In this post, we will discuss different methods and metrics that we can use to evaluate LLMs.
For this study, we will use OCI Data Science to run some examples, and OCI Generative AI to consume language models hosted on Oracle Cloud.
About the OCI Data Science Service
This is a fully managed service dedicated to professionals such as data scientists, AI specialists, data engineers, and developers.
It provides a complete environment for Data Science project development, with Jupyter Notebook, AutoML libraries, pipelines for data processing, and ML model deployment.
About the OCI Generative AI Service
In this study, the OCI Generative AI service has two equally important roles:
- As the LLM model being evaluated
- As the judge model, evaluating the output of other models
But what exactly is the Generative AI service?
It is essentially a fully managed service offering a wide range of pre-trained models—from chat models to embedding models. It also allows customers to fine-tune models and deploy these customized models via endpoints.
About Machine Learning Models and Their Metrics
Since I began working with machine learning in 2014, two things have always fascinated me: the possibility of applying scientific methods to solve business problems and the metrics associated with.
It’s not just about running algorithms and generating models. There is a method: first, understand the business problem, then understand the available data, followed by data processing, and only after that do we reach model creation and evaluation. And this evaluation is based on well-defined methods.
Regression models, for example, use error-related metrics such as MSE (Mean Squared Error) and its close cousin RMSE (Root Mean Squared Error). These help determine how close predictions are to real values.
Similarly, classification models have evaluation methods such as Accuracy, Precision, Recall, and F1-Score. Each one has its role, and they often must be checked together to avoid incorrect decisions.
Even in deep learning, when we create the called black box models, there is metrics and technics to evaluate the results.
And What About Language Models?
The need to measure language model performance emerged alongside early, widely used text translation models based on statistical n-grams. One example metric from this era is BLEU, which we will discuss below. Before such metrics, evaluating translation models required expensive and slow human review.
Let’s explore some of these metrics. The timeline below shows several of them—there are many more, but we’ll focus on a few.
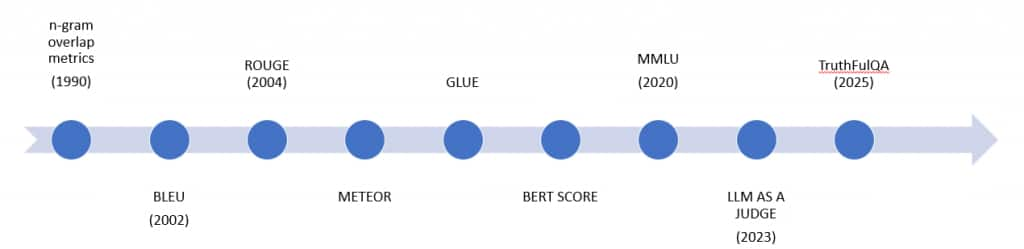
Metrics for Language Models
There are many metrics for evaluating a model from different perspectives. Here we will focus on qualitative metrics, automated ones, or those supported by LLMs. Readers should note that there are also performance metrics such as tokens per second, latency, etc.
There is enough material for an entire book.
BLEU
This metric was created to evaluate machine-generated text translations by comparing them with human-written translations. BLEU stands for Bilingual Evaluation Understudy.
It assigns a score between 0 and 1, where 1 indicates a perfect match between the generated text and the reference text. It compares n-grams to measure token overlap and applies penalties for very short outputs. It uses a reference text that is compared against a candidate.
Averages across sentences produce the final score.
Several libraries implement BLEU, such as NLTK, Evaluate, and TorchMetrics, used in the example below.
from torchmetrics.text import BLEUScore
bleu = BLEUScore()
candidates = ["this is a example"] # value to be tested
references = [["this is a example"]] # reference value
score = bleu(candidates, references)
print(f'Score BLEU: {score:.2f}')
bleu = BLEUScore()
candidates = ["this is a example"] # value to be tested
references = [["this is a diferent example"]] # reference value
score = bleu(candidates, references)
print(f'Score BLEU: {score:.2f}')
The original paper is available at https://aclanthology.org/P02-1040/
Notice that this method relies heavily on tokenization and is mostly used for evaluating translations. In the example, the first block gets a score of 1 because it is exactly the same, but you can see that the second block returns a score of 0.78 due to expected differences in the response. In the code above, I tested it with one sentence, but we can extend the test to n sentences.
BLEU is fast and computationally cheap. However, it is syntactic, not semantic, so words with the same meaning but different wording reduce the score.
MMLU
So far, we have covered BLEU method created around 2002. Let’s now move forward about 15 years and evaluate a method designed to assess the early generations of language models.
MMLU stands for Massive Multitask Language Understanding and is a benchmark created to evaluate the capability of LLMs across diverse knowledge areas. It consists of approximately 16 thousand multiple-choice questions, provided through a dataset that can be downloaded from the link:
https://people.eecs.berkeley.edu/~hendrycks/data.tar
When you extract the compressed file, you will notice that the dataset is divided into several .csv files organized by subject, which allows you to choose the specific domain you want to evaluate.
The original repository was created by Dan Hendrycks and other researchers and can be accessed at:
https://github.com/hendrycks/test
Don’t forget to also check the original paper: https://arxiv.org/pdf/2009.03300
Each test consists of a question, the available answer choices, and an answer key. The idea is to submit the question along with its options to the LLM and let it attempt to answer. Then, the model’s answer is compared against the key. Answers are always given as options like “a”, “b”, “c”, etc.
The original MMLU benchmark was created in early 2021, and much has evolved since then. Naturally, with the advancement of models, they achieve increasingly higher scores in this test, but beyond that, there is concern that evaluated models might rely on tools such as WebSearch to answer the questions or the possibility that the benchmark itself may have been leaked and included during the training of new language models.
Let’s walk through the evaluation process with MMLU using the notebook below. For this exercise, I will use two Oracle OCI services: OCI Generative AI (to consume an LLM hosted in Oracle Cloud—in this case, OpenAI GPT-4.1 Nano) and the OCI Data Science service, mentioned at the start of the article, to create the Jupyter Notebook.
Anyone who wants to run the test against the MMLU dataset can follow something similar to the example below. In this case, I chose the topic astronomy (a great passion of mine!).
import oci
import csv
#Bibliotecas para uso do langchain + OCI Generative AI
from langchain_community.chat_models import ChatOCIGenAI
from langchain_community.chat_models import oci_generative_ai
#Autenticação OCI
COMPARTMENT_ID = "ocid1.compartment.oc1..aaaaaaaacuafyhpnjnsp5luoo3dqklsdi2ysobswq3irzu664gl3cjhvcjpa"
AUTH_TYPE = "API_KEY" # The authentication type to use, e.g., API_KEY (default), SECURITY_TOKEN, INSTANCE_PRINCIPAL, RESOURCE_PRINCIPAL.
# Auth Config
CONFIG_PROFILE = "DEFAULT"
config = oci.config.from_file('config', CONFIG_PROFILE)
#Instância OCI Generative AI
# Service endpoint
#Atenção ao endpoint, porque alguns modelos estão disponíveis em regiões especificas.
endpoint = "https://inference.generativeai.us-ashburn-1.oci.oraclecloud.com"
llm_oci = ChatOCIGenAI(
model_id="ocid1.generativeaimodel.oc1.iad.amaaaaaask7dceyacxqiaijwxalbynhst6oyg4wttzagz3dai4y2rnwh6wrq", #open ai gpt 4.1 nano
service_endpoint=endpoint,
compartment_id=COMPARTMENT_ID,
provider="meta",
model_kwargs={
"temperature": 0.1,
"max_tokens": 150,
#"frequency_penalty": 0,
#"presence_penalty": 0,
"top_p": 0.75,
"top_k": None#
#"seed": None
},
auth_type=AUTH_TYPE,
auth_profile="DEFAULT",
auth_file_location='config'
)
mmlu_dataset = []
with open('mmlu_dataset/astronomy_test.csv', 'r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
mmlu_dataset.append({
"question": row[0],
"choices": [
f"a) {row[1]}",
f"b) {row[2]}",
f"c) {row[3]}",
f"d) {row[4]}"
],
"answer": row[5].strip().lower()
})
def ask_oci_model(llm, question, choices):
prompt = question + "\n"
for opt in choices:
prompt += opt + "\n"
prompt += "Answer only with the correct letter (a, b, c ou d):"
response = llm.invoke([prompt])
response = response.content.strip().lower()
for alt in ['a', 'b', 'c', 'd']:
if response.startswith(alt):
return alt
return "-"
def test_mmlu_mem(llm, mmlu_dataset):
results = []
for item in mmlu_dataset:
question = item["question"]
choices = item["choices"]
correct_answer = item["answer"].lower()
model_answer = ask_oci_model(llm, question, choices)
results.append({
'question': question,
'model_answer': model_answer,
'correct_answer': correct_answer,
'match': model_answer == correct_answer
})
return results
results = test_mmlu_mem(llm_oci, mmlu_dataset)
matches = sum([1 for r in results if r['match']])
print(f"Accuracy: {matches/len(results):.2%}")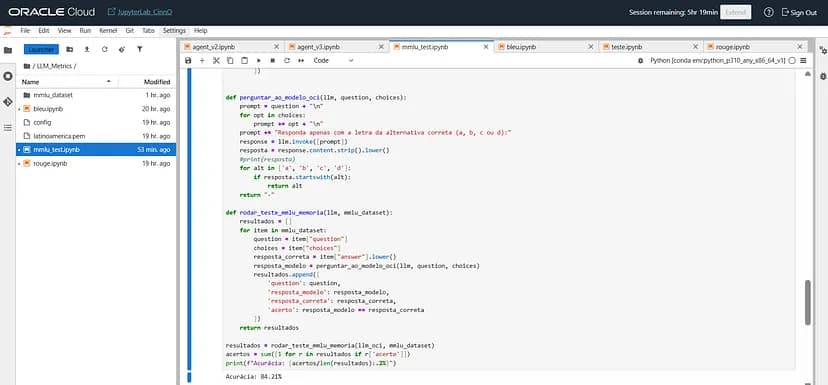
Judging LLM-as-a-Judge
All the metrics above share something in common: they are exact, meaning they count token or word overlaps. Even in MMLU, answers are fixed choices (a, b, c, d), which simplifies evaluation.
But what about open-ended responses, common in chatbots? This is where the concept of LLM-as-a-Judge appears.
The idea is to use a superior AI model, such as GPT-4, to act as an ‘arbitrator’ for subjective topics.
Another possibility is to use a Judge Model to evaluate the answers and also collect human feedback on the decision. This would be a way to measure how much agreement exists between the human and the model acting as the judge.
There are several ways to perform an evaluation:
Pairwise comparison of answers: which answer is better, given question xyz and a specific criterion.
Evaluation of a single answer: the answer is evaluated based on a criterion.
Reference-based evaluation: the answer is evaluated based on criteria and also on other references, such as content coming from RAG, for example.
Among the advantages of using an LLM as a judge, we can consider scalability, which translates into reduced human involvement in the process (although humans still need to be involved to some extent—would you really delegate the entire process to an LLM?), as well as explainability, which is extremely important when dealing with subjective matters.
#! pip install langchain_community
#! pip install oci
import oci
import json
#Libraries for OCI Generative AI and Langchain
from langchain_community.chat_models import ChatOCIGenAI
from langchain_community.chat_models import oci_generative_ai
#OCI Authentication
COMPARTMENT_ID = "ocid1.compartment.oc1..aaaaaaaacuafyhpnjnsp5luoo3dqklsdi2ysobswq3irzu664gl3cjhvcjpa"
AUTH_TYPE = "API_KEY" # The authentication type to use, e.g., API_KEY (default), SECURITY_TOKEN, INSTANCE_PRINCIPAL, RESOURCE_PRINCIPAL.
# Auth Config
CONFIG_PROFILE = "DEFAULT"
config = oci.config.from_file('config', CONFIG_PROFILE)
#OCI Generative AI Instance
# Service endpoint
# Some models can be available only in specific regions
endpoint = "https://inference.generativeai.us-ashburn-1.oci.oraclecloud.com"
llm_oci = ChatOCIGenAI(
model_id="ocid1.generativeaimodel.oc1.iad.amaaaaaask7dceyacxqiaijwxalbynhst6oyg4wttzagz3dai4y2rnwh6wrq", #open ai gpt 4.1 nano
service_endpoint=endpoint,
compartment_id=COMPARTMENT_ID,
provider="meta",
model_kwargs={
"temperature": 0.1,
"max_tokens": 600,
#"frequency_penalty": 0,
#"presence_penalty": 0,
"top_p": 0.75,
"top_k": None#
#"seed": None
},
auth_type=AUTH_TYPE,
auth_profile="DEFAULT",
auth_file_location='config'
)
#Test
reference = """
Explain how to add elements to a python list.
"""
candidates = {
"A": "Use list1.append(x) to add an final item in the end.",
"B": "You can use append or extend. Also it's possible to use insert to put in a specific position.",
"C": "To add itens in Python use list1.push(x)."
}
# --- Build Candidate blocks ---
candidates_block = "\n".join([f"{k}: {v}" for k, v in candidates.items()])
# --- Prompt to LLM as a judge ---
judge_prompt = f"""
You are a specialized and impartial evaluator.
Your task is to evaluate each candidate answer based on:
- Factual correctness
- Completeness
- Clarity
- Adherence to the prompt
- Correct use of the Python API
Return answers in the following format:
[
{{"candidate": "A", "score": 0.0 a 1.0, "justification": "short text", "issues": "issues"}},
]
Need to finalize the json correctly
reference statement:
{reference}
Candidate answers:
{candidates_block}
"""
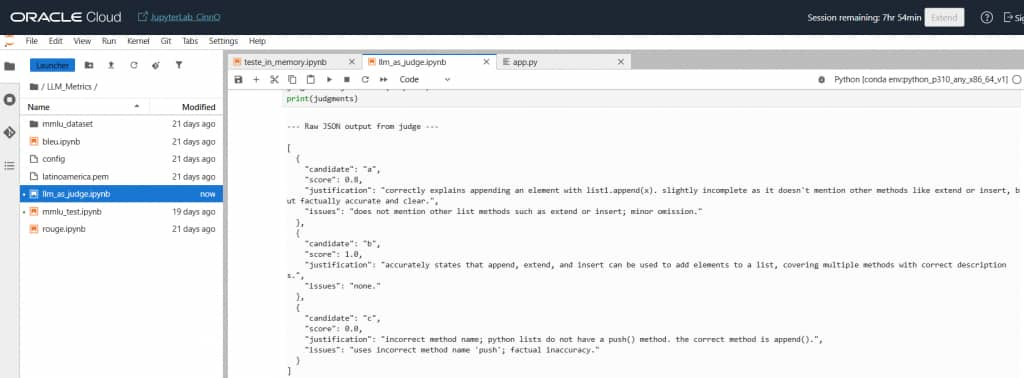
response = llm_oci.invoke([judge_prompt])
response = response.content.strip().lower()
print("\n--- Raw JSON output from judge ---\n")
print(response)
print("\n--- Como objeto Python ---\n")
judgments = json.loads(response)
print(judgments)After running this tiny test, we got some opinions from the Judge about the answers from another model, related to the question about lists in Python. You can check the answers in the image below.
Hope you enjoyed and keep studying!!!
Further Reading
The topic is extensive and constantly evolving, but I hope this article provides guidance for those studying the subject.
The notebooks used in this post can be found in my GitHub repository: https://github.com/rromanini/Data-Science-Repo/tree/master/LLM/Metrics
Recommended reading includes:
Sebastian Raschka (if you really want to understand an LLM, I recommend his book Build Large Language Models From Scratch). and his blog: https://sebastianraschka.com/blog/
OCI Data Science
https://docs.oracle.com/en-us/iaas/Content/data-science/using/overview.htm and https://www.oracle.com/br/artificial-intelligence/data-science/
OCI Generative AI
https://docs.oracle.com/en-us/iaas/Content/generative-ai/overview.htm or https://www.oracle.com/artificial-intelligence/generative-ai/generative-ai-service/
