-concepts, they are hitting a different wall. The gap between a successful POC and a production-grade agent is not found in the model’s parameters. It is found in the missing Evidence and Control Layer around the model.
That layer answers four production questions: what happened and why, was it correct and safe, was this action allowed, and could we have stopped the failure before impact?
Without clear answers, agentic AI remains difficult to trust, operate, and scale.
This is becoming urgent because enterprises are moving from AI assistants that answer questions to AI systems that take actions: calling tools, invoking workflows, updating records, coordinating agents, and consuming budget dynamically. The production question is no longer only whether the model is capable. It is whether the platform can make agentic behavior observable, evaluable, governable, cost-bounded, and auditable while execution is still in motion.
The Stochastic Gap Between Prototype and Production
Traditional software is mostly deterministic: given the same code path and input, engineers can usually reason about what happens next. Production operations are built around that assumption: logs, metrics, alerts, tests, SLOs, deployment gates, and incident response.
Agentic systems break that assumption.
A single objective may branch through planning, retrieval, tool calls, retries, model switching, memory access, delegated subtasks, repair loops, and replanning before reaching an outcome — or abandoning the original path entirely.
That variability is the stochastic gap.
It is the gap between a prototype that appears to work and a production system that can be observed, evaluated, governed, cost-bounded, and audited under real enterprise conditions.
Closing that gap requires a first-class platform substrate for trace-native observability, standardized evaluations, runtime-enforced guardrails, deterministic circuit breakers, multi-agent delegation controls, and decision-grade evidence.
That is the Evidence and Control Layer: the layer that turns a black-box agent into a governed enterprise asset.
The Four Questions of Production AI
To turn experimental demand into repeatable enterprise adoption, a platform must answer four production questions natively — not as one-off sidecars built separately by every application team.
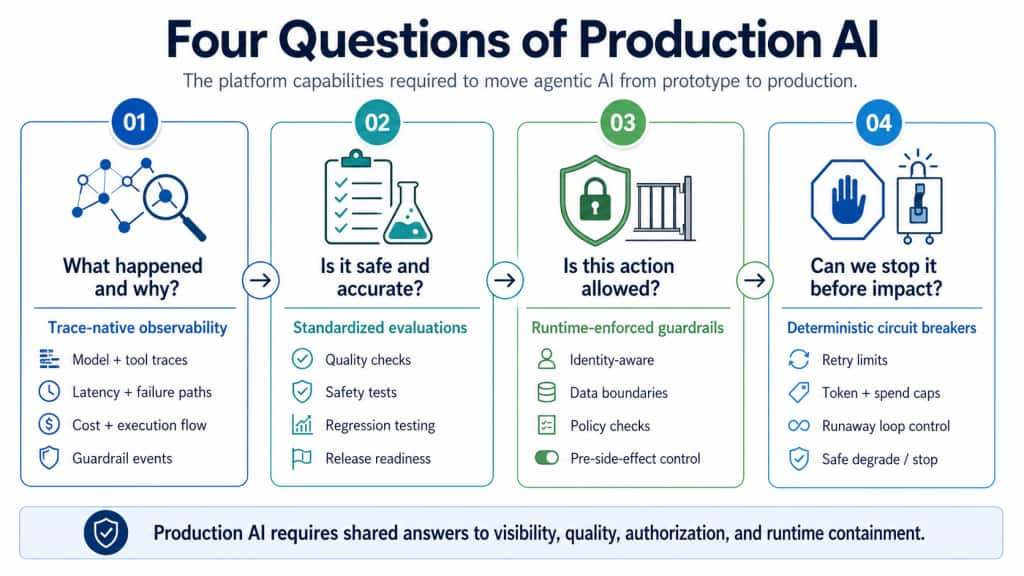
Figure 1: Four Questions of Production AI – turn governance from a fragmented application burden into a reusable platform capability.
If a platform cannot answer these questions natively, teams build fragmented governance sidecars: custom logging, one-off eval scripts, bespoke policy checks, application-specific cost controls, and disconnected audit trails.
That slows adoption and creates inconsistent evidence, enforcement, and trust.
A mature enterprise AI platform should provide the Evidence and Control Layer as a shared capability, not force every team to rebuild the operational substrate.
The Evidence and Control Layer
A mature AI strategy treats governance as a proactive, in-path control system rather than a retrospective after-action report.
The solution is not another isolated safety feature or team-specific governance sidecar. It is a shared Evidence and Control Layer that sits between agentic workloads and enterprise systems. This layer provides the visibility, evaluation, runtime decisioning, policy control, and trace-linked evidence required to move from prototype behavior to governed production execution.
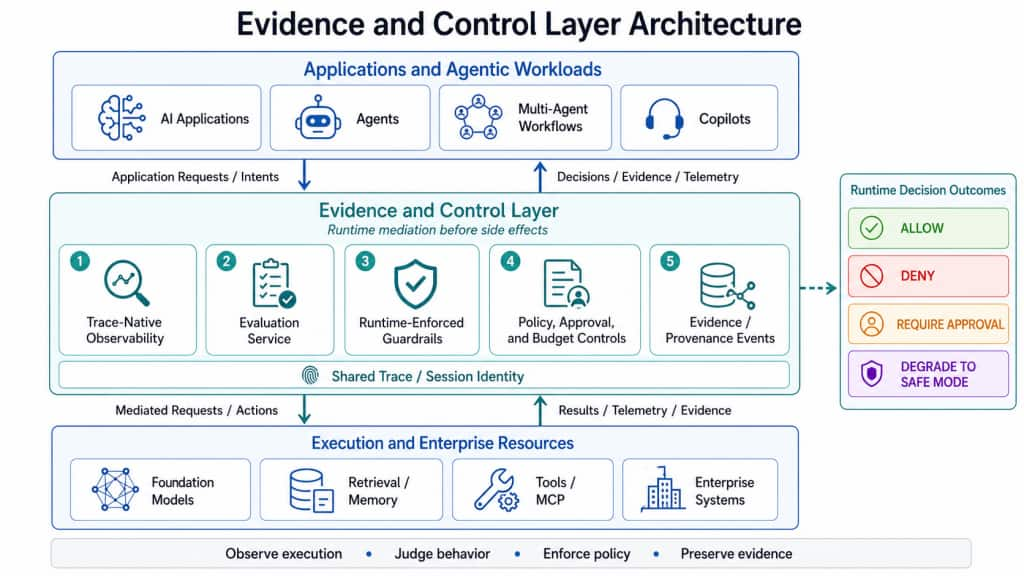
Figure 2: Evidence and Control Layer Architecture. The Evidence and Control Layer mediates between agentic workloads and enterprise resources, combining observability, evaluations, runtime guardrails, policy controls, and evidence events under a shared trace/session identity.
The architectural point is that governance is no longer an after-the-fact review step. It becomes a live execution layer. Agentic applications reach models, tools, retrieval systems, and enterprise resources through a shared boundary that both observes behavior and constrains it.
This layer has three core pillars: observability explains what happened at runtime; evaluation judges whether the system’s behavior was good enough; and runtime-enforced guardrails decide whether actions may execute before side effects occur.
Together, they form the platform contract for production AI: observe execution, judge behavior, enforce policy, and preserve evidence.
Observability: The Truth Is in the Trace
AI observability must evolve beyond simple request logging.
For agentic systems, the key artifact is the execution trace: a structured record of what the agent did, which model was called, what tools were invoked, what data was retrieved, what policies fired, what costs accumulated, where retries happened, and which runtime path led to the final outcome.
The goal is not to expose private model reasoning. The goal is to capture the execution path and decision context needed to debug, audit, and govern the system.
A log may say, “the agent called a tool.” A trace should show why the tool was called, what retrieval context preceded it, which policy checks fired, what retry path led there, and how cost accumulated along that path.
A production-grade trace should connect the user request, session identity, model calls, retrieval context, tool invocations, policy decisions, approvals, budget consumption, latency, failures, retries, delegation paths, and final outcome.
Without a shared trace model, teams see fragments. With trace-native observability, they see the execution path.
That is the foundation of operational trust.
Evaluation: The Quality Gate
Quality in agentic systems is not static.
A prompt change, model upgrade, retrieval update, tool schema change, policy adjustment, or memory behavior can shift system performance. Evaluation cannot be a one-time launch activity. It must become a continuous platform capability.
A production AI platform needs a standardized Evaluation Service for dataset-driven regression testing, rubric-based scoring, task success measurement, safety and policy checks, slice analysis, retrieval-quality evaluation, tool-use correctness, and release-readiness gates.
The key move is to link evaluation results back to traces.
When an eval fails, teams should be able to move directly to the underlying prompt, model response, retrieval context, tool call, guardrail decision, latency profile, and runtime path.
The strongest evaluation systems also turn production failures into regression assets. When a production trace fails because of a retrieval miss, unsafe tool path, policy violation, cost incident, or low-quality answer, that trace should become a candidate test case in the Evaluation Service.
Without trace-linked evals, evaluation remains a reporting layer. With trace-linked evals, evaluation becomes part of the production feedback loop.
Runtime-Enforced Guardrails: In-Path Control
The most important evolution is the shift from observational guardrails to runtime-enforced guardrails.
Many AI safety and compliance tools are observational: they detect risk, log a violation, or alert a dashboard after the system has already acted.
That is not enough for agentic AI.
Once systems can call tools, update records, move data, trigger workflows, delegate work, or spend budget dynamically, guardrails must operate in the execution path.
Runtime guardrails should evaluate a proposed action before side effects occur:
- Is the tool allowed?
- Is the destination approved?
- Is the acting identity authorized?
- Is the data boundary respected?
- Is sensitive data being exposed?
- Has the approval requirement been satisfied?
- Is the budget envelope still valid?
- Has the retry or loop threshold been exceeded?
- Is delegation allowed under the parent agent’s authority and budget?
- Should the workflow continue, degrade, require review, or stop?
If an agent proposes an external write while PII is detected, the platform should not merely alert after the fact. It should deny the proposed action at the runtime enforcement layer before data leaves the boundary.
Runtime guardrails should return explicit outcomes before execution: ALLOW, DENY, REQUIRE_APPROVAL, or DEGRADE_TO_SAFE_MODE.
The REQUIRE_APPROVAL outcome should create a controlled, stateful wait-state. When an agent is paused for review, the platform should preserve the proposed action, session state, retrieved context, policy decision, identity context, budget state, and execution trace so the reviewer can understand the request and rationale.
If approved, the workflow resumes from that controlled state. If denied or expired, the runtime degrades, reroutes, or terminates according to policy.
The goal is not to slow every workflow, but to mediate high-risk actions consistently before impact.
Runtime Controls Must Be Deterministic
Agentic systems are stochastic. Runtime controls cannot be.
A production platform needs deterministic enforcement points where policy decisions are explicit, explainable, and auditable.
Examples include degrading to safe mode after retry thresholds, denying external writes when PII is detected, requiring approval when spend crosses a budget threshold, blocking unregistered tools, terminating workflows that cannot make measurable progress, and blocking child-agent delegation outside the parent agent’s approved scope.
Multi-agent systems make this even more important. A parent agent should not be able to delegate work if the delegated action exceeds the parent’s authority, budget envelope, data scope, or approval context.
This does not eliminate uncertainty. It bounds it.
The platform does not need to predict every path an agent may take. It needs to ensure that every material action is mediated under policy, identity, approval state, data boundaries, and budget constraints.
That is the difference between hoping an agent behaves and governing what it is allowed to do.
Policy-as-Code: Making Runtime Constraints Auditable
To make runtime governance scalable, policies should be explicit, versioned, auditable, and machine-enforceable.
A runtime policy should define the target agent or workflow, the relevant guardrail type, the condition or threshold, and the deterministic action the platform should take. Examples include budget circuit breakers, data-boundary checks, retry limits, tool allowlists, approval requirements, and delegation controls.
The exact policy syntax matters less than the operating principle: policies should be explicit, versioned, evaluated at runtime, trace-linked, and auditable. Every material intervention should leave evidence.
That is how governance becomes more than documentation. It becomes execution infrastructure.
Evidence Events: Turning Enforcement into Operational Proof
A runtime guardrail is only useful if the platform can prove what happened.
Every material policy decision should emit a structured evidence event that links the proposed action, runtime context, policy version, decision, reason, and enforcement outcome.
At minimum, an evidence event should capture the trace ID, session ID, agent or workflow identity, proposed action, target tool or system, acting identity and role, data classification, policy ID and version, observed runtime context, decision, reason, runtime action, and evidence references.
This is what makes governance reviewable.
The evidence event should answer the questions that matter after an incident: what action was proposed, which policy applied, what context was observed, what decision was made, why it was made, what the platform did, and whether the decision can be replayed or audited later.
Without structured evidence, teams may know that something failed, but not why. With it, governance becomes debuggable, auditable, and continuously improvable.
Scenario: From Policy to Runtime Decision to Evidence
Consider a financial analyst agent preparing a quarterly variance summary. The agent retrieves internal financial context, identifies missing fields, and proposes writing enriched data to an external database.
Before execution, the platform evaluates the proposed action. The runtime policy detects that the tool is external_db_write, the data classification includes PII, and the workflow requires stronger approval for external writes.
The runtime guardrail returns DENY before the tool executes.
At the same time, the platform emits an evidence event containing the trace ID, session identity, proposed action, tool name, data classification, policy version, decision, reason, and enforcement outcome. This event can later support audit, incident review, eval generation, policy tuning, and root-cause analysis.
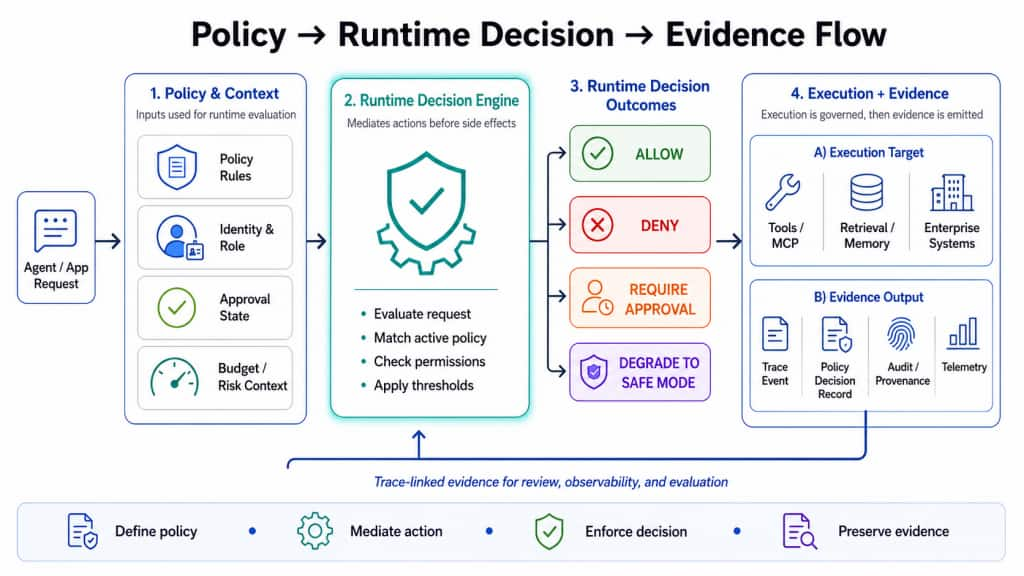
Figure 3: Policy-to-Evidence Runtime Flow. Runtime policy evaluates context, identity, approvals, budget, and risk before side effects occur, returning explicit decisions such as allow, deny, require approval, or degrade to safe mode while emitting trace-linked evidence.
Designing for Low Governance Tax
The Evidence and Control Layer must be strong enough to matter and practical enough to adopt.
The design challenge is latency, cost, and developer experience. The answer is not to put a heavy centralized check on every token or internal step. It is to enforce policy at the right runtime boundaries.
Fast-path checks should run close to the model/tool gateway using cached policy envelopes, local budget state, registered tool metadata, and precomputed admissibility decisions. Heavier evaluation, audit packaging, policy analytics, and reconciliation can run asynchronously where safe.
The invariant is simple: material actions must be authorized before side effects occur.
The Maturity Model: From Visibility to Closed-Loop Governance
The Evidence and Control Layer should be treated as a platform capability that matures over time.
| Maturity stage | Platform capability | Operating outcome |
| MVP: Shared visibility | Common traces, basic eval hooks, model/tool telemetry, and cost visibility. | Teams can see what happened and debug agentic execution paths. |
| V1: Trace-linked assurance | Standard eval service, trace-linked eval failures, release gates, and basic policy interventions. | Teams can connect quality failures to runtime evidence and block obvious unsafe actions. |
| V2: Runtime enforcement | Policy-as-code, budget and tool circuit breakers, safe-mode degradation, approval-aware execution, and evidence events. | High-risk actions are mediated before side effects occur. |
| V3: Multi-agent governance | Delegation controls, parent-child authority binding, multi-agent budget envelopes, memory boundaries, and cross-agent evidence correlation. | Multi-agent workflows are governed across authority, budget, data scope, and state. |
| V4: Closed-loop governance | Production traces become regression tests, policy thresholds are tuned from evidence, and outcomes feed roadmap and risk posture. | Governance becomes adaptive, measurable, and continuously improving. |
The goal is not to deliver every capability at once. The goal is to establish a shared substrate that can evolve from visibility to assurance, from assurance to enforcement, and from enforcement to closed-loop governance.
How to Measure Success
A successful Evidence and Control Layer should improve both trust and delivery speed. Teams should measure it like a production platform capability, not a documentation exercise.
1. Trust and Control
- Unsafe-action prevention rate: How many restricted actions were blocked before side effects occurred?
- Policy intervention accuracy: How often do runtime guardrails intervene correctly without excessive false positives?
- Governance tax: What latency or operational overhead is introduced by runtime checks?
2. Quality and Reliability
- Eval failure replay rate: What percentage of failed evals can be mapped back to a trace, prompt, retrieval context, model call, or tool action?
- Production trace to regression coverage: How many production failures become new eval or regression test cases?
- Cost incident containment rate: How often did guardrails stop runaway retries, tool loops, or spend escalation before impact?
3. Adoption and Time-to-Production
- Mean time to production for agentic workloads: Are teams moving from prototype to production faster?
- Shared control reuse: How many teams use common trace schemas, eval templates, guardrail policies, runtime hooks, and evidence interfaces?
- Governance sidecar reduction: How many application-specific logging, eval, policy, or audit implementations were eliminated?
These metrics matter because the Evidence and Control Layer is not only a governance investment. It is an adoption accelerator.
Interoperability and Platform Ownership
The Evidence and Control Layer should be platform-owned, but not platform-isolated.
It should integrate with open telemetry, tracing, evaluation, policy, and tool-integration standards where appropriate, while preserving platform-native enforcement where the runtime has the strongest context and the lowest-latency control point.
This is the right architectural split: standards-compatible evidence, shared platform control primitives, runtime-native enforcement, customer- and service-owned policy intent, and application-consumable decisions.
In practical roadmap terms, the Evidence and Control Layer should be a platform-owned shared substrate. Product teams should inherit traces, eval hooks, guardrail patterns, policy interfaces, approval flows, cost controls, and evidence schemas by default.
They should not be asked to rebuild governance one application at a time.
Strategic Impact: Accelerating Time-to-Production
A unified Evidence and Control Layer creates a gravity well for enterprise development teams.
Without a shared platform layer, every team builds its own observability, evals, policy checks, approval workflows, and audit logs. That creates duplication, inconsistent enforcement, and fragmented evidence.
A shared Evidence and Control Layer gives teams reusable defaults: trace schemas, eval templates, guardrail policies, runtime hooks, approval patterns, cost controls, and audit interfaces. The result is faster time-to-production with stronger consistency.
It also improves operational excellence. Evaluation failures, cost incidents, and policy violations can point directly to the underlying prompt, retrieval result, tool call, retry loop, identity context, approval state, or runtime decision.
And it upgrades security and compliance. Runtime guardrails move controls from model-mediated suggestions or application-specific checks into the execution path, before side effects occur.
The most serious enterprise AI risks are not always bad answers. They are unauthorized actions, unsafe data movement, overbroad tool access, excessive autonomy, uncontrolled spend, and weak evidence after the fact.
The Shift to Governed Execution
Model access, tools, and hosted runtimes enable AI adoption. But observability, evals, runtime-enforced guardrails, and decision-grade evidence make enterprise AI production-ready.
The next phase of enterprise AI platform strategy is not only about exposing more models or adding more tools. It is about building the Evidence and Control Layer that allows agentic systems to operate under policy, under authority, within budget, and with evidence.
That is the layer that closes the stochastic gap.
It turns agentic AI from a promising prototype into a governed enterprise capability — observable in execution, measurable through evals, constrained by runtime policy, and auditable after the fact.
The durable enterprise AI platforms will not be the ones that only provide model access. They will be the ones that make autonomous behavior governable at production scale.
