しばちょう先生の試して納得!DBAへの道 indexページ▶▶
みなさん、こんにちは。”しばちょう”こと柴田長(しばた つかさ)です。
データベースのパフォーマンス問題が発生しました。そんなとき、ほとんどのDBAの皆様がお世話になるのがAWRレポートやStatspackレポートでしょう。しかし、そこに絶妙なタッチで描かれている待機イベントや統計情報の意味が分からなければ、宝の持ち腐れになってしまいますし、問題を解決することは出来ません。AWRの読み方を教えて下さい。と言われた時、私が初めに聞くのは「知っている待機イベントや統計情報は?それらがどのような時にカウントアップする?」です。

と言うことで、今回はAWRレポートを読めるようになる為の第一ステップとして、バッファ・キャッシュ関連の待機イベントや統計情報を体験形式で学習してみたいと思います。以下の演習をOracle Database 11g Release 2以降のデータベースで試してみてください。
【今回ご紹介するネタ一覧(逆引き)】
- ✓ AWRレポートでまず確認しておくべき項目(演習1)
- ✓ ディスクからのデータブロック読込み関連の統計情報(演習3)
- ✓ 待機イベント db file sequential read (演習7)
- ✓ 待機イベント db file scattered read (演習3)
- ✓ 待機イベント direct path read (演習8)
- ✓ 索引高速スキャンによるキャッシング処理(演習6)
- ✓ バッファ・キャッシュ上にキャッシュされているオブジェクトとサイズの確認(演習4)
- ✓ event10046 のSQLトレースの取得と参照(演習3)
- ✓ Pre-Warming機能(演習5)
1. 次のAWRレポート(先頭部分だけ抜き出したもの)を確認し、キャッシュ・ヒット率が高いか否かを判断して下さい。


今回ご用意させて頂いたAWRレポートは、私のPCから引っ張り出してきたOracle Database 11g Enterprise Edition Release 11.2.0.2 のものですね。「Snap Time」をご確認頂くと、2011年の2月に取得したものだと分かってしまいます。AWRレポートはバージョンが上がるにつれて進化し続けているので少々古い感じがしますが、基本的な読み方は大きく変化はしていませんし、今回の連載で扱うバッファ・キャッシュ関連の待機イベントや統計情報を綺麗に計測出来ていたので、こちらを使って解説していこうと思います。
AWRレポートを分析する際にまずやってほしいこと。それは上記で抜粋した部分には必ず全て目を通して下さい。と言うのは、ここに全ての情報が集約されていると言っても過言ではないのです。これらの情報を見ることでおおよその傾向を掴むことが出来てしまうので、ベテランDBAの方であれば答えはサラっと出てしまうでしょう。しかし、そこをネチッこく私が解説させて頂くのがこの連載でもあるので、我慢して読んでみてくださいね。
まず、最上部でバージョン情報(Release)やReal Application Clustersのデータベースか否か(RAC)、CPUコア数(CPUs、Cores、Sockets)、物理メモリ容量(Memory(GB))と言った環境情報は、他のAWRレポートと比較する際H/W増強が行われているか否かを把握します。Memoryに関しては、Report SummaryにあるCache SizesでもSGAの設定を合わせて見ておきましょう。
次に見るのはこのAWRレポートの期間(Elapsed)であり、このレポートでは約3分間(180秒)であることが理解できます。待機イベントや統計情報の総回数を評価する際には把握しておく必要がありますし、比較する他のAWRレポートの期間が異なる場合には特に意識しておく必要があります。
そしてLoad Profileですが、どのようなWorkloadが流れているのかを理解するにはこのセクションが非常に大切です。私がまず見るのは「Redo size」行の「Per Sec」列の値です。要は秒間のRedo生成量(Bytes/sec)であり、この値が1MB以下であれば更新処理が少ないと感じます。5~10MB/sec前後であれば普通かなー、20MB/secを越えてくるとちょっと多いかな―、40MB/secを越えてくると多いなーという間隔を持っています。ちなみに私が見たことがある一番多いRedo生成量は、一つのデータベース・インスタンスで200MB/secを超えていましたね。次にこのセクション内で見るのは・・・って言うと、まあ全部ですね。これ以上解説してしまうと、次が続かなくなってしまうので、先を急ぐことにしましょう。
続きまして、Instance Efficiency Percentages(Target 100%) のセクションですが、ここに「Buffer Hit %」なる項目があり「99.00」と書かれているではないですか?よって、演習1の答えは「高い」になるような気がしますよね。でも、こんな簡単な問題で良いのか?と疑問を抱いた方、その通りです。「99.00%」という数字は「100%」に非常に近い値ですが、「高い」とか「低い」という表現は非常に曖昧なものであり、厳密に何%以上だから高くて十分だ。という指標は無いのです。
そもそもキャッシュ・ヒット率は何を示していたのか思い出して下さいね。簡単に言えば、バッファ・キャッシュを経由するブロック読込み総回数に対して、ディスクから読まずバッファ・キャッシュにヒットした回数の割合ですね。つまりは、100%からヒット率を引いた値はディスクから読み込むことになるわけで、今回のAWRレポートでは1%がディスクから読んでいます。そして、この1%分のIOPSをディスクが捌けるのか否かと言う点が、キャッシュ・ヒット率が高いか低いかを判断する際に最も重要なことなのです。バッファ・キャッシュを経由するブロック読込み総回数が100回であれば1回のディスクI/Oで済みますが、総回数が100万回であれば1万回のディスクI/Oが発生するわけであり、より多くのディスクをASMで束ねる必要が出てくるでしょう。
と言う事で、キャッシュ・ヒット率が高いか低いかを判断するには、ディスクI/Oの回数を見極める必要があるわけです。演習1の解説を書くのに1時間以上を要してしまった私ですが、次の演習以降で、バッファ・キャッシュに関連する統計情報や待機イベントを実機で確認していきましょう。 ちなみに、これから統計情報を解説する予定なので余り多くは述べませんが、最近ではキャッシュ・ヒット率は次の式で計算しますね。
1 - (“physical reads cache” / (“consistent gets from cache” + “db block gets from cache”))
2. 次のSQLで今回の演習で使用するTAB36表をTRYスキーマ内に作成して下さい。
$ sqlplus TRY/TRY SQL> -- TBS39表領域と、この表領域をデフォルト表領域とするTRYユーザーの作成 create tablespace TBS39 datafile '+DATA(DATAFILE)' size 512m ; create user TRY identified by TRY default tablespace TBS39 ; grant connect, resource, dba to TRY ; -- TAB39_SMALL表の作成 connect TRY/TRY create table TAB39_SMALL (COL1 number NOT NULL, COL2 char(1000)) ; -- TAB39_SMALL表へ8MB分のレコードを挿入 insert /*+append */ into TAB39_SMALL select LEVEL, 'hoge'||to_char(LEVEL) from DUAL connect by LEVEL <=7*128*7 ; commit ; -- TAB39_SMALL表のCOL1列に主キーを作成 create unique index IDX_TAB39_SMALL_COL1 on TAB39_SMALL(COL1) ; alter table TAB39_SMALL add primary key (COL1) using index ; -- TAB39_BIG表の作成 create table TAB39_BIG (COL1 number NOT NULL, COL2 char(1000)) ; -- TAB39_BIG表へ約200MB分のレコードを挿入 insert /*+append */ into TAB39_BIG select LEVEL, 'hoge'||to_char(LEVEL) from DUAL connect by LEVEL <=7*128*200 ; commit ; -- TAB39_BIG表のCOL1列に主キーを作成 create unique index IDX_TAB39_BIG_COL1 on TAB39_BIG(COL1) ; alter table TAB39_BIG add primary key (COL1) using index ; -- TAB39_BIG表のCOL2列にBツリーを作成 create index IDX_TAB39_BIG_COL2 on TAB39_BIG(COL2) ; -- TRYスキーマ内の全オブジェクトのサイズを確認 set linesize 120 pages 5000 col SEGMENT_NAME for a24 select SEGMENT_NAME, SEGMENT_TYPE, BYTES/1024/1024 from USER_SEGMENTS order by 2, 1 ; SEGMENT_NAME SEGMENT_TYPE BYTES/1024/1024 ------------------------ ------------------ --------------- IDX_TAB39_BIG_COL1 INDEX 4 IDX_TAB39_BIG_COL2 INDEX 208 IDX_TAB39_SMALL_COL1 INDEX .1875 TAB39_BIG TABLE 208 TAB39_SMALL TABLE 8 -- TRYスキーマ内の全オブジェクトのオプティマイザ統計情報を取得 exec DBMS_STATS.GATHER_SCHEMA_STATS(ownname => 'TRY');
毎度お馴染みですが、実機で体験して頂く為の環境を作成して頂きました。8MBの表TAB39_SMALLと、208MBの表TAB39_BIGの2つの表を作成して頂きました。それぞれの表には主キーを作成していますが、表TAB39_BIG側には主キー以外にもBツリー索引IDX_TAB39_BIG_COL2を作成している点だけ覚えておいてください。では参りましょう!
3. バッファ・キャッシュのサイズと比較して相当小さなサイズであるTAB39_SMALL表に対してTABLE ACCESS FULLを行うクエリを実行し、データブロックの物理読込みを示す統計情報を確認して下さい。
$ sqlplus /nolog
SQL>
-- テストの都合上、バッファ・キャッシュ上のデータをフラッシュ
connect / as sysdba
alter system flush buffer_cache ;
-- クエリ実行
connect TRY/TRY
set autotrace on explain
select /*+FULL(t) */ sum(ora_hash(COL2, 10)) from TAB39_SMALL t ;
SUM(ORA_HASH(COL2,10))
----------------------
31333
Execution Plan
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1001 | 253 (1)| 00:00:04 |
| 1 | SORT AGGREGATE | | 1 | 1001 | | |
| 2 | TABLE ACCESS FULL| TAB39_SMALL | 6272 | 6131K| 253 (1)| 00:00:04 |
----------------------------------------------------------------------------------
-- 統計情報の確認
set lines 150 pages 5000
col NAME for a48
select S.NAME, M.VALUE
from V$MYSTAT M, V$STATNAME S
where M.STATISTIC# = S.STATISTIC#
and S.NAME like 'physical read%'
order by 1 ;
NAME VALUE
------------------------------------------------ ----------
physical read IO requests 39
physical read bytes 7421952
physical read flash cache hits 0
physical read partial requests 0
physical read requests optimized 0
physical read total IO requests 39
physical read total bytes 7421952
physical read total bytes optimized 0
physical read total multi block requests 13
physical reads 906
physical reads cache 906
physical reads direct 0
physical reads direct (lob) 0
physical reads direct temporary tablespace 0
physical reads for flashback new 0
physical reads prefetch warmup 0
physical reads retry corrupt 0
set autotrace on explainをクエリ実行前に設定しておくことで実行計画を確認できます。その出力された結果からも表TAB39_SMALLに対してTable Full Scanを示す、TABLE ACCESS FULLオペレーションが選択されていることが確認出来ますね。そして、後半はクエリを実行した際のデータブロックの物理読込みを示す統計情報(”physical read”で始まる統計)をV$MYSTATビューで確認しています。ちなみに、オプティマイザ統計情報も「統計情報」と略されて表現されることがあるので、どちらの統計情報を指しているのかは充分にご注意くださいね。でもって、ここで見ておくべき統計情報は全部は説明し切れないので、特徴的な「physical reads」と「physical reads cache」、さらには「physical read total multi block requests」の4つに限定して説明しておきましょう。詳細は、リファレンス・マニュアルを参照して下さいね。
- ✓ physical reads ディスクから読み込まれたデータブロックの合計数
- ✓ physical reads cache ディスクからバッファ・キャッシュに読み取られたデータブロックの合計数
- ✓ physical read bytes アプリケーション・アクティビティのみによるディスク読取りの合計サイズ(バイト)
- ✓ physical read total multi block requests 1つの要求で2つ以上のデータベース・ブロックを読み取る要求の合計数
はい、簡単ですよね。physical readsが906でphysical reads cacheも906ですから、ディスクから読み込まれた906個のデータブロックは全てバッファ・キャッシュ上にキャッシュされたことを意味しています。ブロックサイズが8KBの環境なので、906ブロックは7,421,952バイト(約7MBちょっと)となり統計情報physical read bytesの数に合致しますし、セグメントサイズにも合いますね。
また、physical read total multi block requests統計情報が13へカウントアップしていますが、これは一回のI/O要求で複数ブロックをバッファ・キャッシュへ読み込んだマルチ・ブロック読込みが行われたことを意味しています。実はこれが非常に大切です。これまでも説明したことがあったと思いますが、Table Full Scanのように連続した大量データを読み込む時には1つのブロック単位で連続に読み込むよりも、複数ブロックをまとめて読み込んだ方が効率的であり、これはハードディスク・ドライブの性能特性を考慮した場合には非常に理に適った読み方です。皆さんに覚えておいて欲しいのは、Table Full Scanしたからこの統計情報がカウントアップしていると言う事ではありますが、AWRレポートを読む際には逆の方向で利用して頂きたいのです。つまりは、この統計情報がカウントアップしているという事は、Table Full Scanのような連続した大量データの読込みが行われた可能性がある。という風にです。
ここではさらに、統計情報だけではなく、待機イベントもご紹介しておきましょう。
本来はSQL監視レポートで待機イベントを取得出来れば良かったのですが、実行時間が非常に短くてサンプリングされなかったため、より正確に待機イベントの発生状況を確認することが可能なevents 10046のSQLトレースを使用してみました。掲載しておいてなんですが、私も基本的にはいざと言う時にしか使用しませんし、SQL監視レポートで充分代用出来ますからお薦めしていません。それでも興味のある方はMy Oracle Supportで使い方、読み方を充分学習して自己責任の元で使用して下さい。
$ sqlplus / as sysdba SQL> alter system flush buffer_cache ; connect TRY/TRY alter session set events '10046 trace name context forever, level 12' ; select /*+FULL(t) */ sum(ora_hash(COL2, 10)) from TAB39_SMALL t ; alter session set events '10046 trace name context off' ; SQL> !ps PID TTY TIME CMD 2221 pts/0 00:00:00 bash 3508 pts/0 00:00:00 sqlplus 3913 pts/0 00:00:00 ps SQL> !ps -ef | grep 3508 | grep "DESCRIPTION=" | grep -v grep oracle 3904 3508 0 15:07 ? 00:00:00 oracleorcl (DESCRIPTION=(LOCAL... $ vi /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_3904.trc ===================== PARSING IN CURSOR (省略) ... sqlid='fgsp4fbsnj738' select /*+FULL(t) */ sum(ora_hash(COL2, 10)) from TAB39_SMALL t END OF STMT PARSE (省略):c=1000,e=612,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1, ... EXEC (省略):c=0,e=327,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1, ... WAIT (省略): nam='db file sequential read' ela= 804 file#=5 block#=1154 blocks=1 obj#=15714 ... WAIT (省略): nam='db file scattered read' ela= 560 file#=5 block#=1155 blocks=5 obj#=15714 ... WAIT (省略): nam='db file scattered read' ela= 910 file#=5 block#=1160 blocks=8 obj#=15714 ... WAIT (省略): nam='db file scattered read' ela= 1035 file#=5 block#=1169 blocks=7 obj#=15714 ... WAIT (省略): nam='db file scattered read' ela= 1059 file#=5 block#=28449 blocks=7 obj#=15714 ... WAIT (省略): nam='db file scattered read' ela= 1614 file#=5 block#=28456 blocks=8 obj#=15714 ... WAIT (省略): nam='db file scattered read' ela= 891 file#=5 block#=28465 blocks=7 obj#=15714 ... (以降、省略)
と言う事で、取得されたトレースを覗いて見ると、一回の「db file sequential read」待機イベントの後、「db file scattered read」待機イベントが連続して発生していることが確認出来ます。面白いですねー。各行の待機イベントには「blocks」という記載がありますが、これが「1」の場合にはシングル・ブロック読込み、「2以上」の場合にはマルチ・ブロック読込みを意味しますから、このことからも、db file sequential read待機イベントはシングル・ブロック読込み時に発生し、db file scattered read待機イベントはマルチ・ブロック読込み時に発生する。と理解出来ますね。さらに、次の演習4で確認しますが先出ししておくと、どちらの待機イベントも「バッファ・キャッシュ上へのブロック読込み時」に発生することも合わせて覚えておきましょう。
感が良い方は気付かれていると思うので書いておきますが、ディスクからブロックを読み込むけど、バッファ・キャッシュ上への読込みじゃなければ別の待機イベントになる。事も意味していますね。
4. 演習3のクエリ(待機イベントdb file scattered readが発生する)を実行後の、バッファ・キャッシュ上にキャッシュされているオブジェクトとそのサイズを確認して下さい。
$ sqlplus / as sysdba SQL> col OWNER for a8 col OBJECT_NAME for a16 select OWNER, OBJECT_NAME, count(*) "BUFFERS", count(*)*8/1024 "MB" from V$BH, DBA_OBJECTS where OBJD = DATA_OBJECT_ID and OWNER = 'TRY' and V$BH.STATUS != 'free' group by OWNER, rollup(OBJECT_NAME) order by 4 ; OWNER OBJECT_NAME BUFFERS MB -------- ---------------- ---------- ---------- TRY 897 7.0078125 TRY TAB39_SMALL 897 7.0078125
さてさて、解説も長くなってきたので、ちょいと締め切りの時間が厳しくなってまいりました。ここからはスピードアップしていきますよー!バッファ・キャッシュ上にキャッシュされているオブジェクトとサイズを確認する為には、V$BHビューへアクセスします。これは以前の回にも登場させていたはずですが、第何回だったのか思い出せません。ただし、リファレンス・マニュアルに記載されているビューですから、それほどレアな奴では無い認識です。
上記の回答例からも確認出来るように、バッファ・キャッシュ上には約7MBの表TAB39_SMALLのデータブロックがキャッシュされていますね。演習3のクエリを実行する前にバッファ・キャッシュを空にしているので、このブロックは演習3のクエリを実行することでキャッシュされたことに間違いは無いでしょう。
と言う事で、ここまで整理させて頂くと、バッファ・キャッシュのサイズに比べて非常に小さな表TAB39_SMALLをTable Full Scanした際に、バッファ・キャッシュ上へディスクからマルチ・ブロックで読み込みんだことを示す待機イベントdb file scattered readが発生します。
5. TAB39_SMALL表に対して索引を使用した表アクセス(TABLE ACCESS BY INDEX ROWID)を行うクエリを連続実行し、データブロックの物理読込みを示す統計情報を確認して下さい。
$ sqlplus TRY/TRY
SQL>
-- クエリの実行計画を確認
variable B1 number ;
execute :B1 := 1 ;
set autotrace on explain
select COL2 from TAB39_SMALL t where COL1 = :B1 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 1853248505
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |...
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1005 |...
| 1 | TABLE ACCESS BY INDEX ROWID| TAB39_SMALL | 1 | 1005 |...
|* 2 | INDEX UNIQUE SCAN | IDX_TAB39_SMALL_COL1 | 1 | |...
-------------------------------------------------------------------------------
$ ### Linuxコマンドで連続実行用のSQLファイルを作成
echo "alter session set events '10046 trace name context forever, level 12' ;"
> sql_loop.sql
for i in `seq 0 7 6272`; do
echo "variable B1 number ;"
echo "execute :B1 := $i ;"
echo "select COL2 from TAB39_SMALL t where COL1 = :B1 ;"
done >> sql_loop.sql
echo "alter session set events '10046 trace name context off' ;" >> sql_loop.sql
echo "
set lines 150 pages 5000
col NAME for a48
select S.NAME, M.VALUE
from V\$MYSTAT M, V\$STATNAME S
where M.STATISTIC# = S.STATISTIC#
and S.NAME like 'physical read%'
order by 1 ;" >> sql_loop.sql
### SQLの連続実行
$ sqlplus / as sysdba
SQL>
alter system flush buffer_cache ;
connect TRY/TRY
@sql_loop.sql
NAME VALUE
------------------------------------------------ ----------
physical read IO requests 126
physical read bytes 7741440
physical read flash cache hits 0
physical read partial requests 0
physical read requests optimized 0
physical read total IO requests 126
physical read total bytes 7741440
physical read total bytes optimized 0
physical read total multi block requests 0
physical reads 945
physical reads cache 945
physical reads direct 0
physical reads direct (lob) 0
physical reads direct temporary tablespace 0
physical reads for flashback new 0
physical reads prefetch warmup 819
physical reads retry corrupt 0
SQL> -- バッファ・キャッシュ上にキャッシュされているオブジェクトとサイズ
connect / as sysdba
col OWNER for a8
col OBJECT_NAME for a24
select OWNER, OBJECT_NAME, count(*) "BUFFERS", count(*)*8/1024 "MB"
from V$BH, DBA_OBJECTS
where OBJD = DATA_OBJECT_ID and OWNER = 'TRY' and V$BH.STATUS != 'free'
group by OWNER, rollup(OBJECT_NAME)
order by 4 ;
OWNER OBJECT_NAME BUFFERS MB
-------- ------------------------ ---------- ----------
TRY IDX_TAB39_SMALL_COL1 14 .109375
TRY TAB39_SMALL 896 7
TRY 910 7.109375
ちょいと回答例が長い演習ですが、前半部分は索引を使用して表へアクセスするSQLを連続実行する為のSQLファイルを作成しているだけですので、それほど難しい内容では無いと思います。と言う事で、イキナリ後半の解説をさせて頂きますね。
実行計画として索引を使用した表アクセス(TABLE ACCESS BY INDEX ROWID)が行われていることを確認済みなクエリを連続実行していくわけですから、これまで体験してきた一回のクエリでTable Full Scanでマルチ・ブロック読込みを行う処理とは異なる点はご理解頂けると思います。なので、マルチ・ブロック読込みを示す統計情報「physical read total multi block requests」がカウントアップしていませんよね。よしよし。統計情報が読めるようになってきましたね。しかーし、油断してはなりません。そんな簡単な演習問題を私が出すはずがありません。
と言う事で、またまた登場のevents 10046のSQLトレースの結果を見てみることにしましょう。
$ cat orcl_ora_5313.trc | grep "db file" (省略) WAIT (省略): nam='db file scattered read' ela= 1234 file#=5 block#=1160 blocks=8 ... WAIT (省略): nam='db file scattered read' ela= 821 file#=5 block#=1168 blocks=8 ... WAIT (省略): nam='db file scattered read' ela= 1128 file#=5 block#=28440 blocks=8 ... WAIT (省略): nam='db file scattered read' ela= 1599 file#=5 block#=28448 blocks=8 ... WAIT (省略): nam='db file scattered read' ela= 1089 file#=5 block#=28456 blocks=8 ... WAIT (省略): nam='db file scattered read' ela= 1401 file#=5 block#=28464 blocks=8 ... WAIT (省略): nam='db file scattered read' ela= 965 file#=5 block#=28472 blocks=8 ... (省略) $ cat orcl_ora_5313.trc | grep "db file sequential read" | wc -l 1 $ cat orcl_ora_5313.trc | grep "db file scattered read" | wc -l 117
繰り返しになりますが、この演習5のクエリは索引を使用した表アクセス(TABLE ACCESS BY INDEX ROWID)、つまりは、索引ブロックを一つアクセスしてリーフ・ブロックに辿りつき、特定されたROWIDを使用して表の該当する一つのブロックを読み込む。と言うように順番(sequential)にシングル・ブロックを読み込む処理なので、db file sequential read待機イベントが発生するはずなのですが・・・如何でしょうか?がーん!ですね。ディスクからバッファ・キャッシュ上へのマルチ・ブロック読込みを示すdb file scattered read待機イベントが発生しまくっているではないですか!!
はい、混乱させてしまい申し訳ございません。こういうのが記事を分かりづらくしてしまっているのかもしれませんが、どうしても触れておきたいので体験して頂きました。解説させて頂きます。
ここまでの皆さんの推測は間違っておりません。一般的には、索引を使用した表アクセス(TABLE ACCESS BY INDEX ROWID)では、ディスクからバッファ・キャッシュ上へシングル・ブロック読込みを示すdb file sequential read待機イベントが発生します。しかし、今回はdb file scattered read待機イベントが発生していた。と言うのはあくまで例外であり、Pre-Warming機能が動作したと覚えておいてください。この機能も以前ご紹介させて頂いていたと記憶がありますが、改めて簡単に解説しておきますね。
Pre-Warming機能は、バッファ・キャッシュに余裕がある(空き領域が存在する)場合に限定して、一つのブロックをバッファ・キャッシュへ読み込む処理が発生した時に、その周辺のブロックも一緒にマルチ・ブロック読込みしてしまう機能です。何かメリットがあるの?と言うと、「バッファ・キャッシュの暖気を早くする」と表現すると分かりやすいかもしれませんね。一つのブロックを読んだのだから、その周辺もそのうち読まれるかもしれない。だったら、バッファ・キャッシュの空きに余裕があるのだから、一緒にバッファ・キャッシュに読み込んでおいちゃえ。と賢く動作してくれています。
朝方にインスタンスの再起動を行いバッファ・キャッシュが空の状態からオンライン業務がスタートすることがあります。索引アクセスのクエリしか実行していないのに、db file scattered read待機イベントが発生している!実行計画がTABLE ACCESS FULLに変化してしまったのか?と現場のDBAが慌てている姿を見たことがありますが、Pre-Warming機能が動作している可能性があることを覚えておけばなんてことないですよね。今回は分かりづらくしてでも体験してもらいたかったPre-Warming機能でした。
と言う事で、バッファ・キャッシュに余裕が無ければ、Pre-Warming機能が発生しないと理解できたと思うので、次に考えるのはバッファ・キャッシュを何かしらのオブジェクトで満杯にした状態を作り出したい。ですよね?
6. バッファ・キャッシュのサイズよりも大きなTAB39_BIG表のBツリー索引IDX_TAB39_BIG_COL2を使用したINDEX FAST FULL SCANが行われるクエリを実行した後、バッファ・キャッシュ上にキャッシュされているオブジェクトとサイズを確認して下さい。
$ sqlplus /nolog SQL> -- クエリの実行計画の確認と実行 connect TRY/TRY set autotrace on explain select /*+ INDEX_FFS(TAB39_BIG, IDX_TAB39_BIG_COL2) */ count(COL2) from TAB39_BIG ; COUNT(COL2) ----------- 179200 Execution Plan ---------------------------------------------------------- Plan hash value: 80225013 -------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 1001 | 7102 (1)| 00:01:26 | | 1 | SORT AGGREGATE | | 1 | 1001 | | | | 2 | INDEX FAST FULL SCAN| IDX_TAB39_BIG_COL2 | 179K| 171M| 7102 (1)| 00:01:26 | -------------------------------------------------------------------------------------------- SQL> -- バッファ・キャッシュ上にキャッシュされているオブジェクトとサイズ connect / as sysdba col OWNER for a8 col OBJECT_NAME for a24 select OWNER, OBJECT_NAME, count(*) "BUFFERS", count(*)*8/1024 "MB" from V$BH, DBA_OBJECTS where OBJD = DATA_OBJECT_ID and OWNER = 'TRY' and V$BH.STATUS != 'free' group by OWNER, rollup(OBJECT_NAME) order by 4 ; OWNER OBJECT_NAME BUFFERS MB -------- ------------------------ ---------- ---------- TRY IDX_TAB39_SMALL_COL1 1 .0078125 TRY IDX_TAB39_BIG_COL1 375 2.9296875 TRY IDX_TAB39_BIG_COL2 16318 127.484375 TRY 16694 130.421875
どうですか?ビックリでは無いですか?この演習の回答例は、私がバッファ・キャッシュが満杯な状況を作り出す際に良く使用するテクニックです。今更ですが、今回の私の検証環境のバッファ・キャッシュのサイズは140MB程度と非常に小さくしてあります。そのバッファ・キャッシュを満杯にする為には、その140MBよりも大きなBツリー索引に対してINDEX_FFSヒント句を使用してIndex Fast Full Scan(索引高速スキャン)でアクセスするのが最も簡単な手法でしょう。
なぜ演習2において、索引IDX_TAB39_BIG_COL2を作成しておいたのかが分かりましたね。索引IDX_TAB39_BIG_COL2のサイズは208MBであり、バッファ・キャッシュの140MBよりも大きいです。この索引を高速索引スキャンすることで、バッファ・キャッシュがこの索引のブロックで満杯になっていることが確認頂けるかと思います。上記の回答例ではTRYスキーマだけで約130MBをキャッシュしていることが分かります。これ以外にもSYSTEMユーザーのオブジェクトがキャッシュされているので、140MBのバッファ・キャッシュが満杯になっていました。OWNER列の条件を解放すれば皆さんの環境でもご確認頂けるかと思います。
さてさて、これでTAB39_SMALL表に対して索引を使用した表アクセス(TABLE ACCESS BY INDEX ROWID)を行うクエリを実行した際に、db file sequential read待機イベントが発生するのかを確認できる準備が整いましたね。
7. バッファ・キャッシュをフラッシュせずに(バッファ・キャッシュ上に索引IDX_TAB39_BIG_COL2がキャッシュされている状況)、演習5を再実行(TAB39_SMALL表に対して索引を使用した表アクセス(TABLE ACCESS BY INDEX ROWID)を行うクエリを連続実行)した際の統計情報の変化を確認して下さい。
$ sqlplus TRY/TRY SQL> @sql_loop.sql NAME VALUE ------------------------------------------------ ---------- physical read IO requests 909 physical read bytes 7446528 physical read flash cache hits 0 physical read partial requests 0 physical read requests optimized 0 physical read total IO requests 909 physical read total bytes 7446528 physical read total bytes optimized 0 physical read total multi block requests 0 physical reads 909 physical reads cache 909 physical reads direct 0 physical reads direct (lob) 0 physical reads direct temporary tablespace 0 physical reads for flashback new 0 physical reads prefetch warmup 0 physical reads retry corrupt 0
まずは、統計情報を確認してみると、「physical reads prefetch warmup」がカウントアップしていないことから、Pre-Warming機能が動作していなかったことが理解出来ますし、前回同様にマルチ・ブロック読込みを示す「physical read total multi block requests」もカウントアップしていませんので、この演習のクエリ実行ではシングル・ブロック読込みしか発生していないでしょう。以下はevents 10046のSQLトレースの結果をgrepしたものですが、待機イベントdb file sequential readだけが発生していることが確認出来ますね。
$ cat orcl_ora_7888.trc | grep "db file scattered read" | wc -l 0 $ cat orcl_ora_7888.trc | grep "db file sequential read" | wc -l 909
遠回りしてしまいましたが、索引を使用した表アクセス(TABLE ACCESS BY INDEX ROWID)、つまりは、索引ブロックを一つアクセスしてリーフ・ブロックに辿りつき、特定されたROWIDを使用して表の該当する一つのブロックを読み込む。と言うような順番(sequential)にシングル・ブロックをバッファ・キャッシュへ読み込む場合には、db file sequential read待機イベントが発生することをご理解頂けたかと思います。
8. バッファ・キャッシュのサイズよりも大きな表TBS39_BIGに対してTABLE ACCESS FULLを行うクエリを実行し、統計情報を確認して下さい。合わせて、バッファ・キャッシュ上に表TBS39_BIGのデータブロックがキャッシュされているか否かを確認して下さい。
connect / as sysdba
alter system flush buffer_cache ;
connect TRY/TRY
set autotrace on explain
select /*+FULL(t) */ sum(ora_hash(COL2, 10)) from TAB39_BIG t ;
(実行結果と実行計画は省略)
set lines 150 pages 5000
col NAME for a48
select S.NAME, M.VALUE
from V$MYSTAT M, V$STATNAME S
where M.STATISTIC# = S.STATISTIC#
and S.NAME like 'physical read%'
order by 1 ;
NAME VALUE
------------------------------------------------ ----------
physical read IO requests 420
physical read bytes 209797120
physical read flash cache hits 0
physical read partial requests 0
physical read requests optimized 0
physical read total IO requests 420
physical read total bytes 209797120
physical read total bytes optimized 0
physical read total multi block requests 401
physical reads 25610
physical reads cache 10
physical reads direct 25600
physical reads direct (lob) 0
physical reads direct temporary tablespace 0
physical reads for flashback new 0
physical reads prefetch warmup 0
physical reads retry corrupt 0
connect / as sysdba
col OWNER for a8
col OBJECT_NAME for a24
select OWNER, OBJECT_NAME, count(*) "BUFFERS", count(*)*8/1024 "MB"
from V$BH, DBA_OBJECTS
where OBJD = DATA_OBJECT_ID and OWNER = 'TRY' and V$BH.STATUS != 'free'
group by OWNER, rollup(OBJECT_NAME)
order by 4 ;
OWNER OBJECT_NAME BUFFERS MB
-------- ------------------------ ---------- ----------
TRY 1 .0078125
TRY TAB39_BIG 1 .0078125
演習7までは、バッファ・キャッシュのサイズと比較して非常に小さな表を検索するという演習を行ってきました。シングル・ブロック読込み時の待機イベントdb file sequential read、マルチ・ブロック読込み時の待機イベントdb file scattered readは、いずれもディスクからバッファ・キャッシュ上への読込みを示していましたね。でもって、この演習8では、バッファ・キャッシュのサイズよりも大きな表TAB39_BIGをTable Full Scanしてみると言うものですが、物理読込み関連の統計情報で特徴的な傾向が出ていますね。これまでの演習では一度もカウントアップしていなかった、統計情報physical reads directに大きな値が入っています。この統計情報の説明をリファレンス・マニュアルから原文のまま抜き出したものが次です。
✓ physical reads direct バッファ・キャッシュをバイパスしてディスクから直接読み込んだ読取りの数。たとえば、高帯域幅での集中的なデータ操作(パラレル実行など)では、ディスク・ブロックを読み取るとき、バッファ・キャッシュがバイパスされる。これによって、転送率が最大化され、バッファ・キャッシュ内に存在する共有データ・ブロックの早期エージングが防止される。
なるほど。physical reads cacheはバッファ・キャッシュ上へディスクから読み込んだ合計数でしたが、physical reads directは「バッファ・キャッシュをバイパスする」=「バッファ・キャッシュ上へキャッシュしないディスク読込み」と言う事ですね。つまりは、プロセス毎のPGA領域だと思って下さい。そのメリットも記載されていますね。マニュアル素敵ですね!とは言え、私なりに噛み砕いて説明しておきますね。
バッファ・キャッシュ上へデータブロックをキャッシュするという事は、バッファ・キャッシュ上の空きを探したり確保したりしなければなりません。複数のサーバープロセスが同じバッファ・キャッシュ領域を操作していることを考慮すれば、その制御にCPUコストを消費したり、ラッチ競合(Oracle Databaseの内部的に処理をシリアライズ化する為のロック)が発生したりしますが、バッファ・キャッシュをバイパスする為にそれらのコストが不要となりますよね。上記でいう「転送率が最大化」に該当します。次に、バッファ・キャッシュ上へ大きな表をキャッシュするとどうなるのかを考えてみましょう。大きな表をキャッシュする為にはそれ以前にキャッシュされているデータブロックをキャッシュ上から追い出さなくてはなりません。追い出すに為には先ほどと同じようにCPUコストやラッチ競合が発生します。そして、もし追い出して大きな表だけがキャッシュされている状況になったら、他のオブジェクトにアクセスするクエリの性能はどうなりますか?キャッシュ・ヒット率が低下して、パフォーマンス劣化が引き起こされるでしょう。全く持って良いことはありませんよね。と言う事で、上記の「バッファ・キャッシュ内に存在する共有データ・ブロックの早期エージングが防止される」は絶対的に効果があるのです。
よって、データベース・システム全体のパフォーマンスの効率化を考えた場合、バッファ・キャッシュのサイズと比較して大きな表は、バッファ・キャッシュをバイパスしてディスクから読み込んだ方が良いという事が腹に落ちましたよね。ちなみに、この時に発生するかもしれない待機イベントは、direct path readとなります。
「かもしれない」と表現した理由はちょいと解説が難しいので、より高度な知識が欲しい方へのTipsとなります。ご興味があれば次を読んでみてください。
$ cat orcl_ora_7943.trc | grep "db file" | wc -l
2
$ cat orcl_ora_7943.trc | grep "direct path read" | wc -l
349
$ cat orcl_ora_7943.trc | grep "direct path read" | cut -d " " -f13 | sed -e "s/cnt=//" | awk '{m+=$1} END{print m;}'
21928
$ expr 21928 \* 8 \/ 1024
171
バッファ・キャッシュをバイパスしてディスクからマルチ・ブロック読み込む場合には、待機イベントdb file scattered readは発生しません。代わりに待機イベントdirect path read が発生しますが、これが少し厄介な奴です。と言うのも、待機イベントdb file scattered readはマルチ・ブロック読込みした場合には必ず発生しますが、待機イベントdirect path readは発生しない事があります。これはリファレンス・マニュアルにもちょっと分かりづらい記載がある通り、そういうものなのです。
「ダイレクト・パス処理中に、データはデータベース・ファイルに非同期的に読み取られます。セッションのある段階で、ディスクに対する未処理の非同期I/Oの処理をすべて完了しておく必要があります。この処理は、ダイレクト読取り中に未処理のロード要求(1つのロード要求が複数のI/Oで構成されることもある)を格納するためのスロットがなくなった場合にも必要になることがあります。」
なので、events10046のSQLトレースで待機イベントdirect path readが発生した際のブロック数を合計しても、171MBにしかならず、表TAB39_BIGのセグメントサイズの208MBには達していません。
9. 演習1で提示したAWRレポートにおいて、Top5待機イベントと物理読込み関連の統計情報を追加分析することで、キャッシュ・ヒット率が高いか否かを評価して下さい。
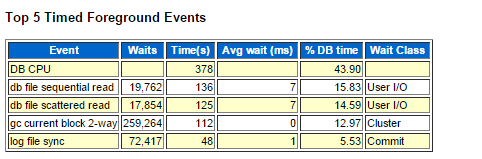
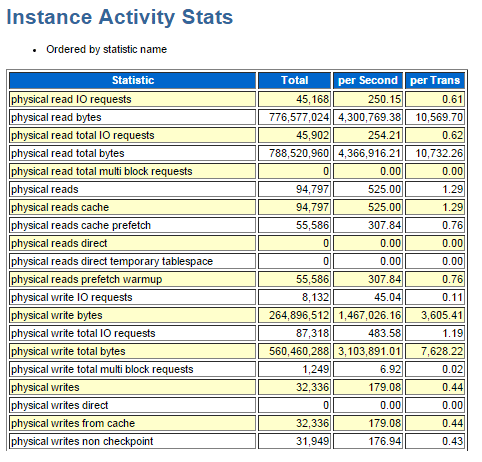
さて、ようやく戻ってきましたね。3つの待機イベントdb file sequential read / db file scattered read / direct path readが発生する処理の違いと、それを示す幾つかの統計情報が理解出来た今、99.00%というバッファ・キャッシュヒット率が高いのか、低いのかを改めて評価してみましょう。と言う事で、皆さんが見たいと思うであろう統計情報を抜粋して掲載しておりますが、如何でしょう。
Top5待機イベントには、シングル・ブロック読込みを示す待機イベントdb file sequential readとマルチ・ブロック読込みを示す待機イベントdb file scattered readが記録されています。これだけを見ると、Table Full Scanが発生しているのかと疑いますが・・・と言う話をしていましたね。統計情報を見てから判断してみましょう。
ディスクから読み込まれた総回数は統計情報physical readsから94,797回であり、その全てがバッファ・キャッシュ上へ読み込まれたことが統計情報physical reads cacheが94,797回であることから理解できます。統計情報physical reads directが0回ですから、大きな表のTable Full Scanは発生していないでしょう。ただし、統計情報physical reads prefetch warmupがカウントアップしていることからPre-Warming機能が動作していることが理解できます。演習1で提示したAWRレポートにはインスタンス起動日時を示す「Startup Time」とスナップショット日時「Begin Snap」が記載されていますが、その二つの日時が近いことからも、バッファ・キャッシュが空の状態で負荷テストを開始したのだろうと推測することもできますね。なるほど。待機イベントdb file scattered readはPre-Warming機能が動作した為に発生していると推測できるので無視しても良いでしょう。
統計情報physical readsの1秒間当たりの回数を確認してみると525回/secです。これは、どのような数字なのかイメージ付きますか? 7200rpmのHDD一本当たり、8KB単位のI/Oでは200~300iopsは稼げます。つまり、525iopsはHDDが2,3本あれば充分なのです。もちろん、HDDへは書き込み処理も行われますから統計情報physical writesの値(179.08回/sec)を加算しても、約700iopsでしょう。もちろん、HDDの書き込み性能と読込み性能は同じではなく、書き込みコストの方が大きい傾向にあるので、とは言え、80%ぐらい(160~240iops)7は出るので700/160=4,5本で問題無さそうという結論になります。まあ、大した負荷では無いでしょうから、このAWRレポートのキャッシュ・ヒット率は充分に高い。と評価できるでしょう。 と、ここまで散々解説してきましたが、1秒間当たりのphysical readsとphysical writesの値は、演習1のAWRレポートのLoad Profileセクションに掲載されていたりします。なので、冒頭にも述べたように、「ここ(AWRレポートの始め)に全ての情報が集約されていると言っても過言ではないのです。」ですね。
さて、AWRレポートを読む為のステップ1として、バッファ・キャッシュ関連の待機イベントと統計情報を体験頂きましたが、如何でしたでしょうか?想定以上に長編な回となってしまい、分割しても良かったのではないかと後悔しております。とは言え、一気に理解して頂きたい部分でもあったので、私としても頑張ってみた次第です。
今回の演習で体験した待機イベントと統計情報は全体の数と比較すれば非常に少ないですが、一番良く目にするものだと思います。なので、次に何かしらのAWRレポートを見た時に、こんな処理が流れているのでないか?と、推測出来るようになってきていると思います。これが実に推理小説を読むように面白いと感じるようになってきたら、貴方はもうOracle Databaseから離れることは出来ないでしょう。きっとね。次回以降も、AWRレポートの読み方の解説に挑戦していきたいと考えています。
ちなみに、今回のように待機イベントと統計情報からディスクのiopsが足りている?足りていない?と議論することが可能になっているのも、実はASMを使用してデータファイルを全ディスク上にストライピングしているからであって、一昔前のRAWデバイス上にデータファイルを配置していたとしたらRAWデバイス毎のiopsを分析しなければならなかったのですよね。そう考えると、ASMによって細かく分析しなくて良くなったというメリットもあるなと、ちょっと今回の連載には直接関係ないのですけど、ASM好きな私としては感じました。
と言う事で、今回も最後まで体験して頂きましてありがとうございました。是非、感想や質問をお待ちしておりますね。次回以降もどうぞよろしくお願い致します。
(ご質問の方法はこちらにあります)
https://blogs.oracle.com/otnjp/shibacho-index
