Oracle AI Vector Search is specifically designed for AI workloads, enabling data queries based on semantics rather than mere keywords. This approach offers a more intuitive and context-aware search capability, essential for sophisticated AI applications. Incorporating vectorization into your Siebel CRM database can significantly enhance the activation of AI use-cases by providing a robust foundation for semantic data queries, leading to more accurate and meaningful insights.
Highlights of the Oracle Vector AI Search
- Quality of Query of Results: the effectiveness of your queries depends significantly on the relevance and volume of your data, as well as the performance of your vector embedding model (neural network).
- VECTOR Data Type: introduced in Oracle Database 23ai, the VECTOR data type enables the storage of vector embeddings alongside traditional business data. This integration allows for more powerful semantic queries. For example:
CREATE TABLE docs (doc_id INT, doc_text CLOB, doc_vector VECTOR);
Vector Embeddings
- Vector embeddings are mathematical representations of data points that capture the semantic meaning of various content types, including words, documents, audio tracks, or images. Common applications utilizing vector embeddings include voice assistants, chatbots, language translators, recommendation systems, anomaly detection, and video search and recognition. Vector embeddings translate semantic similarities into spatial proximity within a high-dimensional vector space, often encompassing hundreds or thousands of dimensions.
- Vector embeddings represent diverse data types (text, images, videos, users, music) as points in a multi-dimensional space where their positions and proximities are semantically meaningful.
- Compared to keyword searches, searches that use vector embeddings offer superior performance by focusing on the meaning and context of words, rather than their literal presence.
- Efficient Similarity Searches: Similarity searches retrieve data from one or more clusters based on the query vector and the specified fetch size. When using vector indexes for approximate searches, the search can be confined to specific clusters. In contrast, exact searches examine vectors across all clusters.
Creating Vector Embedding Models
One approach to creating vector embeddings involves leveraging domain expertise to define and quantify a predefined set of features or dimensions, such as shape, texture, color, sentiment, and other relevant attributes, based on the object type. However, the efficiency of this method varies by use-case and can often be cost-prohibitive. Rather, vector embeddings are typically generated using neural networks. Most modern embeddings are produced by transformer models, as shown in the following diagram, although convolutional neural networks (CNNs) can also be utilized.
Depending on our data type, we can use various pretrained, open-source models to create vector embeddings. Here are some examples:
- Textual Data: Sentence transformers convert words, sentences, or paragraphs into vector embeddings.
- Visual Data: Residual Networks (ResNet) are effective for generating vector embeddings from images.
- Audio Data: Audio data can be transformed into visual spectrograms, allowing you to apply visual data models, like ResNet.
Additionally, the number of dimensions for our vectors is determined by the model we choose. For example:
- Cohere’s embedding model embed-english-v3.0 has 1024 dimensions.
- OpenAI’s embedding model text-embedding-3-large has 3072 dimensions.
- Hugging Face’s embedding model all-MiniLM-L6-v2 has 384 dimensions.
…of course, we can always create our own model that is trained with our own data set.
Import Embedding Models into the Oracle Database
Although you can generate vector embeddings outside of the Oracle database using pre-trained open-source models or custom models, you also have the option to import these models directly into the Oracle database if they are compatible with the Open Neural Network Exchange (ONNX) standard. The Oracle database includes an ONNX runtime, enabling you to generate vector embeddings directly within the database using SQL.
Sample Siebel Use-Case: Searching and Displaying Semantically Related Service Requests
Providing users with a seamless and efficient search experience is crucial. This use-case outlines how the Oracle Vector AI Search provides a mechanism for Siebel users to search for semantically related Service Requests (SR), directly in the SR details screen. This sample use-case is applicable for both on-premises or Cloud based Siebel CRM deployments.
Steps:
- Configure the Siebel UI to show the related SR UI tab in the Service Request Applet.
- Develop a microservice-based REST API to perform the similarity search on SR embedding data and return the related SRs.
- Configure the components below in the Siebel CRM Oracle 23ai database.
- Configure/Load the in-database embedding model.
- Create a PL/SQL procedure to create vector embedding for the SR data in the Siebel CRM database and store it in another vector table for similarity search.
- Create a trigger to update the vector table with updated SR Data Embedding.
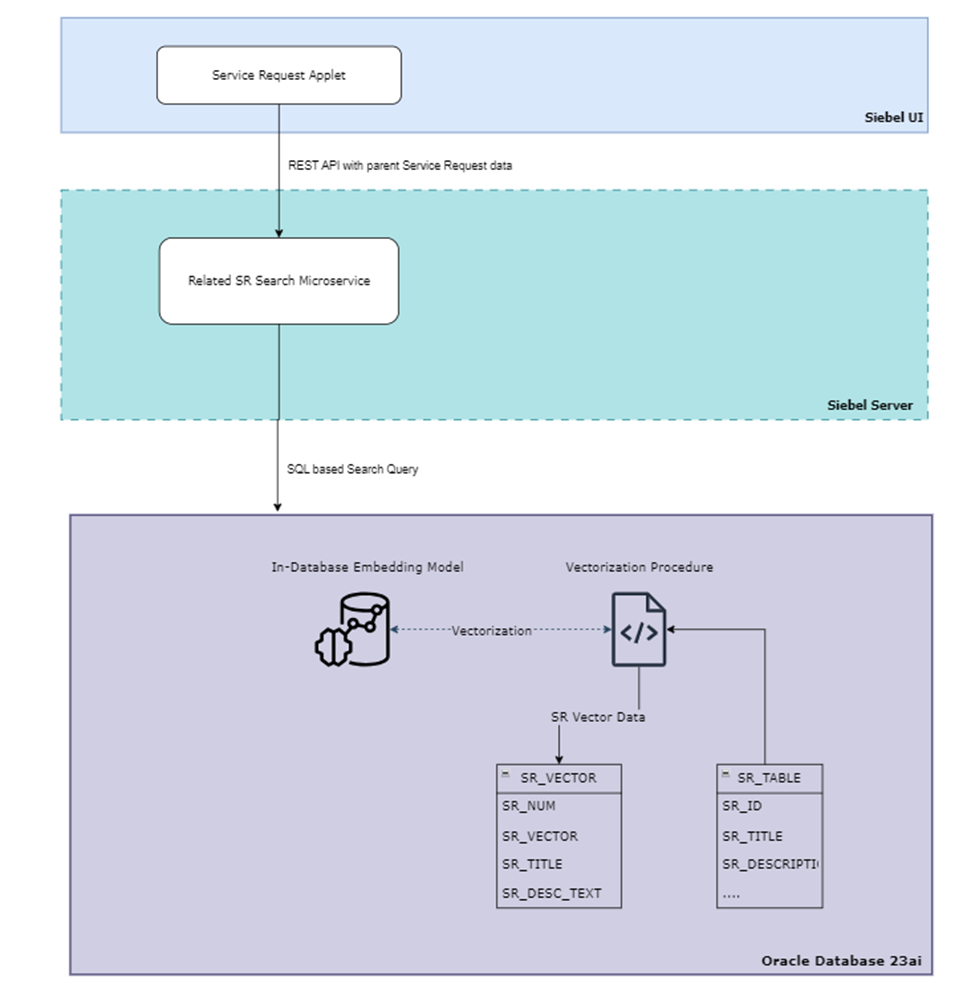
Use-Case Architecture Diagram
Sample Sequence Flow
- PL/SQL procedure reads the SR table and populates the SR vector table. This is a one-time procedure that must be performed during either the upgrade or initialization. As part of productization, the implementation team should consider bulk data handling, logging, traceability, reusability, and error handling.
- Any update in the SR table would trigger the PL/SQL procedure which will convert the updated SR to vector embedding and update the corresponding entry in the SR_VECTOR table.
- The user flow starts when you visit the SR details page that contains the related SRs. When the SR detail page is loaded, the REST API call is made to the “Related SR Search” microservice with the parent SR details. The microservice then runs a similarity search SQL query for returning the semantically related SRs.
Building Blocks
- Siebel UI component for displaying related SRs: a section to display the related SRs is included in the Service Request view. This invokes the “Related SR Search Microservice” to fetch the related SRs.
- Related SR Search Microservice: a RESTful web service that handles requests for related SRs and interacts with the Oracle database to perform the similarity search based on the parent SR data in the REST API.
- In-Database Embedding Model: the embedding model is used to convert the SR data to vector embeddings. In this example, we used the all-MiniLM-L12-v2 model. During implementation, we can evaluate multiple embedding models and their performance on actual SR data.
- SR_VECTOR table: a new table is created in the Siebel CRM database to store the vector embeddings of the existing SRs.
- Vectorization Procedure: a PL/SQL procedure is created to convert the SR data to contextual vector embedding using the In-Database Embedding Model and store it in the SR_VECTOR table. As part of productization, this needs to be revisited for performance optimization and preprocessing of SR data with NLP techniques for better search vectors.
On behalf of the Siebel CRM Center of Excellence team, we hope you enjoyed reading this example of how to use the Oracle AI Vector Search capability in Oracle database 23ai with your Siebel CRM data. If you have other use-cases you are trying to implement our team would be more than happy to assist you.
