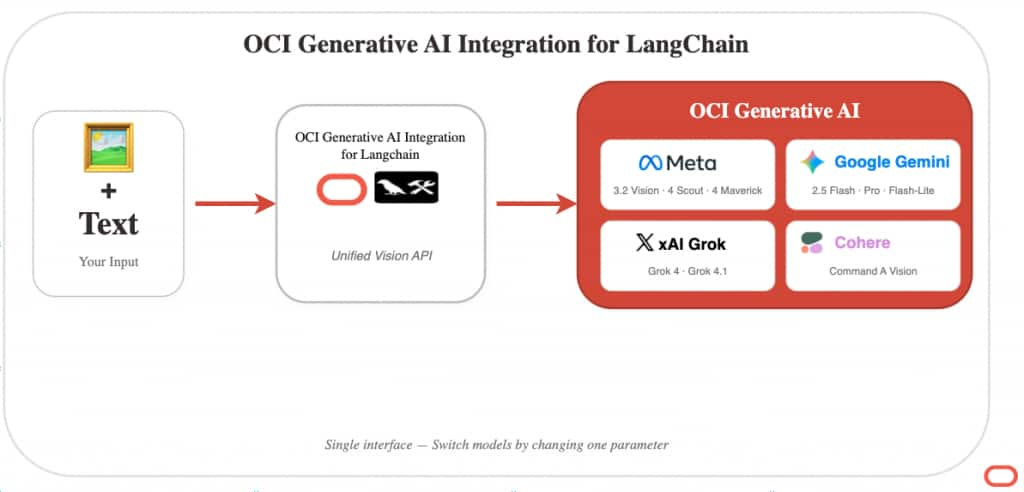
Developers building AI applications on Oracle Cloud Infrastructure can now analyze images alongside text using the OCI Generative AI Integration for LangChain. With this release, OCI Generative AI supports vision capabilities across five model providers—Meta Llama, Google Gemini, xAI Grok and Cohere —giving developers a unified interface to 13 vision-capable models through a single library. Whether you’re building document analysis workflows, visual inspection systems, or multimodal chatbots, you can now process images with the same familiar LangChain patterns you use for text.
The rise of multimodal AI
Multimodal AI—models that process both text and images—is entering mainstream enterprise adoption. According to Gartner, 40% of generative AI solutions will be multimodal by 2027. The analyst firm projects that 80% of enterprise software will incorporate multimodal capabilities by 2030. Use cases driving this growth include document processing, medical imaging analysis, quality inspection, and research acceleration.
Unlocking enterprise document workflows
For Oracle customers, this shift is particularly significant. Enterprises store decades of mission-critical documents, scanned records, and images in Oracle databases—contracts, invoices, engineering drawings, medical records, and compliance documents. Consider a legal team reviewing thousands of scanned contracts for specific clauses, or a manufacturing plant analyzing equipment photos to predict maintenance needs. These workflows, previously requiring manual review, can now be automated. With Oracle AI Database 26ai, organizations can leverage unified hybrid search that combines AI Vector Search with relational, text, JSON, knowledge graph, and spatial data for retrieval across documents, images, videos, and audio. Now, with multimodal vision capabilities in the OCI Generative AI Integration for LangChain, developers can extract insights from images and scanned documents, generate embeddings, and integrate visual analysis directly into database-driven workflows. The combination enables end-to-end AI pipelines where historical records can become searchable, analyzable, and actionable.
A unified approach
The OCI Generative AI Integration for LangChain eliminates the integration complexity by providing a single, consistent interface across all vision-capable models on OCI Generative AI. Developers write their image analysis logic once, then switch between Meta Llama, Google Gemini, xAI Grok, or Cohere by changing a single parameter—the model ID. The library handles the underlying API differences, format conversions, and authentication automatically. This means faster prototyping, easier model comparison, and the flexibility to choose the best model for each use case without rewriting code.
What’s included in this release
13 vision-capable models across four providers – Meta Llama — Llama 3.2 Vision (11B, 90B), Llama 4 Scout, Llama 4 Maverick – Google Gemini — Gemini 2.5 Flash, Pro, and Flash-Lite – xAI Grok — Grok 4 and Grok 4.1 variants – Cohere — Command A Vision (dedicated AI cluster required)
Unified multimodal interface – Use OCI Generative AI Integration for Langchain with any vision model—pass text and images together in a single message – Switch between providers by changing a single parameter – Load images from files, URLs, or in-memory bytes – Stream responses for real-time analysis of large images
Enterprise-ready integration – Full compatibility with LangChain 1.x and LangGraph workflows – Works with existing OCI authentication (API keys, security tokens, instance principals) – Combines with OCI Generative AI Integration for Langchain for end-to-end RAG pipelines over visual content
See it in action
Analyzing an image takes just a few lines:
from langchain_oci import (
ChatOCIGenAI,
load_image,
encode_image,
is_vision_model,
)
from langchain_core.messages import HumanMessage
import requests
# Vision-capable model
model_id = "google.gemini-2.5-flash"
# Optional but recommended: verify vision support
if not is_vision_model(model_id):
raise ValueError(f"{model_id} does not support vision inputs")
# Initialize OCI GenAI chat model
llm = ChatOCIGenAI(
model_id=model_id,
compartment_id="ocid1.compartment...",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
)
# ----------------------------
# Option 1: Load image from local file
# ----------------------------
message = HumanMessage(
content=[
{"type": "text", "text": "Extract the invoice number and total."},
load_image("./invoice.png"),
]
)
# ----------------------------
# Option 2: Encode image from URL or raw bytes
# ----------------------------
response = requests.get("https://example.com/document.png")
response.raise_for_status()
message = HumanMessage(
content=[
{"type": "text", "text": "Summarize this document."},
encode_image(response.content, mime_type="image/png"),
]
)
# ----------------------------
# Standard (non-streaming) invocation
# ----------------------------
result = llm.invoke([message])
print(result.content)
# ----------------------------
# Streaming invocation
# ----------------------------
for chunk in llm.stream([message]):
if chunk.content:
print(chunk.content, end="", flush=True)
Supported formats: PNG, JPEG, GIF, and WebP. For PDFs, convert pages to images first using libraries like pdf2image.
The same code works with Meta Llama, xAI Grok, or Cohere—just change the model_id.
Get started
Vision and multimodal support is available now:
pip install -U langchain-ociResources: – OCI Generative AI Integration for Langchain on GitHub — Source code and examples – OCI Generative AI LangChain Guide — Official Oracle documentation – OCI Generative AI Integration for Langchain— LangChain official docs – Oracle AI Database 26ai — Combine vision AI with Oracle AI Vector Search
References: – Gartner: 40% of Generative AI Solutions Will Be Multimodal by 2027
What’s next
With vision and multimodal support now available across Meta Llama, Google Gemini, xAI Grok, and Cohere, the OCI Generative AI Integration for LangChain provides developers a unified way to build AI applications that understand both text and images. Combined with Oracle AI Database 26ai and Oracle AI Vector Search, enterprises can create end-to-end pipelines that help extract insights from decades of stored documents, images, and records.
As OCI Generative AI continues to expand its model offerings, the integration will support new vision-capable models through the same consistent interface—no code changes required. We invite you to try it today and share your feedback on GitHub.
