The question often starts with another question: “How can I protect my database with zero data loss and the least amount of downtime”?
The bigger the database becomes, the more creative the solutions, and with that creativity comes complexity and tradeoffs. However, there’s only one way to have proper disaster recovery: replicating the data to at least one other physical site.
There are several ways to get the data from A to B, and that’s where it gets interesting. When comparing software to a simpler example, we can visualize it with a screw. You won’t use a hammer to get the screw in the wall, will you? Either you will damage the screw or damage the wall rather than drive the screw nicely and cleanly in the wall as you intend. Eventually, it will work. But we can agree a screwdriver would be way more suitable for this particular job than a hammer.
The same principle applies to software: Use the correct tool for the job.
Let’s now focus on the proper protection of the Oracle database. This blog post will focus on storage replication and what happens or could happen when you use this technique on Oracle databases.
Looking inside the storage replication technique, you need to understand that it uses an elementary principle: The writes on the source must also be written at the destination side. You would think this is a rock-solid, simple principle, right? Not really! What if that single write corrupts your database? The mechanism is unaware of what happens in the block and happily sends it to the destination. Hence, at that point, you’ve lost your standby site as the same corruption occurs on both sites. The often-used argument nowadays is that this is less prone to errors in modern systems, as the write is issued twice from the system—once to array A, once to array B. But…what if the write logically corrupts your database? Both sites become useless again, and you often won’t realize it until too late.
Storage replication can’t detect block corruption, but it helps to protect the database, right? Well, that is not really the case. For example, what if you accidentally delete a file? That deletion gets replicated, and the file is also lost in the remote site, bringing you to the same disastrous situation. It does not get better as we expand the possible use cases of a standby database.
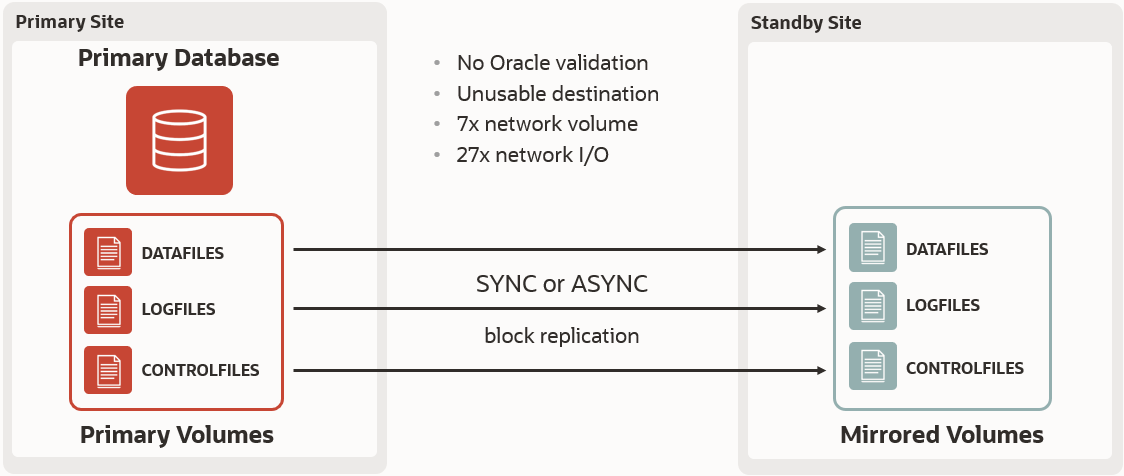
What if you want to offload your read-only analytical queries or reports to the remote site while the replication goes on? Mirrored copies are not usable for this either, which means you not only lose out on a technique to offload the workload but also the continued operational validation of your standby environment that you get from doing so. It becomes clear at this point that, although storage replication faithfully copies your data, it can faithfully copy any type of corruption and make the mirrored site useless and at the worst possible time.
It still happens today. Recently, I was asked to join a meeting for a large retailer with more than 200 physical stores and around 30,000 employees in Europe. They were facing a severe issue with their disaster recovery plan. I am always happy to lend a hand and provide guidance in these situations. It turned out that a correctly configured and well-tuned storage replication system was facing a problem. All the systems were virtualized and running from these boxes with Oracle databases inside the machines. At a given point in time, the primary storage array faced a cold shutdown. And when we realized that all VMs were running here, this became a serious issue. Even worse? Not all writes were completed on the target system! That left around 75% of the environment completely unusable. The problem escalated as the full non-production environment needed to be restored from backup and required fresh clones from their production systems. Luckily the production writes were completed in time, and we were able to open again on the other side. The whole restoration took more than ten days. Imagine what could have happened if the production systems were impacted too?
That was a recent case and from a correctly tuned and configured system. Despite all good and well-meaning precautions, would you feel comfortable that this kind of real-life storage replicated disasters could happen in your modern-day disaster recovery configuration? Does it happen frequently? No, like any disaster of this magnitude, it is rare, but it does indeed still happen.
Remember the story of the screw? There is a better tool to protect Oracle databases: Oracle Data Guard.
Oracle Data Guard, an important MAA technology, operates on a simple principle. It uses all the changes made by the database transactions, called redo. Data Guard uses the most straightforward principle: ship redo, then apply redo. Redo includes all of the information needed by the Oracle database to recover the database transactions. A production database, referred to as the primary database, transmits redo to one or more independent replicas, referred to as standby databases. Oracle Data Guard standby databases are in a continuous state of recovery, validating and applying redo to maintain synchronization with the primary database. Only Oracle Data Guard can achieve this validation. Only the database knows what needs to be in the block. Oracle Data Guard guarantees that the data written to the standby database is correct.
Oracle Data Guard will also automatically resynchronize a standby database that becomes temporarily disconnected from its primary database due to a network or standby outage.
![]()
Storage replication mirrors all the blocks modified in the database, including data files and log files. When used with write-intensive applications, the overhead of storage mirroring requires more network bandwidth and can negatively impact the database performance.
Conversely, the redo transport used by Oracle Data Guard bypasses the I/O layer, reducing the transfer to what is strictly required to apply the modifications on the standby site.
Oracle Data Guard replication dramatically reduces the amount of data transmitted and verifies the blocks before and after the transmission to ensure they are logically correct.
Oracle Data Guard comes at no additional cost with Oracle Enterprise Edition. It allows creating and maintaining standby databases, performing role transitions (switchover and manual or automatic failover), and using the standby for read/write testing in Snapshot Standby mode.
The standby database can execute read/only workloads while applying the redo arriving from the primary. This read-only capability at the remote site requires the Oracle Active Data Guard option. Oracle Active Data Guard provides additional capabilities such as offloading operational activities, executing fast incremental backups, and rolling upgrades. DML Redirection is a perfect example of these capabilities, allowing occasional DML operations while working on the read-only standby database. We have blogged about this feature earlier.
To conclude, Oracle Data Guard (or Active Data Guard) is the only tool fit for fully protecting the data stored in the Oracle Database. As highlighted in this paper, its approach is superior to storage-level replication.
For more details, refer to:
Oracle.com/goto/dataguard
Oracle.com/goto/maa
You can also follow me on Twitter at @ludodba or Oracle MAA at @OracleMAA for updates.
