Retrieval Augmented Generation (RAG) is a method where your Large Language Model (LLM) receives your prompt augmented with relevant facts or content to help it produce a better answer, which can make the AI response more reliable and informed. For example, RAG is highly valuable in business settings as it enables an LLM to answer users’ business-related queries by referencing extensive internal documentation in various formats. Employees benefit from RAG by easily accessing internally published information, which supports their daily responsibilities. Here are some common scenarios where a RAG-based solution improves business operations:
- Maintenance teams can use a RAG solution built around equipment manuals to quickly input a part name and issue, receiving instant troubleshooting steps—eliminating the need to manually search through lengthy documentation and saving considerable time.
- Quality assurance managers in software development can use RAG with call-center transcripts to generate summaries of the most frequent customer complaints for specific products.
- Medical staff can use RAG to sift through large volumes of medical literature and then formulate a treatment plan that is tailored to an individual patient’s needs.
These examples demonstrate that introducing RAG into business workflows offers substantial advantages—but how easy is it to implement? With Oracle Autonomous Database’s Select AI, the process is simple and straightforward. This blog will guide you through the steps of implementing RAG on Oracle Cloud Infrastructure (OCI).
Select AI RAG Overview
The Select AI RAG solution, whose OCI architecture is shown in Figure 1, has these key steps:
- The RAG administrator uploads all relevant documents to a knowledge base stored in an OCI Object Store bucket.
- The RAG administrator then triggers a database job that:
– Splits each document into multiple sections, each typically a few sentences long.
– Processes each section through an embedding model, which converts the text into a vector encoding, which is a list of numerical values that describe that section’s semantic meaning.
– Stores both the vector and the text section in a vector database table.
This job is executed with simple code within Autonomous Database (ADB), which also serves as the vector database for this solution. That job interacts with several OCI services, including OCI Object Store, OCI Generative AI service as well as built-in Autonomous Database capabilities including Oracle Machine Learning (OML) Notebooks (see Figure 1). And if you would like to rebuild this RAG solution in your OCI tenancy, you will find full instructions and code at this archive.
When using this RAG solution, a user enters a prompt—a question or command—into a frontend interface, such as APEX. This frontend sends the prompt to Autonomous Database, which then uses the embedding model (OCI Generative AI service of Figure 1) to recast the prompt as a vector. The vector database—Autonomous Database in this solution—performs a similarity search to identify the top N text chunks most semantically related to the prompt. These retrieved sections become the context documents, which are then passed to the LLM (also provided by the OCI Generative AI service, Figure 1) along with the instruction to use the retrieved context to compose a response. By requiring the LLM to use only the proprietary business knowledge stored in the knowledge base, rather than its built-in (outdated, incomplete, and drawn from public-domain sources) knowledge, responses are more accurate, current, and are tailored to internal needs. This approach also reduces the likelihood of speculation, incompleteness, or hallucination in the AI’s output.
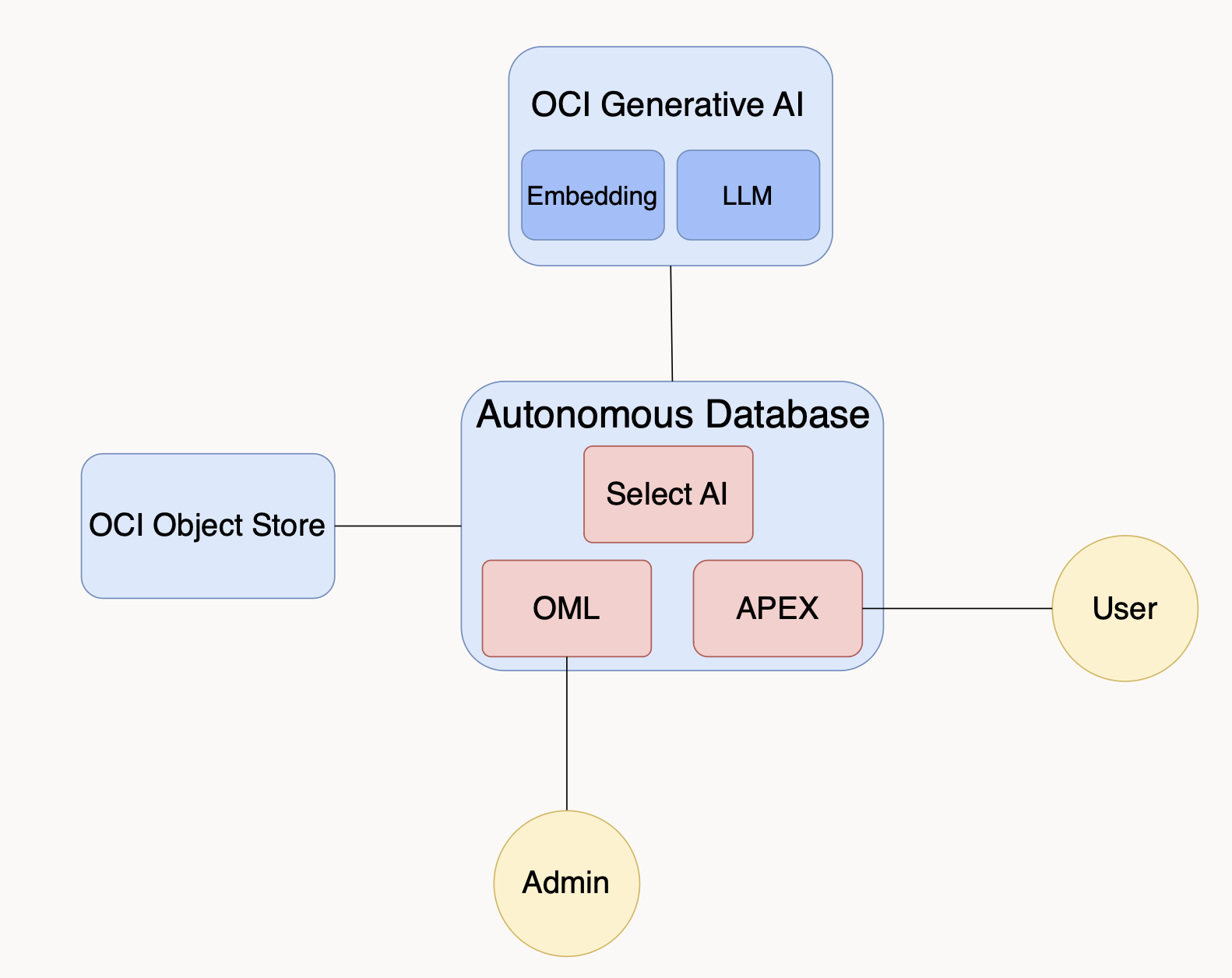
Figure 1. Architecture of the Select AI RAG solution deployed in OCI. Setup begins with the RAG admin who uses an OML notebook to load documents into Object Store. The RAG admin then triggers an ADB job that (i) splits those documents into text chunks that are (ii) recast into vectors by the GenAI embedding model, with (iii) texts and vectors stored in an ADB table. The user then accesses the APEX frontend to ask questions of the knowledge base via the Select AI RAG functionality detailed below.
If you opt for open-source embeddings and LLMs, which are also effective in RAG solutions, then this AI-powered solution can have a modest price tag. The principal compute costs will be the inferencing costs for the LLM and the embedding models, and the vector database. Consequently, RAG can be a very cost-effective way of keeping an AI-powered solution aware of one’s rapidly evolving business data without the need for expensive training and retraining of AI models on GPU.
Input Data: Novels from Project Gutenberg
In this RAG experiment, we use 20 novels from Project Gutenberg, stored in the Object Store bucket of Figure 1, with Figure 2 showing a screenshot of this data. Although this is a business-focused post, using well-known fictional stories enables quick validation of the RAG solution’s quality: since many readers are familiar with these novels, it is easy to judge whether the vector search behaves as expected and if the LLM’s summaries are accurate.
Figure 2: Sample of the 20 novels from Project Gutenberg, stored as text files in the Object Store.
Setting Up Select AI RAG
The experiment’s one-time setup code was run as SQL and PL/SQL using Oracle Machine Learning (OML) Notebooks within Autonomous Database (see Figure 1), since OML is convenient for running database scripts and viewing results inline. You can find the experiment notebook and further instructions archived in this GitHub repository. Here are steps:
Step 1: The Autonomous Database administrator creates the user account that will configure and deploy the RAG solution. In this example, that user is SELECT_AI_USER, granted with the following permissions by the admin:
create user SELECT_AI_USER identified by "<password>"; grant dwrole to SELECT_AI_USER; grant unlimited tablespace to SELECT_AI_USER; grant execute on DBMS_CLOUD to SELECT_AI_USER; grant execute on DBMS_CLOUD_AI to SELECT_AI_USER; grant oml_developer to SELECT_AI_USER;
Step 2: Create a PEM-formatted SSH key pair using an OCI cloud shell session with:
oci setup config
This generates a key pair in the `~/.oci` folder. That pair’s public key is ~/.oci/oci_api_key_public.pem, and that is copied into an API key in the RAG admin’s OCI account, while the private key ~/.oci/oci_api_key.pem is added to the following code snippet. You can run this within an OML notebook (see RAG_books_archive.dsnb for an example), as a SQL script, or within an APEX app:
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL (
credential_name => 'RAG_CREDENTIAL',
user_ocid => 'ocid1.user.oc1..aaaaaaaXXXsm72wxaakgqqq',
tenancy_ocid => 'ocid1.tenancy.oc1..aaaaXXXpbme4454xu7dq',
private_key => '
-----BEGIN PRIVATE KEY-----
MIIEvQIBADANBgkqhkiG9w0BAQEFAASCBKcwggSjAgEAAoIBAQC+5pZKurggk5aG
z60xAk/cx855jjeHmM6y86fjnMOQC6C7OKibloJh+WecIxPihOSiBrr/rYaMqOW0
+qeQH7OBnnvRwJzu7FHBiJckgF79sP+Zkc44iP0L1pdOxFWSQhJe7Tf6YFEF4CVa
...
QiCEbN9eZ3EJUvfKTCNb0WQQYplndCCXUTQlTwYNk3eWahoiNLrRQZQqisLESnTr
wQtGjFzioG3MX9txaijlzXvvZwjqc8aFvMA3yY63cODFur3AwqjqH1Lu223NDs99
5uzYVFg0Y4rfrG9XqUGEDbU=
-----END PRIVATE KEY-----
',
fingerprint => 'c7:6c:5a:29:f2XXXXXXX52:f7:83:31:46:b3:45'
);
END;
Be sure to tailor the OCIDs in the above so that they refer to the RAG developer’s OCI tenancy, and that the key fingerprint matches that in ~/.oci/config. This credential, named RAG_CREDENTIAL, allows ADB to interact with files stored in Object Store as well as the OCI Generative AI service of Figure 1.
Autonomous Database can also schedule OML notebook jobs to run regularly, to make your RAG solution responsive to new or updated documents in Object Store.
Creating the Select AI RAG Profile
In the next step, the SELECT_AI_USER creates the Select AI RAG profile:
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name => 'RAG_PROFILE',
attributes =>
'{"provider": "oci",
"credential_name": "RAG_CREDENTIAL",
"region":"us-chicago-1",
"oci_compartment_id":"ocid1.tenancy.oc1..aaaaXXXpbme4454xu7dq",
"vector_index_name": "RAG_INDEX",
"embedding_model": "cohere.embed-english-v3.0"}'
);
END;
The ‘RAG_PROFILE’ profile tells the database that the invoking user will use the RAG_CREDENTIAL to call the cohere.embed-english-v3.0 embedding model provided by OCI’s GenAI service when performing the vector embedding of the content that is stored in Object Store, Figure 1.
Encoding the Knowledge Base
With the configuration complete, launch the database job that uses OCI Generative AI service to process the knowledge base (here, 20 Project Gutenberg novels) into vectors stored within Autonomous Database. The job is easily launched via the below PL/SQL code:
BEGIN
DBMS_CLOUD_AI.create_vector_index(
index_name => 'RAG_INDEX',
attributes => '{"vector_db_provider": "oracle",
"vector_table_name": "RAG_VECTORS",
"object_storage_credential_name": "RAG_CREDENTIAL",
"location": "https://objectstorage.us-chicago-1.oraclecloud.com/n/<namespace>/b/<BucketName>/o/rag/doc/",
"profile_name": "RAG_PROFILE",
"vector_dimension": 1024,
"vector_distance_metric": "cosine",
"chunk_overlap": 64,
"chunk_size": 1024,
"refresh_rate": 1440
}');
END;
This job does the following:
- Collects all files (e.g., text files, Word documents, and text-based pdf documents) from Object Store location
- Splits their content into overlapping text chunks (1024 characters each with a 64-character overlap), per chunk_overlap and chunk_size
- Feeds each of those chunks into the embedding model to embed each chunk as a 1024-dimension vector, per vector_dimension
- Stores everything in the `RAG_VECTORS` table in Autonomous Database.
- Builds ‘RAG_INDEX’ on that table to accelerate similarity searches.
See the DBMS_CLOUD documentation for additional details about the DBMS_CLOUD_AI.create_vector_index() and related functions. Chunking and embedding the 20 novels takes approximately one minute, completing your Select AI RAG setup in Autonomous Database.
Querying the Knowledge Base
You are ready to ask questions using Select AI RAG via code. First, instruct a SQL script or OML notebook or database application to call Select AI RAG using profile RAG_PROFILE:
EXEC DBMS_CLOUD_AI.SET_PROFILE(profile_name => 'RAG_PROFILE');
Now submit your question using `SELECT AI NARRATE`. For example:

Figure 3. Example of a Select AI RAG query executing in an OML notebook
The above SELECT AI NARRATE command instructs the database to encode the question, recasting that text as a vector. It then performs a vector similarity search across the RAG_VECTORS table to find the top N text chunks whose encodings are most similar to the question’s encoding. The database then feeds these text chunks—known as the context—into a large language model (LLM) provided by the OCI Generative AI service (currently defaults to Meta’s Llama v3.3 LLM), along with the user’s question and the following instruction: use only the context to answer the question.
The above example question clearly refers to Moby Dick and is intended to spot-check Select AI RAG. The fact that the database reports only a single source, moby_dick.txt, indicates that all N text chunks returned by the vector similarity search were sourced from the expected Object Store document, and that these chunks contained sufficient relevant information for the LLM to generate a correct answer to the user’s question.
Additionally, note that the architecture diagram in Figure 1 illustrates Autonomous Database reaching out to the OCI Generative AI service for encoding and LLM-generated content. However, Autonomous Database also supports importing a wide suite of alternative open source models published in the ONNX format. This means that both encoding and LLM summarization could be performed in-database, rather than relying solely on the adjacent OCI Generative AI services. For more details, refer to the ONNX documentation.
Performing Vector Similarity Search
To manually inspect the top N text chunks returned by the above vector similarity search, replace NARRATE with RUNSQL as in Figure 4.
<img alt="Using SELECT AI RUNSQL to inspect vector similarity search results for .” height=”423″ src=”/wp-content/uploads/sites/44/2025/10/select_ai_runsql_figure4.png” width=”808″>
Figure 4. Using SELECT AI RUNSQL <question> to inspect vector similarity search results for <question>.
The ‘match_limit’ attribute controls the number of results, defaulting to N=5 but adjustable as follows:
BEGIN
DBMS_CLOUD_AI.UPDATE_VECTOR_INDEX(
index_name => 'RAG_INDEX',
attribute_name => 'match_limit',
attribute_value => '25'
);
END;
The above example would retrieve up to 25 similar text chunks. Note that Select AI RAG also caches its queries; so if you revise match_limit and rerun the same query, you will still see the same search results until you change a few characters in the prompt. Also note that the similarity_threshold attribute can be set to return fewer numbers of context documents that are more relevant.
Building an APEX Frontend for Select AI RAG
Oracle APEX is a powerful low-code platform for building secure and scalable database applications. Creating an APEX frontend for this RAG solution is straightforward because APEX is built in and closely integrated with Autonomous Database.
To begin, paste the necessary code snippets, as used in the OML notebook, into the APEX Code Editor—for example, the code to build or refresh the RAG solution (Figure 5).
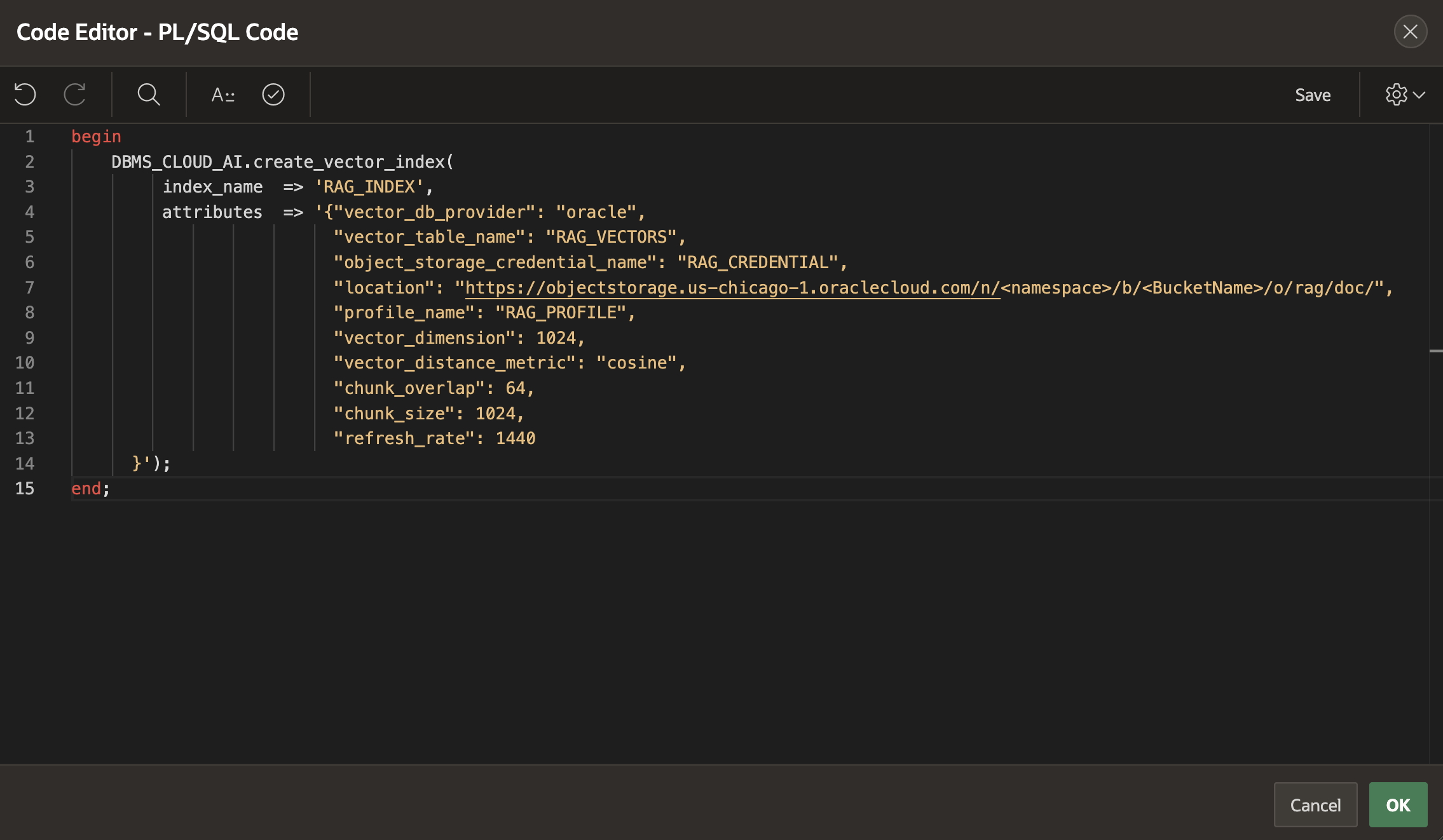
Figure 5. APEX Code Editor uses DBMS_CLOUD_AI.create_vector_index() to initiate the database job that will chunk and encode all documents stored in the Object Store knowledge base.
This APEX application must also collect the user’s question and then append that to a SELECT AI NARRATE SQL command, which is done via a dynamic action. In the APEX developer’s backend view, as shown in Figure 6, the user’s <question> is represented by APEX object :P3_QUESTION.
<img alt="PL/SQL for the dynamic action that is triggered when user asks that in turn calls the get_ai_response() function ” height=”506″ src=”/wp-content/uploads/sites/44/2025/10/apex_action_figure6.png” width=”600″>
Figure 6. PL/SQL for the dynamic action that is triggered when user asks <question> that in turn calls the get_ai_response() function shown in Figure 7.
When that object changes as the user inputs a new question, APEX automatically invokes the code snippet seen in Figure 6 to send the updated :P3_QUESTION into the custom get_ai_response() function defined in Figure 7, with that code snippet calling DBMS_CLOUD_AI.GENERATE() to run SELECT AI NARRATE <question> in Autonomous Database.
<img alt="PL/SQL code snippet that APEX uses to gather user’s , represented by p_prompt, that is sent into the DBMS_CLOUD_AI.GENERATE()call that runs SELECT AI NARRATE in ADB.” height=”547″ src=”/wp-content/uploads/sites/44/2025/10/apex_function_figure7.png” width=”511″>
Figure 7. PL/SQL code snippet that APEX uses to gather user’s <question>, represented by p_prompt, that is sent into the DBMS_CLOUD_AI.GENERATE() call that runs SELECT AI NARRATE <question> in ADB.
Figure 8 below shows the APEX user interface that displays Select AI RAG’s answer to a question about Dickens’ A Christmas Carol.
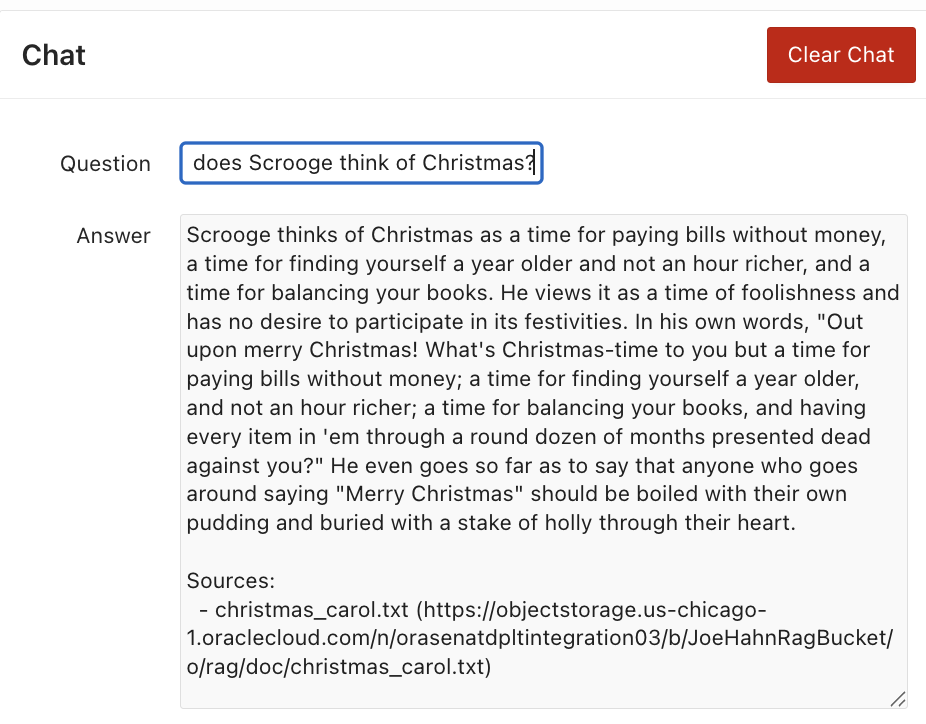
Figure 8. APEX UI showing SELECT AI RAG’s answer to A Christmas Carol question.
Main Findings
This blog demonstrates how easy it is to build a RAG solution that allows one to query large, unstructured business documents using Select AI RAG in Autonomous Database. Once configured, the resulting knowledge base is then available to all Autonomous Database users, and is easily accessed via a tailored application frontend that is rapidly built using the low-code Oracle APEX application development platform.
Suggested Next Steps
If you are interested in Select AI RAG for your Oracle database, watch this step-by-step video walkthrough of this content. Then try executing the sample code and instructions in an Autonomous Database (ADB) that can reside in your OCI tenancy, or in OCI’s free tier, or in other clouds via Oracle Database@Azure, Database@AWS, or Database@Google.
Additional information
For more information, refer to the below resources:
