Having a scale-out strategy can be a game-changer for critical applications, particularly when workloads can spike unpredictably due to seasonal demand, marketing campaigns, or business growth. Without a plan to distribute workloads efficiently, a sudden surge in read or write operations can overwhelm the primary database and risk performance degradation, ultimately leading to scaling up infrastructures or changing application architectures.
Oracle Active Data Guard, the leading solution for data protection, gained an excellent reputation thanks to its highly efficient replication technology, comprehensive end-to-end data validation, and advanced features such as Automatic Block Repair and Fast-Start Failover. But key features of Active Data Guard include Real-Time Query and DML Redirection, which enable linear read-only scalability, and much more.
By leveraging Oracle Active Data Guard’s scale-out capabilities, companies can ensure their infrastructure is capable of absorbing unexpected load increases by distributing read-only traffic across multiple standby databases. This proactive approach not only preserves the performance of the primary system but also provides the flexibility to scale reads linearly without significant effort. In environments where downtime or latency can directly impact revenue and customer satisfaction, Oracle Active Data Guard is an unmissable solution.
Consistent, linear scalability for read-only workloads
With Real-Time Query, standby databases can handle read-only workloads, freeing up critical resources on the primary database for read/write operations and boosting overall transaction throughput. This creates a dual advantage: the primary database can focus on read/write workloads, while standby databases provide linear read-only scalability. Each standby database is a complete replica of the primary database, offering a scale-out, shared-nothing architecture for data access.
The image below illustrates how offloading most read operations from the primary database leads to higher read/write throughput, thanks to the additional computational resources freed up.

Real-Time Query works with synchronous or asynchronous standby databases. When synchronous, the reading sessions can opt in for external consistency, which ensures the reads are fully up to date (consistent) with the very last transactions committed on the primary database.
Extend the application footprint beyond read-only services with DML redirection
With Oracle Active Data Guard, applications can connect to a standby database and perform DML operations through DML redirection. This feature transparently redirects write operations to the primary database while making the transaction appear to execute on the standby database. It ensures ACID compliance, allowing only the active session to view changes until the transaction is committed.
This capability opens new opportunities for read-heavy applications that occasionally write data. Previously, such applications had to connect to the primary database for any write operation. Now, they can connect exclusively to the standby database, offloading all reads while seamlessly redirecting writes to the primary.
My blog post regarding DML redirection can be found here.
Not just selects: offload AI workloads and more!
Thanks to the ONNX runtime included in the Oracle Database, machine learning models can be executed close to the data with minimal latency or data movement. Once the models are loaded into the primary database, they also become usable at the standby database, so that inferencing can be offloaded there.
Oracle Active Data Guard’s DML redirection ensures that any vectors or metadata generated during the inferencing process are transparently and transactionally written back to the primary database.
This architecture is especially powerful for AI workloads across large datasets due to its scalability characteristics: it supports end-to-end AI workflows, from embedding generation to retrieval-augmented pipelines (RAG) to vector search, without sacrificing the performance of the primary database, making Oracle Database a compelling database platform for scalable AI-enabled applications.
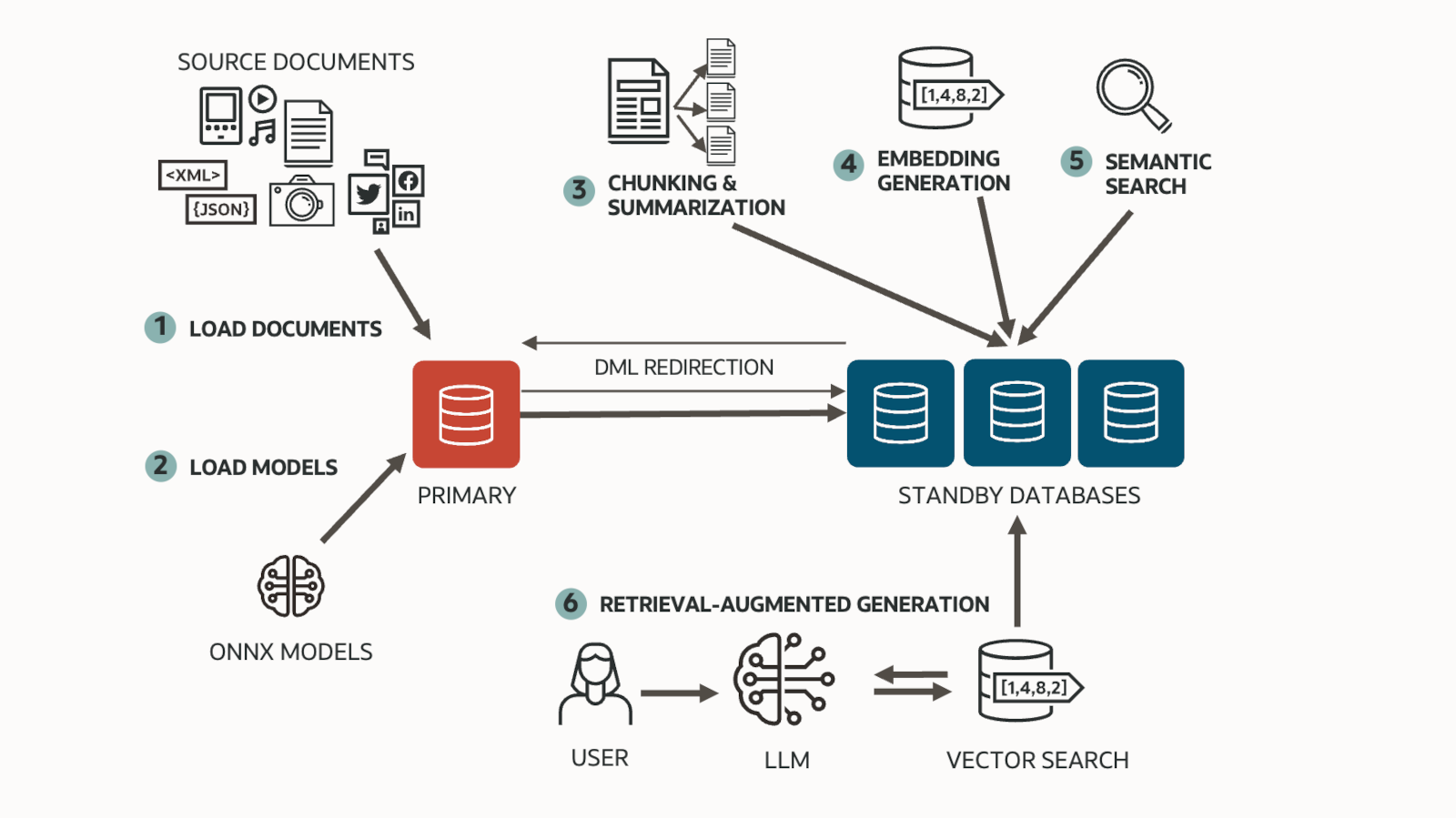
Distribution of the scale-out workload
The buffer cache plays a critical role when offloading data to read-only services. During recovery, the affected blocks must be loaded into the cache, consuming a significant portion. Simultaneously, sessions querying the standby database perform conventional path reads, loading data from the disk into the buffer cache.
With this in mind, there are two primary approaches to populating the cache:
-
Distribute the Same Read-Only Service Across All Standby Databases:
This straightforward configuration allows applications to distribute read workloads across replicas evenly. However, it provides fewer performance benefits, as multiple standby instances will likely cache the same hot blocks, leading to redundancy. -
Create Purpose-Built Services:
In this approach, each application module or microservice is assigned a dedicated service tailored to its specific needs. These services can be strategically placed across different instances, clustering blocks for particular use cases and increasing the likelihood of cache hits. This method is especially beneficial for microservice deployments, where each read-only microservice accesses its data portion on a dedicated standby database. It best suits Oracle Real Application Clusters (RAC), as services can be started on a subset of instances, but it is equally effective for multiple single-instance standby databases.
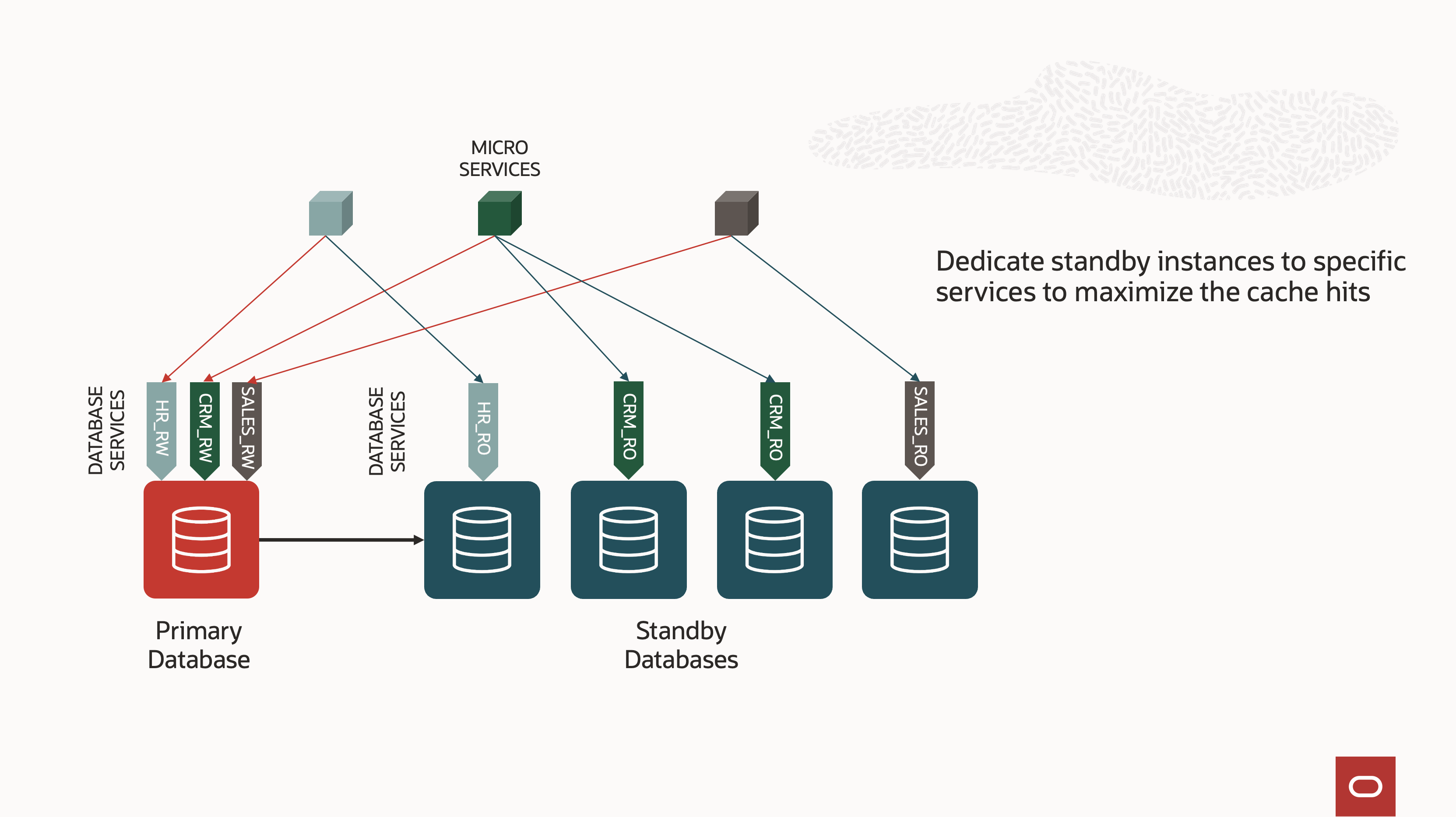
Offloading read operations from the primary database also reduces pressure on its buffer cache, as fewer blocks must be cached solely for reading purposes. This, in turn, increases the available buffer cache for dirty blocks, thereby reducing database writer (DB writer) activity.
Similarly, workloads running on Oracle Cloud Infrastructure or engineered systems can take advantage of Database In-Memory on the standby database. Tables can be selectively populated in memory based on the specific requirements of individual services, ensuring efficient resource utilization and optimized performance.
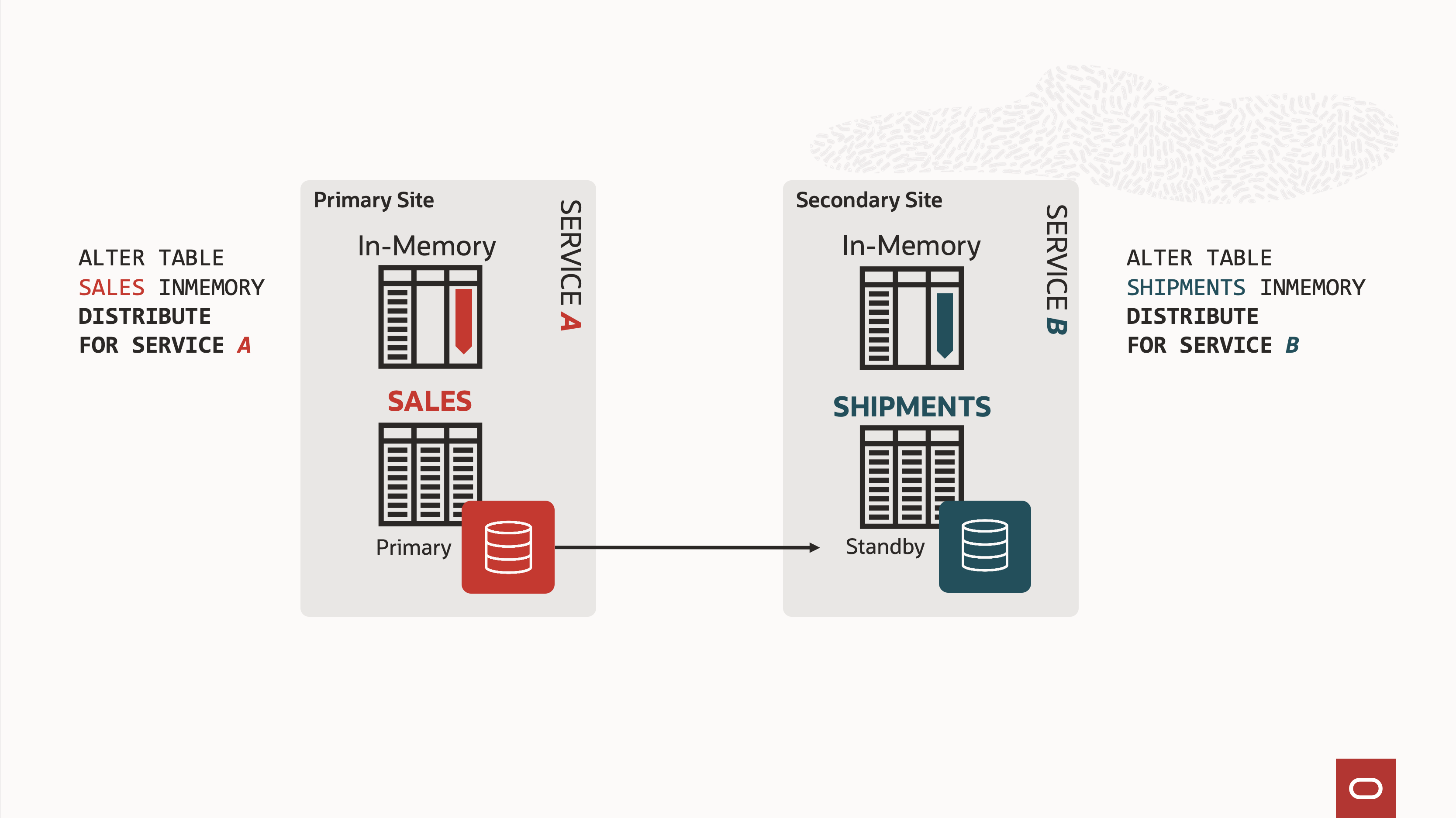
When the services are optimally distributed, this feature can dramatically extend the in-memory usable space, providing high-speed in-memory columnar scans for the relevant tables.
For example, the primary database can be dedicated exclusively to OLTP workloads, while tables used for reporting are populated on a standby database with a larger in-memory area in the SGA. This setup allows reports to leverage columnar scan orders of magnitude faster than conventional reads on heap tables.
Use multiple data sources in your application
In modern applications, especially those built on a microservice architecture, it is essential to have at least two distinct data sources: one for read/write operations and another for read-only workloads.
By configuring a dedicated read-only data source, applications can easily offload read operations to standby databases, effectively scaling out the architecture for all non-writing operations. This separation not only optimizes resource utilization but also enhances application responsiveness. Moreover, having multiple standby databases ensures that read-only services remain available during a switchover between the primary and one of the standby databases. This provides seamless continuity for the application modules (or microservices) relying on read-only services.
Simplifying the connectivity to many services and standby databases
When scaling applications across a farm of read-only replicas, a key architectural challenge is efficiently redirecting the application to the appropriate standby database, especially when multiple replicas provide the same services. This requires careful consideration of factors such as standby database availability, replication lag (particularly for applications requiring consistent or minimally stale reads), current load on each standby database, and geographic proximity to the application server or container, as latency plays a critical role in overall performance.
Global Data Services (GDS) seamlessly addresses this challenge by offering a single entry point for the application. Think of GDS as an intelligent, database-aware reverse proxy with complete visibility into the backend databases and their services. Standby databases continuously report their load and replication lag to GDS, allowing it to automatically block client connections to any database that doesn’t meet predefined performance criteria. GDS is also location-aware, intelligently routing client connections to the closest replica, thereby minimizing latency and enhancing application performance.
Moreover, GDS is built on the industry-leading SQL*Net protocol, giving it real-time awareness of which databases are actively serving the required services. Applications leveraging GDS can fully benefit from Oracle driver features such as automatic retries, session draining, and application continuity, ensuring high availability and optimal performance across distributed environments.
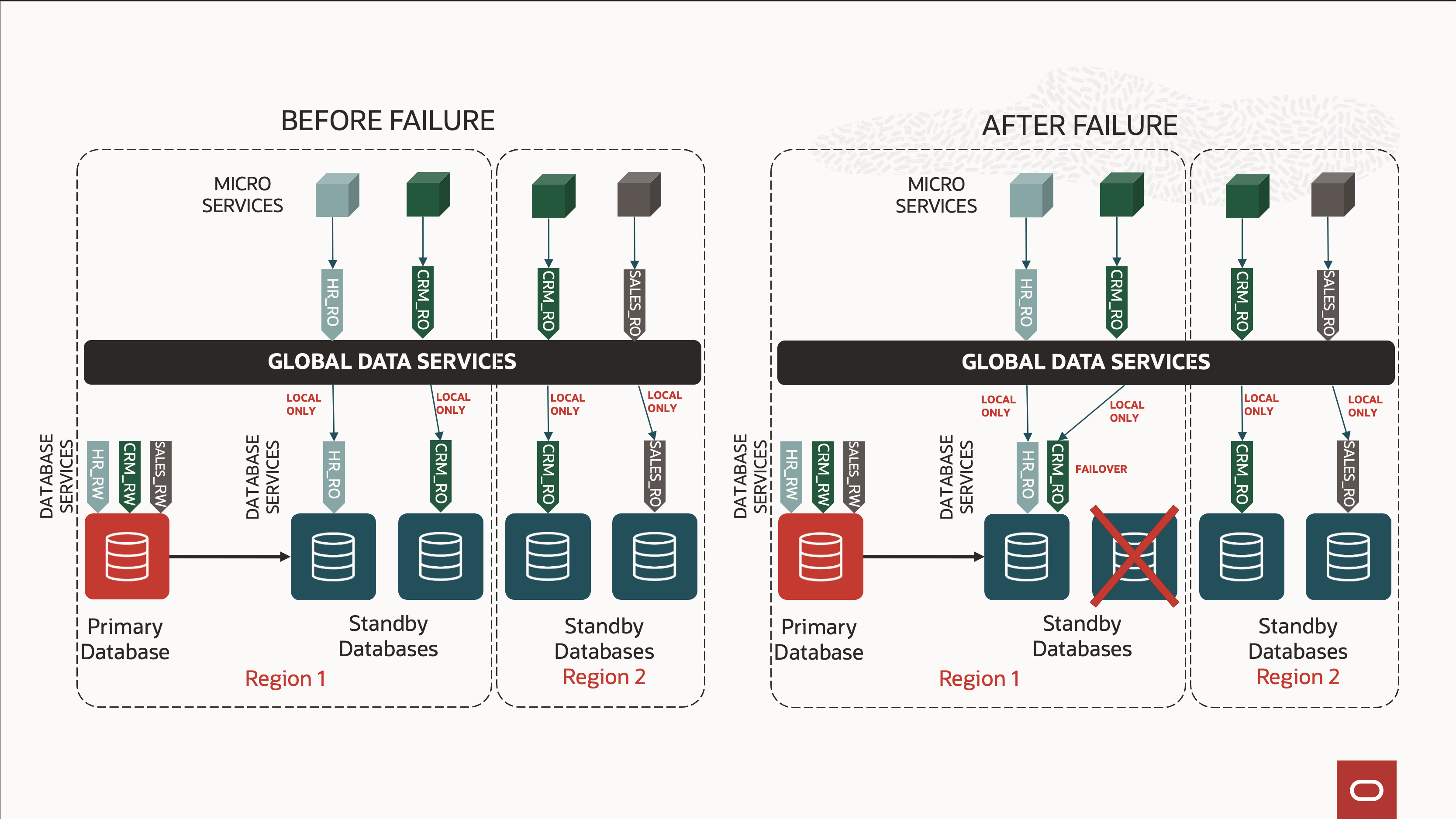
Ultimately, applications can leverage data sources that connect to GDS endpoints, specifying the required service using high-availability parameters without worrying about the underlying replication topology or the number of standby databases involved.
While GDS introduces an additional layer, it can significantly simplify the overall architecture. Without GDS, customers would need to manually update data source URLs (connection descriptors) each time standby databases are added or removed. They must also manage standby database staleness and handle connection redirection accordingly. GDS eliminates these complexities, providing a seamless, intelligent solution that ensures optimal connectivity and performance with minimal operational overhead.
Oracle Active Data Guard scalability in the Oracle Database ecosystem
While Oracle Active Data Guard offers linear read-only scalability and supports DML execution on standby databases, it does not provide complete read/write scalability.
Oracle Real Application Clusters (RAC) is the ideal solution for customers seeking exceptional read/write scalability and performance. RAC can scale read/write workloads across dozens of nodes while maintaining sub-millisecond transaction latency. Oracle Active Data Guard and Real Application Clusters complement each other to provide the best scalability.
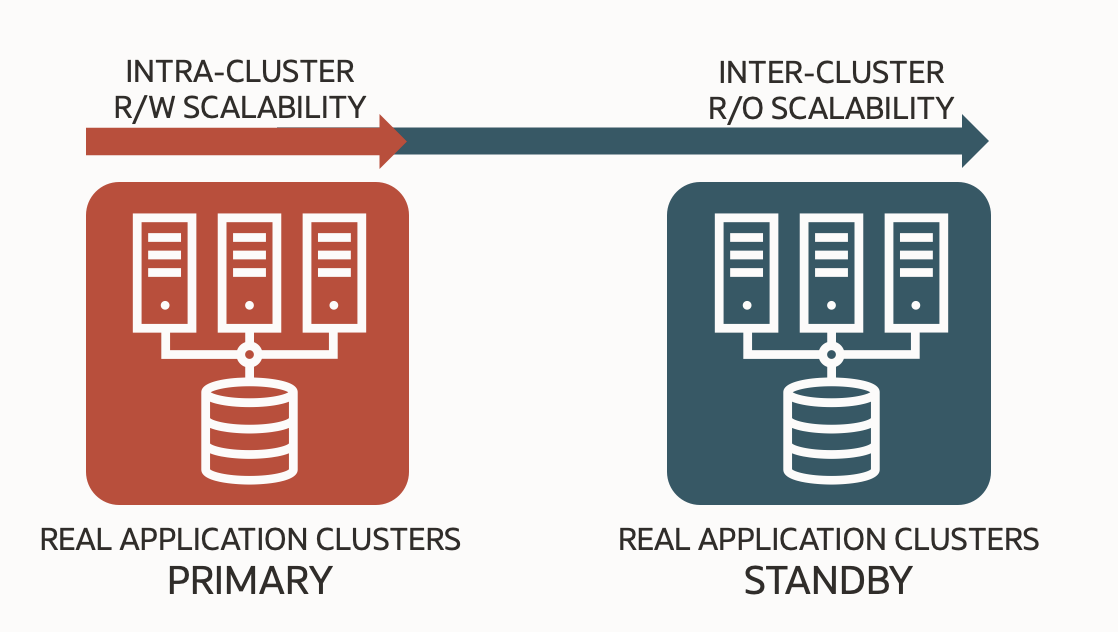
For even greater scalability, Oracle Exadata and Exadata Database Services on OCI take RAC performance to the next level, delivering near-linear storage scalability and unique features designed for extreme performance and ultra-low I/O latency (14μs on Exadata X11).
Oracle Exadata powers some of the world’s most significant and critical workloads. However, for organizations needing read/write scalability and data distribution, Oracle Globally Distributed Database extends these capabilities across Exadata clusters and regions, providing unmatched performance and global reach.
Finally, Oracle True Cache offers many of Active Data Guard’s scale-out capabilities without requiring high-capacity storage. It delivers consistent and up-to-date replicas for query offloading, without persistently storing the entire database copy.
