This blog is part 3 of the series on using Oracle NoSQL Database on-premises. We started with KVlite, which can get up and running with NoSQL DB in less than 5 mins! Then we set up a single sharded Oracle NoSQL Database Cluster, and in this edition, we will look at how to expand the single sharded Oracle NoSQL Database into three shards. A 3 sharded Oracle NoSQL Database cluster with a replication factor of 3 is a common deployment topology that customers tend to use in production.
In my last blog, we looked at the architecture of the Oracle NoSQL Database and the components that make up the cluster. In case if you haven’t read that, it is useful to do that so you can understand all the different parts that make up an Oracle NoSQL Database cluster. In any system, achieving scalability by reducing communication between components is valuable – this is why Big Data/NoSQL systems are sharded. Each shard is independent of the others; in effect, you have lots of “little databases” that are running independently of each other, with very little communication between the shards. There is a trade-off to sharding; you may not be able to provide the same functionality that a single system does. E.g., at the time of writing this blog, Oracle NoSQL Database doesn’t support transactions across shards, because that would involve too much communication, and would compromise the scalability of the system. Secondly, in a distributed system, the probability that SOME components SOMEWHERE in the system will fail grows dramatically as the number of components increases. For example, if the mean-time-between-failure for a single disk is 1000 hours, if you have 1000 disks in the system, some disk drive, somewhere, is going to fail every hour!!!. So the system has to be highly available to compensate for a high probability of failure. The only way to achieve high availability is through redundancy (keep the information in two or more places). To continue the earlier example, if all 1000 disks had the same information, then it wouldn’t matter if there was a disk failure every hour. Of course, the price of redundancy is reduced capacity. So a well-designed distributed system achieves the right balance between “decoupled components” for scalability and redundancy for availability. We have tested the Oracle NoSQL Database on systems as large as 300 nodes and demonstrated linear scalability of performance.
Before we dive into details of cluster expansion, let’s look at the different options that exist today for expanding an Oracle NoSQL Database cluster. You can expand an Oracle NoSQL Database cluster in two ways:
- By Increasing the replication factor
- By Adding a shard
Let’s look at each of the scenarios. When you expand an Oracle NoSQL kvstore by increasing the replication factor, you create more copies (replication nodes) of the data to each shard in the kvstore. Because each shard can contain only one master node, the additional replication nodes increase the number of nodes that handle reads, thereby improving the read request throughput. It also increases the durability to withstand disk or machine failures. However, the increased durability and read throughput have costs associated with it: more hardware resources are needed to host and serve the additional copies of the data and slower write performance because each shard has more replica nodes to send updates to. For further information on how to identify your replication factor and to understand the implications of the factor value, see Replication Factor.
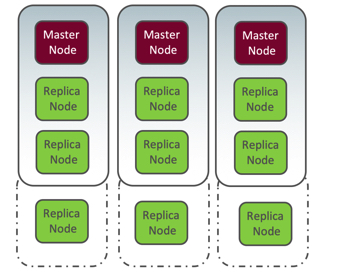
Figure 1: Increasing replication factor from RF=3 to RF=4
Let’s look at the second scenario where you add the shard to the Oracle NoSQL Database cluster. When you add a shard to the cluster, you add a master node and some replica nodes, depending on the existing replication factor. Now because one of the new replication nodes is a Master node, the kvstore has an additional replication node to service the database write operations, thereby improving the database write throughput. Recollect that database writes are always directed to the leader (master) node. When you add a new shard, the replica nodes that service the database read operations are also added, thus improving the read throughput. So, when you add a shard, it increases both the read and write throughput.
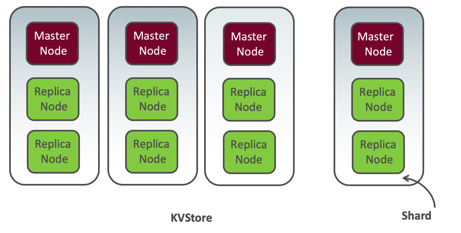
Figure 2: Adding new shard
With above as background, we’ll look at how to add shards to the cluster. We’ll use the same topology that we used in the last blog, and we will add two more shards, so, from a single shard, we go to three shards, each with a replication factor of 3.
The steps to add new shards remain pretty much the same as creating a single shard, i.e., bootstrap the new storage nodes, start the SNA, and configure the store. There’s one additional step that is needed, which is to redistribute the topology to distribute the partition across the new shards. The process of redistribution is automatic; the system automatically picks up the number of partitions from each shard and moves them to the new shard, thus reducing human errors.
In the topology that we used in the previous blog, we used three storage nodes, each with capacity one. In the expansion, we will add two more storage nodes (sn4 and sn5), each with a capacity of three, i.e., the new storage nodes will each have three disks.
Let’s dive in
First, bootstrap both the new storage nodes. Notice that we set the capacity to 3 and we specify the directory for each storage
Bootstrap storage node 4
java -jar $KVHOME/lib/kvstore.jar makebootconfig \
-root $KVROOT \
-store-security none \
-capacity 3 \
-harange 5010,5030 \
-port 5000 \
-memory_mb 200 \
-host kvhost04 \
-storagedir $KVDATA/u01 \
-storagedirsize 100-MB \
-storagedir $KVDATA/u02 \
-storagedirsize 100-MB \
-storagedir $KVDATA/u03 \
-storagedirsize 100-MB \
It is essential here that the number of storagedir construct matches the capacity of the storage node. In the above example, we specified 100-MB for each storage directory size; however, we do support different values for the storagedirectorysize.
Bootstrap storage node 5
java -jar $KVHOME/lib/kvstore.jar makebootconfig \
-root $KVROOT \
-store-security none \
-capacity 3 \
-harange 5010,5030 \
-port 5000 \
-memory_mb 200 \
-host kvhost05 \
-storagedir $KVDATA/u01 \
-storagedirsize 100-MB \
-storagedir $KVDATA/u02 \
-storagedirsize 100-MB \
-storagedir $KVDATA/u03 \
-storagedirsize 100-MB \
Next, start the SNA on each of the above storage nodes
java – jar $KVHOME/lib/kvstore.jar start -root $KVDATA/sn4/kvroot &
java -jar $KVHOME/lib/kvstore.jar start -root $KVDATA/sn5/kvroot &
Finally, we deploy and configure the storage node. Now, since we are expanding the cluster, we need to distribute the data, and for that, there’s a command topology redistribute. The redistribute command works only if new Storage Nodes are added to make creating new Replication Nodes possible for new shards. With new shards, the system distributes partitions across the new shards, resulting in more Replication Nodes to service write operations. When we redistribute the store, the system automatically picks (without user intervention) the number of partitions from each of the existing shards, thus ensuring there’s no data hotspot as well as reducing human error.
The following example demonstrates adding a set of Storage Nodes (kvhost04 — kvhost05) and redistributing the data to those nodes
-> plan deploy-sn -zn Boston -host kvhost04 -port 5000 -wait
Executed plan 7, waiting for completion…..
Plan 7 ended successfully
kv-> plan deploy-sn -zn Boston -host kvhost05 -port 5000 -wait
Executed plan 8, waiting for completion…..
Plan 8 ended successfully
kv-> pool join -name BostonPool -sn sn4
Added Storage Node(s) [sn4] to pool BostonPool
kv-> pool join -name BostonPool -sn sn5
Added Storage Node(s) [sn5] to pool BostonPool
kv-> topology clone -current -name newTopo
Created newTopo
kv-> topology redistribute -name newTopo -pool BostonPool
Redistributed: newTopo
kv-> plan deploy-topology -name newTopo -wait
Executed plan 11, waiting for completion…
Plan 11 ended successfully
The redistribute command incorporates the new Storage Node capacity that you added to the BostonPool, and creates new shards. The command also migrates partitions to the new shards.
That’s it! You have successfully expanded the cluster.