
Afonso Certo
PhD Student, Institute for Systems and Robotics (Técnico Lisboa)

Rodrigo Serra
Research Engineer, Team Leader SocRob@Home, Institute for Systems and Robotics (Técnico Lisboa)

Rodrigo Coimbra
Research Engineer, Institute for Systems and Robotics (Técnico Lisboa)

Harshvardhan Jain
Generative AI Blackbelt Oracle EMEA Technology Engineering

Deepak Soni
GPU Black Belt Oracle EMEA Technology Engineering
INTRODUCTION
During the 2024 edition of JEEC (Electrical and Computer Engineering Week) – an event organized by students from the Technical Superior Institute (IST) in Lisbon, Portugal, Oracle has agreed to undergo a pilot project with SocRob@Home, a research unit from the Institute for Systems and Robotics (ISR-IST). SocRob@Home, is an initiative of ISR’s Intelligent Robots and Systems group, that focuses on solving key challenges in domestic robotics, such as human-robot interaction, sensor fusion, and decision-making under uncertainty. SocRob@Home team is currently participating in notable EU-funded projects like euROBIN and international competitions like RoboCup@Home, shaping their vision to push the boundaries of domestic robotics.
The joint pilot project aimed to enhance task and motion planning for domestic robots by integrating Oracle Cloud Infrastructure (OCI) technology with custom Generative AI tools. To support its AI/ML workloads, including training large language models (LLMs) and AI models for robot decision-making, SocRob@Home evaluated OCI’s AI infrastructure and services. The pilot tested the effectiveness of OCI for LLM fine-tuning, action tools for task execution, and GPU-powered instances for advanced AI modeling. This collaboration aimed to enhance the interactivity, adaptability, and precision of SocRob@Home’s robots, revolutionizing the scalability and efficiency of domestic robotic systems.
OCI Logical Architecture
The pilot project was implemented on Oracle Cloud Infrastructure. The solution components and general architecture diagram are shown in Figure 1.
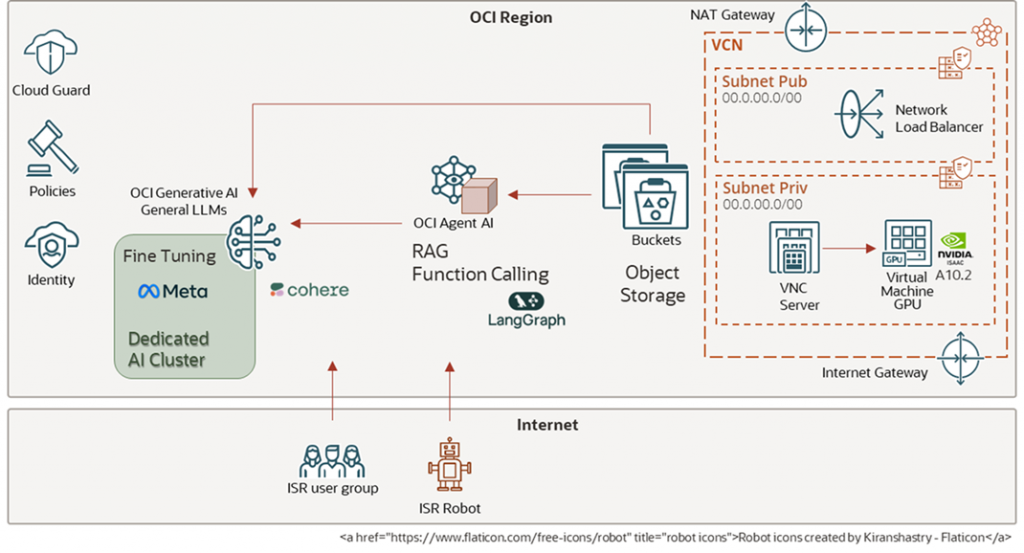
Figure 1 OCI General solution diagram.
Besides core components AI Infrastructure, Network, OCI AI agent framework and Object Storage, an additional VNC server was configured to allow the use of NVIDIA’s Isaac Lab software graphical interface.
AI-Driven Task Planning for Service Robots
Task Planning with LLMs
In robotics, the development of a General Purpose Service Robot (GPSR) has been a longstanding ambition. To build robot capable of seamlessly executing generic spoken instructions. Imagine telling a robot, “Grab me a drink,” and having it interpret, plan, and carry out that task without further input. While this vision is compelling, achieving it is far from trivial.
To fulfill such requests, the robot must go through a complex pipeline:
- Transcribe and understand the spoken instructions.
- Generate a step-by-step plan to achieve the specified goal.
- Execute actions in the physical or simulated environment.
To better describe the problem, let us use a simple example: suppose the robot receives the instruction “Grab me a drink.” To satisfy this request, the robot will execute a list of tasks (pipeline) like the one shown below:
- Find a drink.
- Pick the drink.
- Move to the person.
- Deliver the drink.
Now, let us assume the robot already knows there’s a cola soft drink can on the kitchen counter. An efficient planner would incorporate that knowledge and skip any unnecessary search, going directly to the place where the cola drink is. This exemplifies how important world knowledge and planning context are for effective execution.
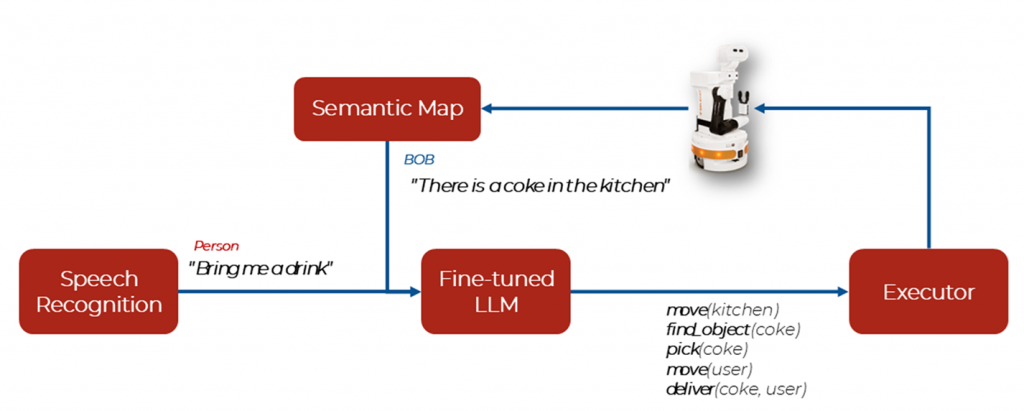
Figure 2 Previous SocRob@Home pipeline based on LLM finetuning.
The pipeline developed by SocRob@Home (Figure 2) leveraged a fine-tuned large language model (LLM) to generate these step-by-step plans. The robot BOB uses a Semantic Map – a framework that provide robots with a richer representation of their environment by augmenting spatial maps with semantic labels, enhancing their navigation capabilities while avoiding objects. Whereas this approach led to strong performance, it came with two major limitations:
- High resource cost: Finetuning LLMs requires substantial computational power and carefully curated datasets.
- Lack of interactivity: The system was one-directional. Once the plan was generated, the user couldn’t provide feedback or clarifications, and the model had no memory of prior interactions.
To address these limitations, we explored two alternative planning pipelines using OCI and their Generative AI tools:
1. Finetuning with OCI’s Llama3.3 Cluster
We replicated our original approach by finetuning a Llama3.3 model using Oracle’s infrastructure. The use of OCI Generative AI services at our disposal, including the possibility to create a dedicated AI infrastructure cluster, made it easier to scale and manage the fine-tuning process. This route aimed to test whether larger models and more efficient computation would lead to better planning quality.
2. Function Calling with LangGraph and Oracle’s Generative AI APIs
In the second use case, we explored a more modular and lightweight solution using LangGraph, a framework that enables LLMs to interact with tools in a graph-based execution flow.
Each robotic skill, such as navigate, pick, place, or deliver, was implemented as a callable tool with:
- A brief description.
- Required input arguments.
- Expected effects on the test world.
- Preconditions (e.g., find must precede pick).
This allowed the LLM to generate plans by dynamically calling these tools in sequence, without any fine-tuning. This pipeline used the cohere.command-r-08-2024 model. The workflow is showcased in Figure 3.
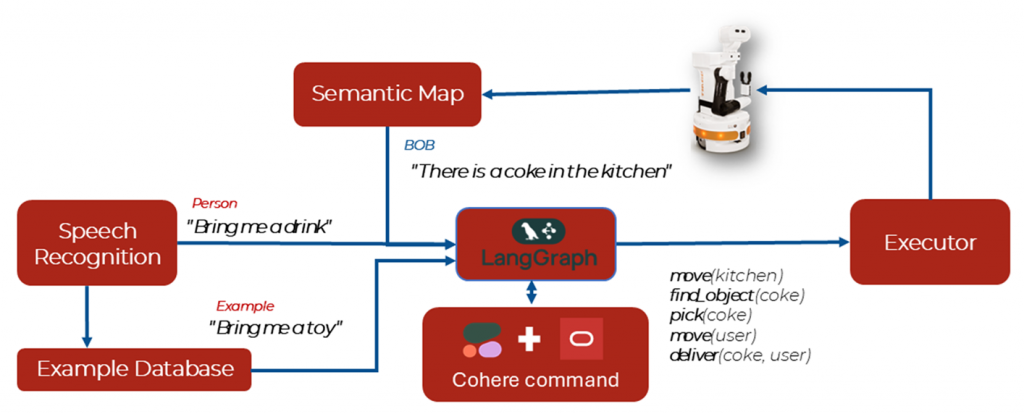
Figure 3 Modular pipeline using LangGraph and function calling.
Memory and Prompting Strategies
We enabled memory using LangGraph’s default memory mechanism, allowing the planner to retain relevant context across steps and user interactions.
Two prompting strategies were evaluated:
- Zero-shot prompting: The model is prompted directly with the user instruction.
- In-context prompting: A similar example from the dataset is included in the prompt to guide the model’s planning.
Evaluation in a Simulated Environment
To evaluate both pipelines (Zero-shoot and In-context promptings), we used a Petri Net-based simulator that models how each action affects the robot’s environment. This lets us validate whether the generated plans are both feasible and goal-achieving. The evaluation relied on two main metrics:
Execution Success Rate: The fraction of actions in the plan that can be executed, regardless of relevance to the goal.
Success Rate: The fraction of plans that result in successful completion of all goals in the simulated environment.
These metrics were evaluated using two different instruction datasets, both derived from the RoboCup@Home competition’s GPSR command generator:
- ISR Testbed Dataset: Based on the SocRob@Home testbed at the Institute for Systems and Robotics. This dataset matches the environment used during the training of the finetuned models.
- RoboCup 2024 Dataset: Based on the RoboCup@Home 2024 competition environment. This dataset introduces variations and challenges that the models had not seen during training, making it useful to test generalization.
Results
Our findings, some directly observed in Figure 4, revealed several key insights:
- Finetuning a larger model (Llama3) did not lead to improved planning success when compared to smaller models or tool-based approaches.
- However, finetuning on a dedicated AI cluster significantly improved inference speed. Planning time was reduced from ~30 seconds per instruction using an onboard fine-tuned Phi-3 model, to just ~5 seconds per instruction with the Llama3 model deployed on Oracle’s dedicated AI cluster. This speedup has practical implications for real-time interaction with users.
- The LangGraph-based function-calling approach, produced the most reliable goal-completing plans. Particularly when combined with in-context prompting.
- While the zero-shot version of this approach often produced executable actions, those actions rarely led to task success unless the model was also given a similar example in the prompt.
- By combining the LangGraph-based approach with the OCI Dedicated AI cluster, we can achieve the best of both worlds: high relevance and fast inference speed, both essential for a production environment.
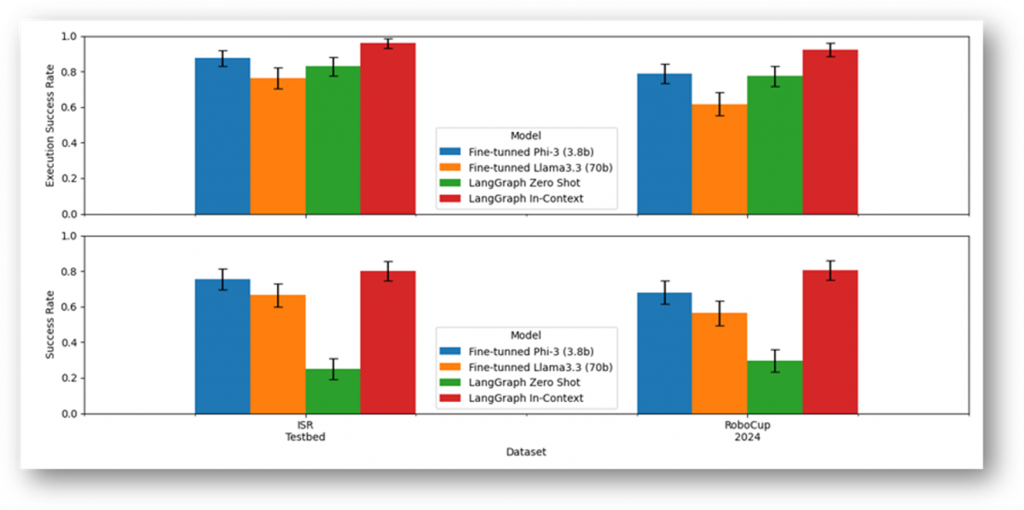
Figure 4 Comparison of finetuned models, zero-shot prompts, and in-context LangGraph planners on both datasets.
Overall, these results suggest that intelligent prompting strategies and tool integration can outperform raw model scaling alone, especially when planning needs to be interactive and efficient.
Full-body Control of a Mobile Manipulator with DRL
Mobile manipulators, which combine a robotic arm with a mobile base, are designed for advanced tasks like navigating through multiple rooms and interacting with objects. However, they face challenges in constrained and dynamic environments, particularly in navigation. Traditional control strategies separate the movement of the arm and base, leading to inefficiencies. To overcome this, SocRob@Home has proposed a solution using Deep Reinforcement Learning (DRL), where an agent learns to coordinate both the manipulator and base simultaneously for efficient, collision-free navigation, ensuring the arm is in an optimal position to perform tasks.
Simulation Environment & Reinforcement Learning Methodology
To implement our solution, we needed a simulation environment to avoid the risks associated with real-world interaction, such as collisions and unstable movements during training. To address this, we chosen NVIDIA Isaac Lab (displayed in Figure 5). A framework built on top of the Isaac Sim simulator, designed specifically for training robot policies. Isaac Lab leverages GPU-based parallelization, allowing us to run thousands of agents simultaneously, significantly reducing the time required to collect data and speeding up the learning process.
For training, we used the Proximal Policy Optimization (PPO) algorithm, an on-policy reinforcement learning method that learns from actions taken by the current version of the policy rather than from past experiences stored in a replay buffer. While PPO is more stable due to its focus on recent data, it is less data-efficient because each policy update requires generating new experiences. Isaac Lab’s ability to simulate multiple agents in parallel helps mitigate this limitation by enabling fast data collection, making it ideal for efficient training.

Figure 5: Isaac Lab enables the simulation of thousands of environments in parallel, significantly speeding up the training process. In this setup, the agent, represented by a neural network, learns by producing actions based on the state and receiving rewards that reflect the impact of its actions on the environment.
Simulations were conducted on an Ubuntu Linux virtual machine configured in Oracle Cloud Infrastructure and equipped with two NVIDIA A10 GPUs (24 GB each). The GPUs enabled us to simulate larger and more complex environments compared to our previous on-premises 3rd-party hardware setup that used a single NVIDIA 4060 Ti with 8 GB of memory.
Results
For a small number of agents, the performance improvement was minimal, likely because the GPU wasn’t the system’s main bottleneck, as illustrated in Figure 6. However, as we increased the number of agents, the benefits of the A10 GPUs became clear. The 4060 Ti struggled with scaling, showing a steep increase in simulation time, while the A10 GPUs handled larger workloads more efficiently. Moreover, the speedup of the A10s improved as the number of agents increased, allowing us to train more agents in the same amount of time.
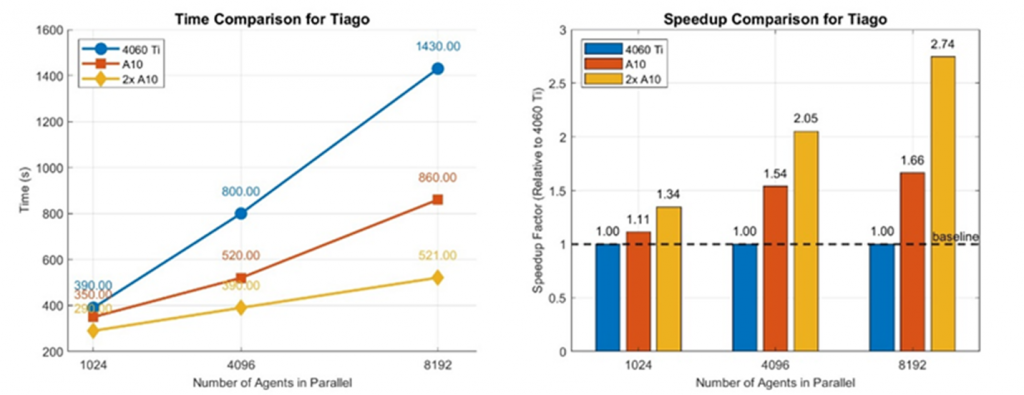
Figure 6: Simulation Time vs. Number of Agents for the task without obstacles (displayed on the right), and the Relative Speedup compared to the 4060 Ti for the same task.
This made it possible to test multiple reward functions and fine-tune the agent’s behavior more effectively. Additionally, having access to multiple GPUs enabled two training methodologies:
- Running multiple different setups in parallel (e.g., varying reward functions, architectures, etc.).
- Training a single agent with more experience data, which often improves stability and convergence, especially in complex tasks.
In the end, each of our simulations for our task took around nine hours, using 4 096 agents in parallel. Based on our experiments, this setup provided the best balance between the number of agents collecting samples and simulation time for this task.
Conclusion
This pilot project demonstrates how Oracle Cloud Generative AI tools, integrated with LangGraph, enable scalable and efficient task planning for service robots. By leveraging Oracle Cloud Infrastructure (OCI), robots can dynamically generate adaptable task plans using action tools and memory strategies, improving precision without extensive fine-tuning.
Motion planning was enhanced using Deep Reinforcement Learning (DRL) with Isaac Lab simulations on OCI’s A10 GPU-powered compute instances. This setup enabled the simulation of larger, more complex environments, improving training performance as the number of agents increased.
These results highlight Oracle Cloud Infrastructure as a transformative asset for enhancing robotic system scalability, efficiency, and interactivity, enabling more effective human-robot interaction and autonomous decision-making in domestic environments.
To learn more about Oracle Cloud Infrastructure’s Generative AI services, see the following resources:
Announcing the General Availability of OCI Generative AI Agents Platform
First Principles: OCI AI Agent Platform is a New Frontier for Enterprise Automation
