O Full Stack Disaster Recovery é um serviço de orquestração e gerenciamento de recuperação de desastres da Oracle Cloud Infrastructure (OCI) que fornece recursos abrangentes de recuperação de desastres para todas as camadas de uma pilha de aplicativos, incluindo infraestrutura, middleware, banco de dados e aplicativo.
Neste hands-on, vamos demonstrar como utilizar o FSDR em aplicações implantadas no Oracle Cloud Infrastructure Kubernetes Engine (OKE). Para isso, usaremos o Ghost uma plataforma open source de blog e newsletter como aplicação de exemplo, configurada em um ambiente de microsserviços que integra outros serviços da OCI, como Load Balancer (Ingress NGINX) e Block Volume (Persistent Volume).
Na demonstração, exploraremos a abordagem de Switchover, uma das mais utilizadas em cenários de recuperação de desastres.
O Switchover realiza uma transição ordenada, encerrando os aplicativos na região primária e ativando-os na região standby. Esse processo garante consistência dos dados e continuidade dos serviços, permitindo validar na prática a resiliência da aplicação em situações de desastre planejado.
Objetivos:
- Provisionar um cluster OKE em cada região (primário e standby).
- Provisionar um bucket em cada região (primário e standby).
- Implantar o aplicativo de demonstração Ghost Blog com MySQL Lite, utilizando Persistent Volume (Block Volume) para armazenamento e Ingress NGINX como Load Balancer.
- Configurar os planos de DR Primário e Standby no FSDR.
- Executar Switchover e validar o funcionamento do Blog e dos recursos após a execução dos planos de DR.
Pré-requisitos:
Privilégios de acesso na Oracle Cloud Infrastructure para:
- Gerenciar Policies (IAM Policies) no nível do tenancy.
- Gerenciar Virtual Network (VCN), Oracle Kubernetes Engine (OKE), Full Stack Disaster Recovery (FSDR) e Storage no compartment.
Arquitetura:
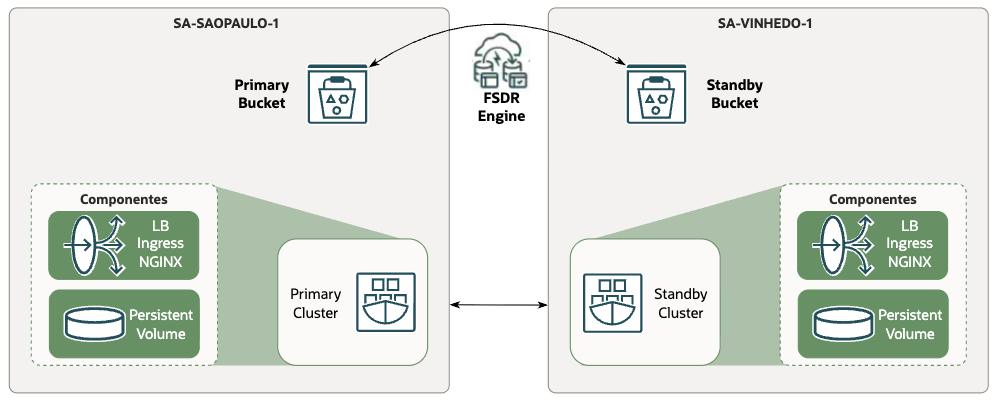
Dynamic Group e IAM Policies:
Para configurar o FSDR é necessário permitir que ele gerencie recursos do Oracle Kubernetes Engine (OKE). Para isso, deve-se criar um Dynamic Group e uma Policy com os respectivos statements.
Criando o Dynamic Group:
- Nome: DG-FSDR
- Rule:
- All {instance.compartment.id = ‘<compartment_ocid>’}
- All {resource.type=’computecontainerinstance’}
No campo <compartment_ocid>, insira o OCID do compartimento onde estão provisionados os recursos do OKE.
Criando Política:
- Nome: Policy-FSDR
- Políticas:
- Allow dynamic-group DG-FSDR to manage object-family in compartment <compartment_name>
- Allow dynamic-group DG-FSDR to manage cluster-family in compartment <compartment_name>
Substitua <compartment_name> pelo nome do compartimento onde os recursos do OKE estão provisionados.
Provisionando os clusters OKE primário e standby:
Criar dois clusters OKE, um primário e outro standby, ambos com a mesma configuração. Em cada região foi criada uma Virtual Cloud Network (VCN) com três subnets: subnet-node, subnet-api e subnet-lb, sendo a subnet-lb a única configurada como pública. Para mais detalhes sobre o provisionamento de um cluster OKE e a configuração de rede necessária, consulte Criando um Cluster OKE e Configuração dos Recursos de Rede para Criação Cluster OKE.
Basic setup
- Nome: primary-cluster / standby-cluster
- Kubernetes version: v1.33.1
Network setup
- Network Type: Flannel overlay
- VCN: selecione a VCN e a subnet para o API endpoint
- Load balancer: selecione uma subnet pública para o load balancer
- Deixe as demais opções desmarcadas.
Node pool
- Nome: primary-cluster-node-pool / standby-cluster-node-pool
- Kubernetes version: v1.33.1
- VCN: selecione a subnet para o node pool
- Shape: VM.Standard.E3.Flex (2 OCPU, 8 GB de memória)
- Node count: 3
- Deixe as demais opções desmarcadas.
Finalize o provisionamento de cada cluster nas regiões primário e standby.
Cluster primário

Cluster standby

Provisionando os Bucket primário e standby:
O FSDR utiliza buckets para armazenar os logs de operações. Para isso, devem ser criados dois buckets, um na região primária e outro na região standby.
- Nome: primary-bucket / standby-bucket
- Storage tier: Standard
Finalize o provisionamento de cada bucket nas regiões primário e standby.
A Oracle recomenda que você siga estas diretrizes ao criar o bucket para o FSDR:
- Use um bucket dedicado separado para cada grupo de proteção de DR.
- Use o nível de armazenamento Padrão, não o Arquivo.
- Não configure a replicação para este bucket de armazenamento de objetos.
- Não use este bucket para gravar outros dados, reserve-o exclusivamente para uso em logs de um grupo de proteção de DR.
- Certifique-se de que o bucket de armazenamento de objetos seja gravável pelo usuário que executa as execuções do plano de DR.
- Certifique-se de que nenhuma política de retenção esteja definida no bucket de armazenamento de objetos.
Configurando o Aplicativo de Demonstração (Ghost Blog & Newsletter)
Nesta etapa, vamos iniciar a configuração do aplicativo de demonstração no cluster primário. O ambiente será composto por um Ghost Blog utilizando MySQL Lite para armazenamento dos dados. O banco de dados será persistido em um Persistent Volume (Block Volume), garantindo que as informações permaneçam salvas mesmo em caso de reinício dos pods.
O tráfego externo será exposto por meio do Ingress NGINX configurado como Load Balancer, permitindo que o aplicativo seja acessado de forma simples e escalável. Essa arquitetura reflete um cenário real de microsserviços rodando no Oracle Kubernetes Engine (OKE), simulando as dependências típicas de aplicações modernas em nuvem.
Além de servir como base para a validação do FSDR, essa implantação mostrará na prática como integrar componentes de rede, armazenamento e aplicação dentro de um cluster Kubernetes.
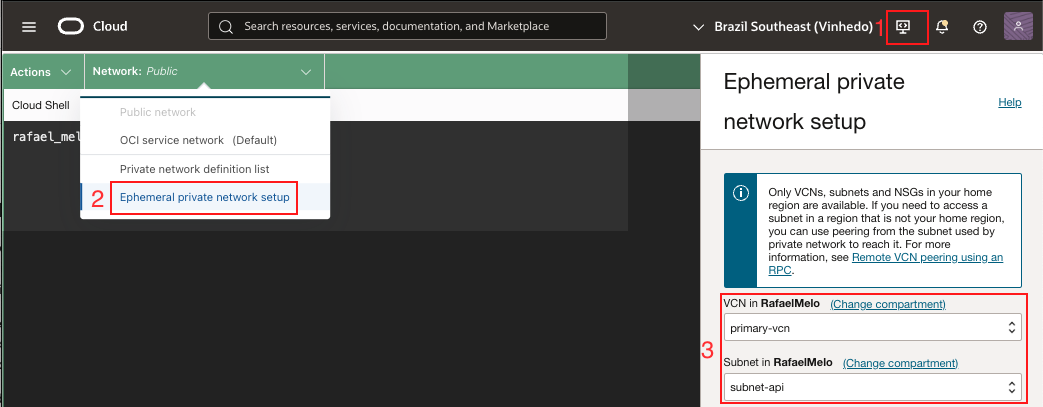
Acessando Cluster primário:
Abra o Cloud Shell e, no menu de rede, selecione a opção ephemeral private network. Em seguida, escolha a VCN e a subnet associadas ao OKE (por exemplo, primary-vcn e subnet-api). Para mais detalhes consulte Cloud Shell Private Networking.
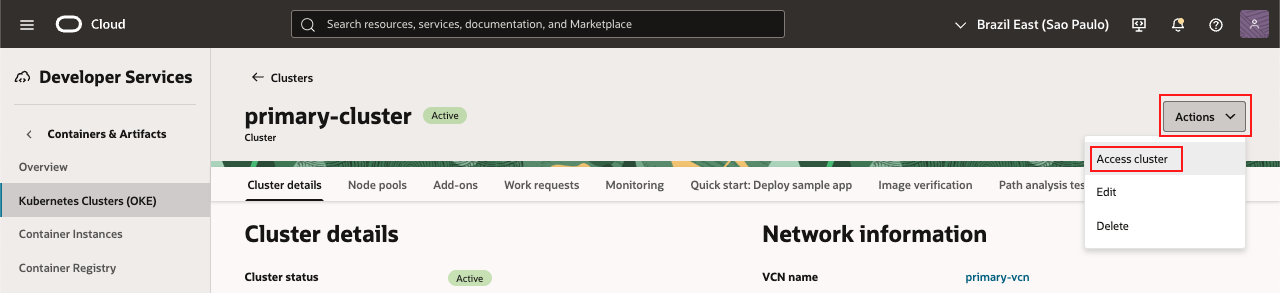
No cluster primário, clique em Actions e selecione Access Cluster.
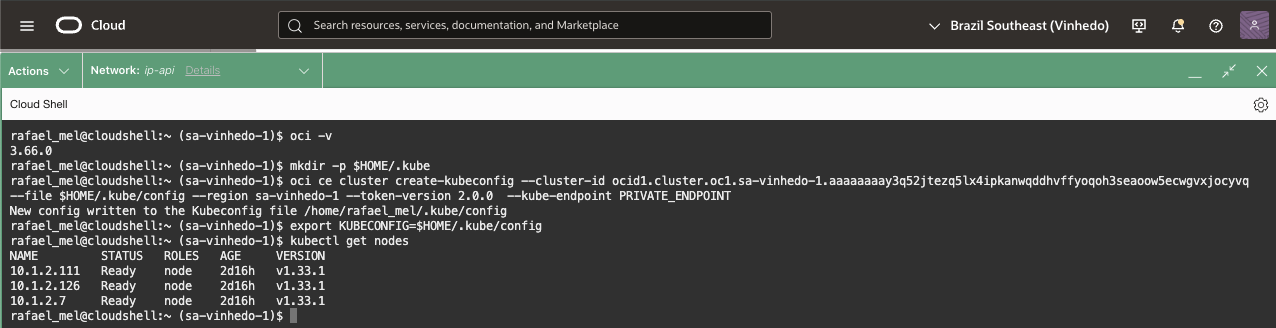
Em seguida, siga a configuração recomendada pelo assistente. Ao final, valide o acesso executando o comando kubectl get nodes no Cloud Shell:
Configurando o Ingress NGINX:
Com o acesso ao cluster já estabelecido, avançaremos para a próxima etapa do laboratório. Primeiro, vamos implantar o Ingress NGINX, que será responsável por atuar como controlador de tráfego e balanceador de carga dentro do cluster. Em seguida, faremos o deploy da aplicação de demonstração Ghost Blog, garantindo que ela esteja exposta externamente por meio do Ingress.
Realize o deploy do Ingress NGINX a partir do repositório oficial utilizando o comando abaixo:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.13.2/deploy/static/provider/cloud/deploy.yaml
Se preferir, é possível adicionar o bloco abaixo para atualizar o deployment e utilizar o novo modelo de load balancer do tipo flexible, definindo os valores mínimo e máximo de shape:
annotations:
service.beta.kubernetes.io/oci-load-balancer-shape: "flexible"
service.beta.kubernetes.io/oci-load-balancer-shape-flex-min: "10"
service.beta.kubernetes.io/oci-load-balancer-shape-flex-max: "1000"
Verifique se o controlador e o serviço do Ingress NGINX estão em execução. Para isso, execute o comando: kubectl get svc -n ingress-nginx

Identifique o valor do EXTERNAL-IP do Load Balancer. Em seguida, configure o host ghost.example.com apontando para esse endereço IP no arquivo de hosts da sua máquina local:
- No Linux/macOS: /etc/hosts
- No Windows: C:\Windows\System32\drivers\etc\hosts
<EXTERNAL-IP> ghost.example.com
No meu caso ficou:
163.176.210.135 ghost.example.com
Deploy do aplicativo de demonstração Ghost Blog
Agora vamos realizar o deploy do aplicativo de demonstração Ghost Blog utilizando o manifesto disponível em: Manifesto Ghost Blog.
Esse manifesto foi criado para simplificar a configuração e fará automaticamente as seguintes ações:
- Criará o Namespace ghost-ns
- Provisionará um PersistentVolumeClaim (PVC) chamado ghost-pv-claim, utilizado para armazenar o banco de dados SQLite do Ghost Blog
- Implantará o Deployment do Ghost Blog com a imagem oficial ghost:5-alpine
- Criará um Service para expor o pod internamente no cluster
- Configurará um Ingress para publicar a aplicação no Ingress NGINX (Load Balancer externo)
Execute o comando abaixo para aplicar o manifesto e realizar o deploy do Ghost Blog no cluster:
kubectl apply -f https://raw.githubusercontent.com/euoraf4/blog-ghost/refs/heads/main/deploy.yaml
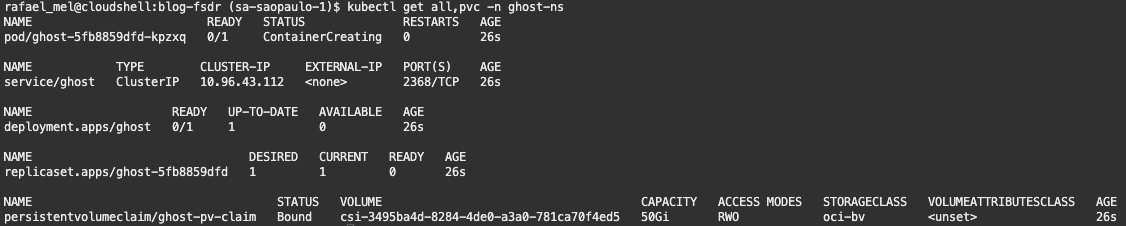
Após aplicar o manifesto, é importante validar se todos os recursos foram criados corretamente no namespace ghost-ns. Para isso, execute o comando abaixo:
kubectl get all,pvc -n ghost-ns
Para realizar o primeiro acesso, utilize a URL: http://ghost.example.com.
Agora vamos acessar a console administrativa do Ghost Blog para criar um post de teste antes de avançarmos para a configuração do FSDR. Acesse a URL: http://ghost.example.com/ghost/.
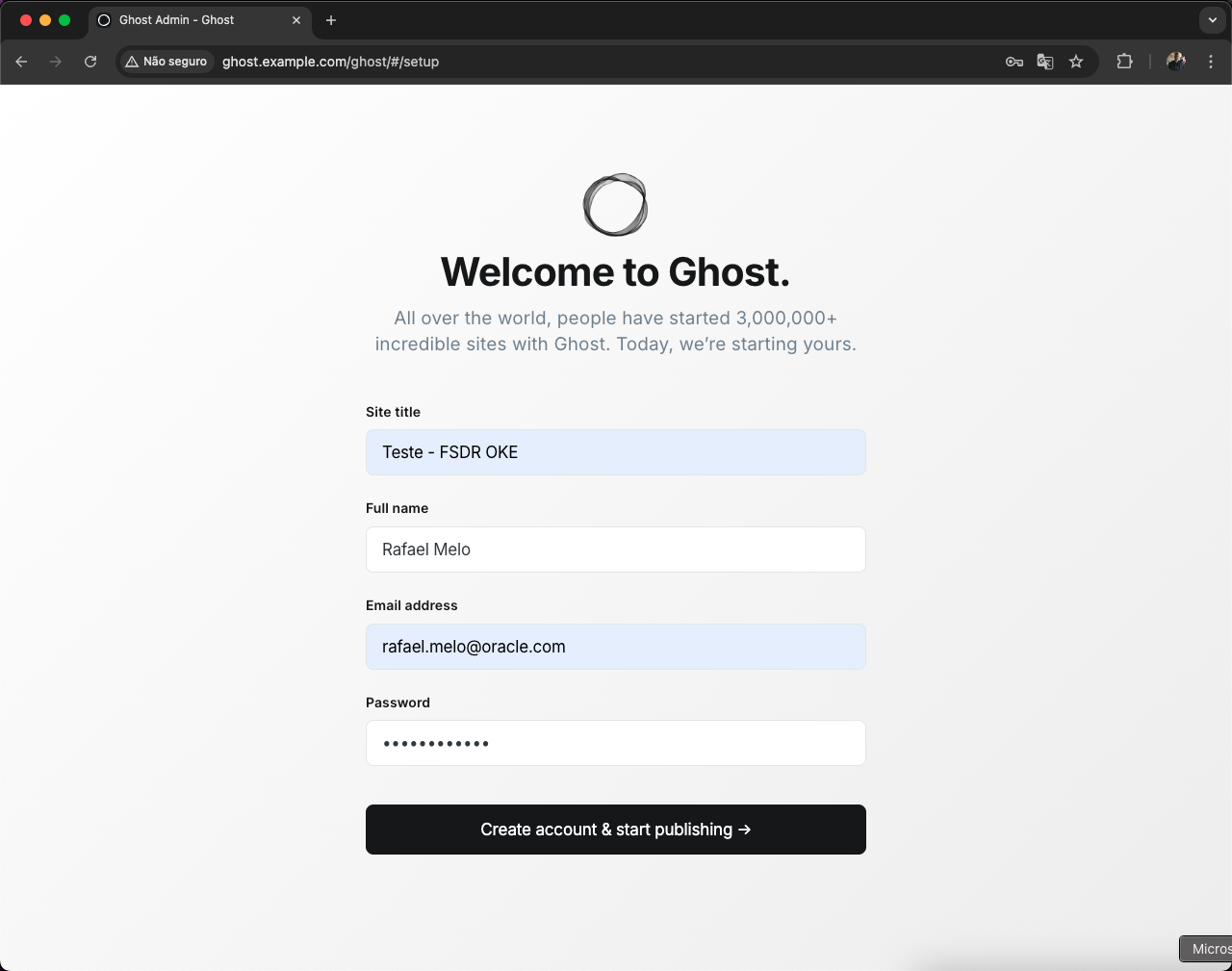
Na primeira vez que abrir essa página, será exibida a tela de configuração inicial do Ghost Blog. Nela, você deve informar os dados básicos do seu blog e criar o usuário administrador.
Preencha os seguintes campos:
- Site title: título do blog (exemplo: Teste – FSDR OKE)
- Full name: seu nome completo
- Email address: e-mail do administrador
- Password: senha de acesso
Após preencher, clique em Create account & start publishing para concluir a configuração e liberar o acesso ao painel administrativo.
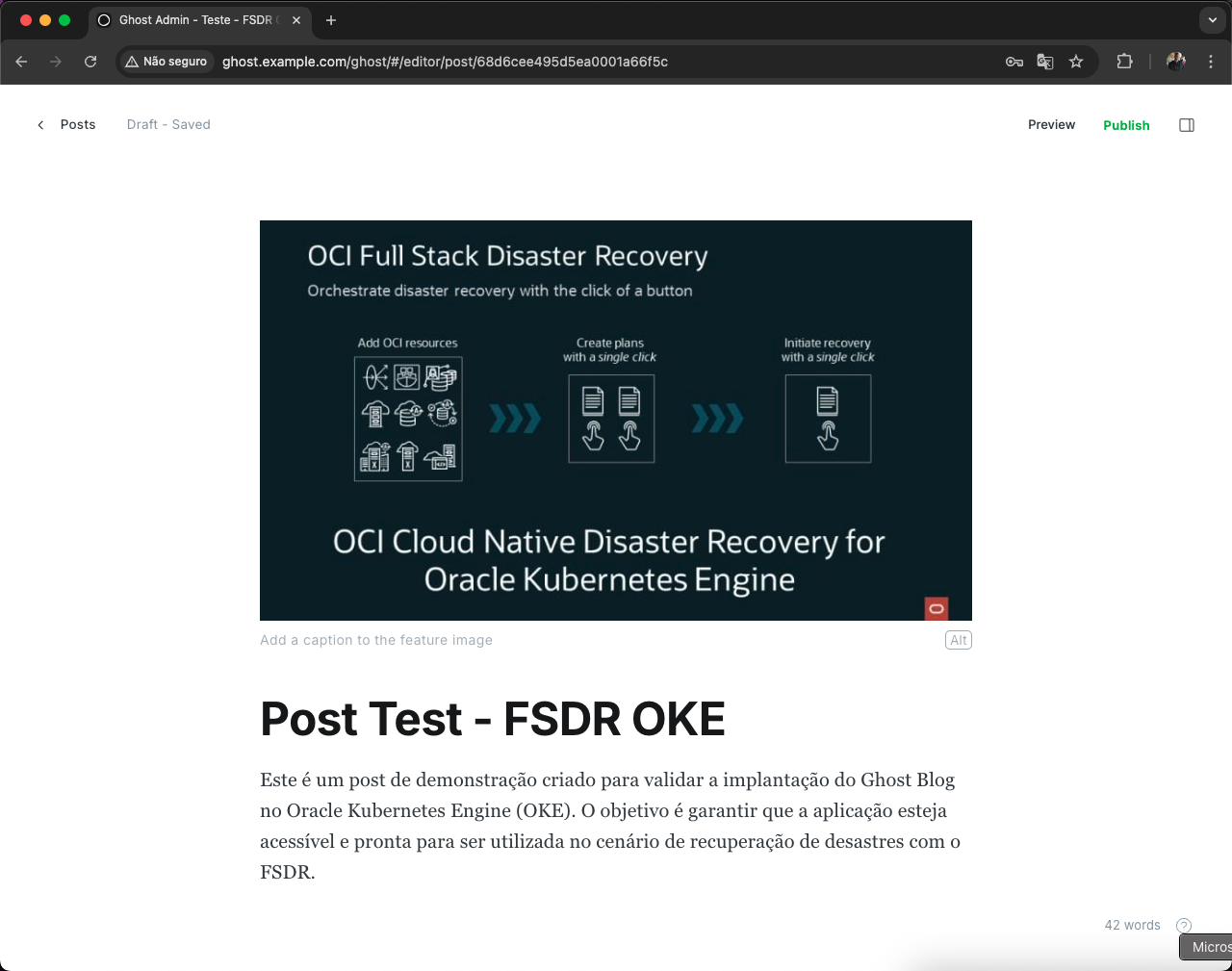
Com a conta criada e o acesso ao painel administrativo liberado, vamos criar um post de teste para validar o funcionamento do Ghost Blog.
No menu lateral do Ghost Blog Admin, clique em Posts e depois em + para adicionar um novo post. Informe um título, adicione algum conteúdo de teste e, em seguida, clique em Publish para publicar o post.
Configurando o OCI Full Stack Disaster Recovery
Nesta etapa vamos configurar o OCI Full Stack Disaster Recovery (FSDR), preparando os planos de proteção que permitirão testar cenários de falha e validar a resiliência da aplicação durante a execução do DR.
Criando Volume Group
O primeiro passo é identificar o Block Volume associado ao Persistent Volume (PV) utilizado pelo Ghost Blog. Em seguida, criaremos um Volume Group contendo esse Block Volume como membro. Esse Volume Group será utilizado pelo FSDR para realizar a replicação de dados entre as regiões.
Para listar o PVC utilizado no namespace do Ghost Blog, execute:
kubectl get pvc -n ghost-ns
![]()
Na Console da OCI, acesse o menu Storage e selecione Volume Groups. Em seguida, clique em Create Volume Group para iniciar a criação.
Basic setup
- Nome: volume-group-pv
- Selecione o compartment
- Selecione availability domain
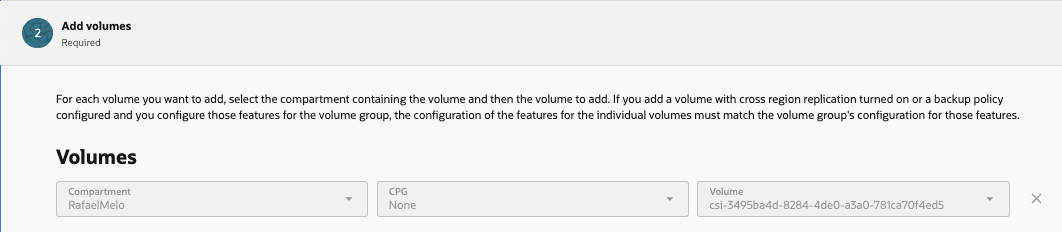
Add Volume
- Selecione o Compartment
- Selecione o Volume
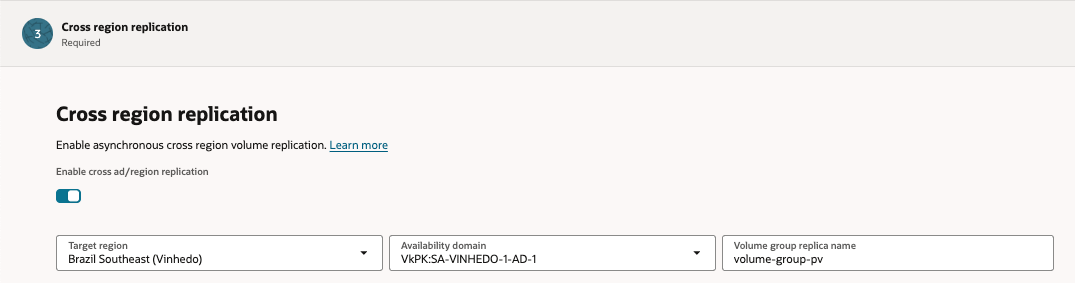
Cross region replication
- Selecione o Compartment
- Selecione o Volume
Prossiga até concluir a criação do Volume Group.
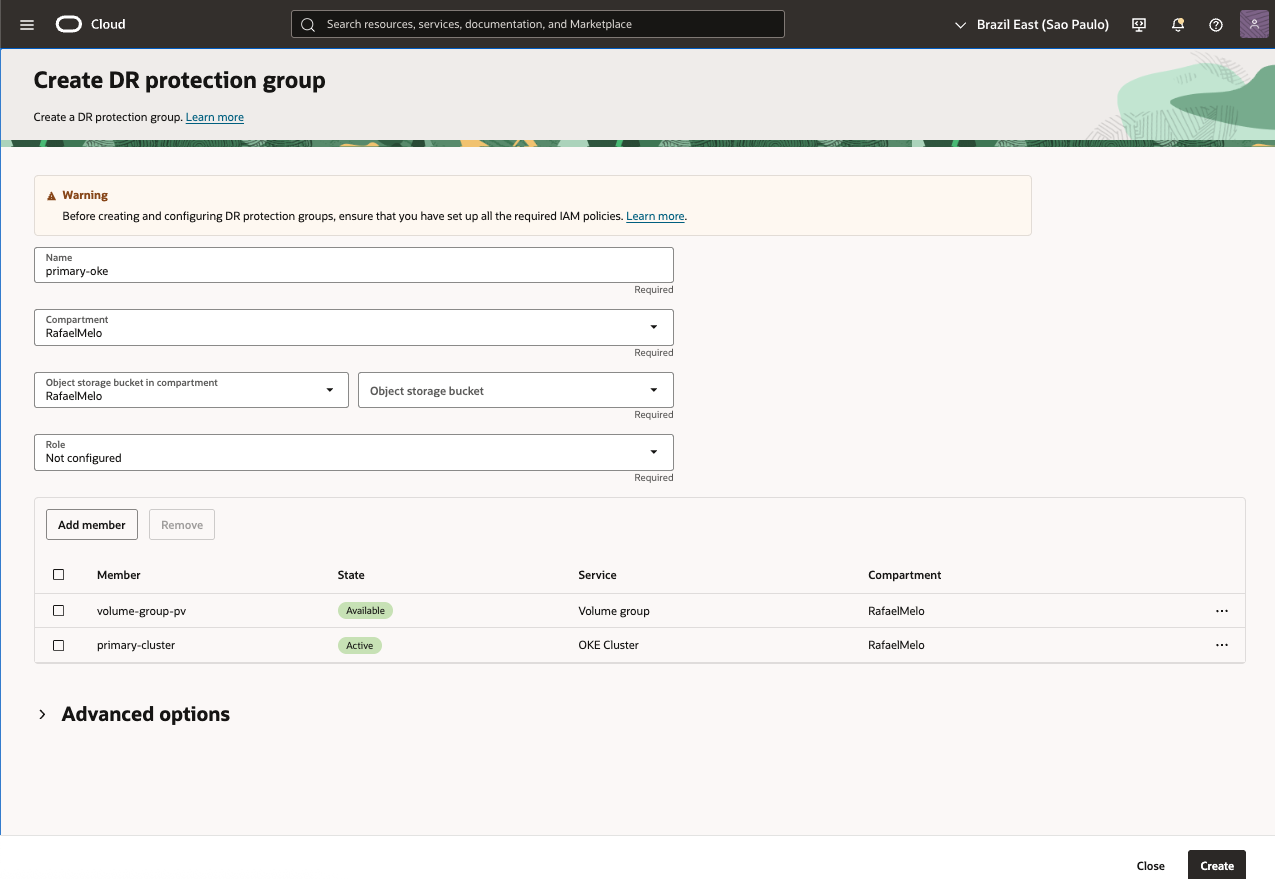
Criando DR Protection Groups Primário
- Nome: primary-oke
- Selecione o compartment para o DR Protection Group
- Object Storage Bucket: primary-bucket
- Role: Not configured (a role será configurada no momento da associação com o DR Protection Group standby)
- Add Members
- Volume Group
- Volume Group compartment: selecione o compartment correspondente
- Volume Group: selecione o Volume Group criado anteriormente
- OKE Cluster
- OKE Cluster compartment: : selecione o compartment correspondente
- OKE Cluster: primary-cluster
- Selecione o compartment e bucket
- The maximum number of backups you want to retain: 2
- Image replication: No
- Namespaces: Include all namespaces
- Volume Group
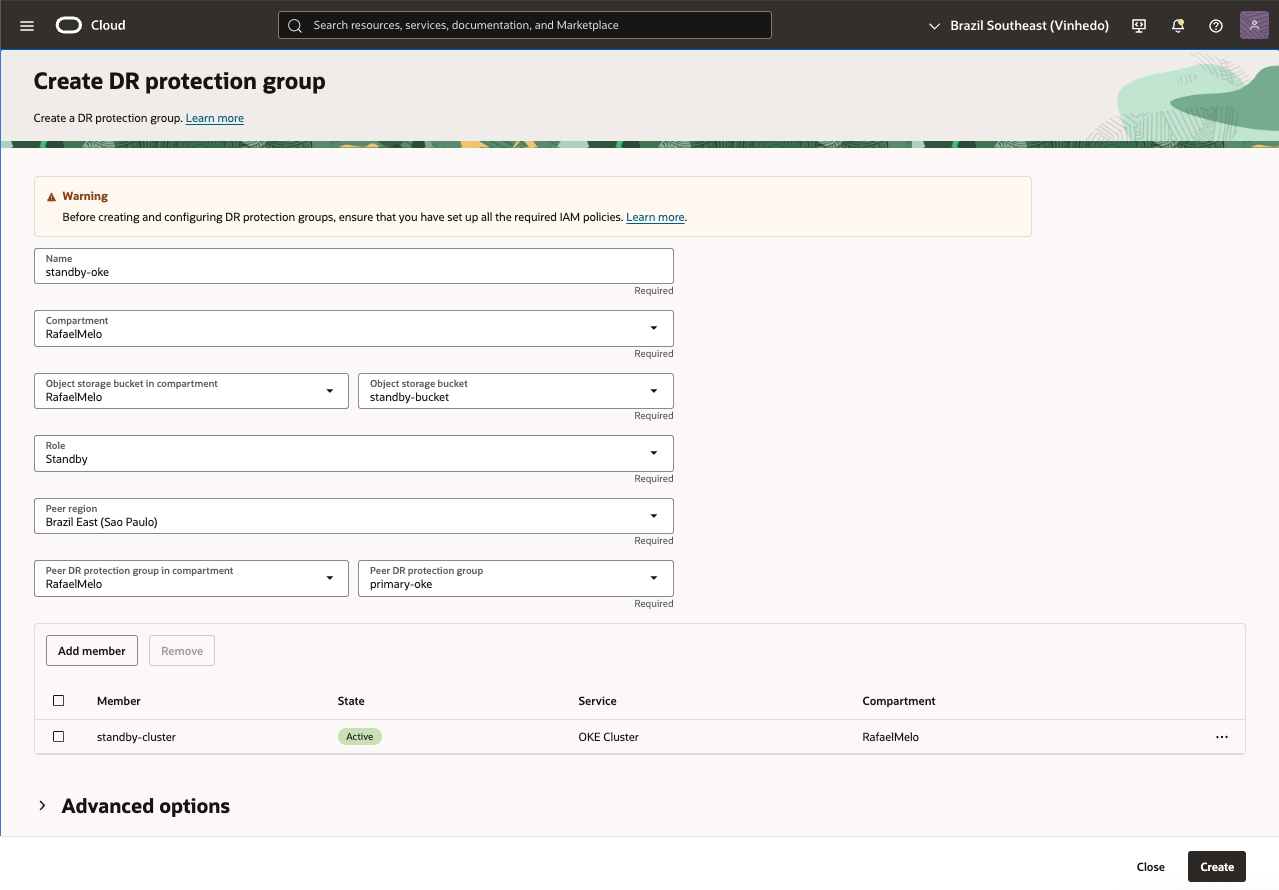
Criando DR Protection Groups Standby
- Nome: standby-oke
- Selecione o compartment para o DR Protection Group
- Object Storage Bucket: standby-bucket
- Role: Standby
- Peer Region: Região do cluster primário
- Peer DR Protection Group: primary-oke
- Add Members
- OKE Cluster
- OKE Cluster compartment: : selecione o compartment correspondente
- OKE Cluster: standby-cluster
- Peer OKE Cluster: primary-cluster
- Selecione o compartment e bucket
- OKE Cluster
Agora que os dois DR Protection Groups estão configurados, já é possível prosseguir com os testes do FSDR para o OKE.
- DR Protection Group Primário

- DR Protection Group Standby

Testando Switchover do OCI Full Stack Disaster Recovery
Com os DR Protection Groups já configurados, podemos avançar para a criação de planos de recuperação e iniciar os testes do FSDR. Essa configuração é realizada na região standby, pois é nela que os recursos serão ativados durante o processo de switchover.
No DR Protection Group da região standby, acesse a aba Plan e crie um novo plano com os seguintes parâmetros:
- Nome: switchover-plan
- Plan Type: switchover (planned)

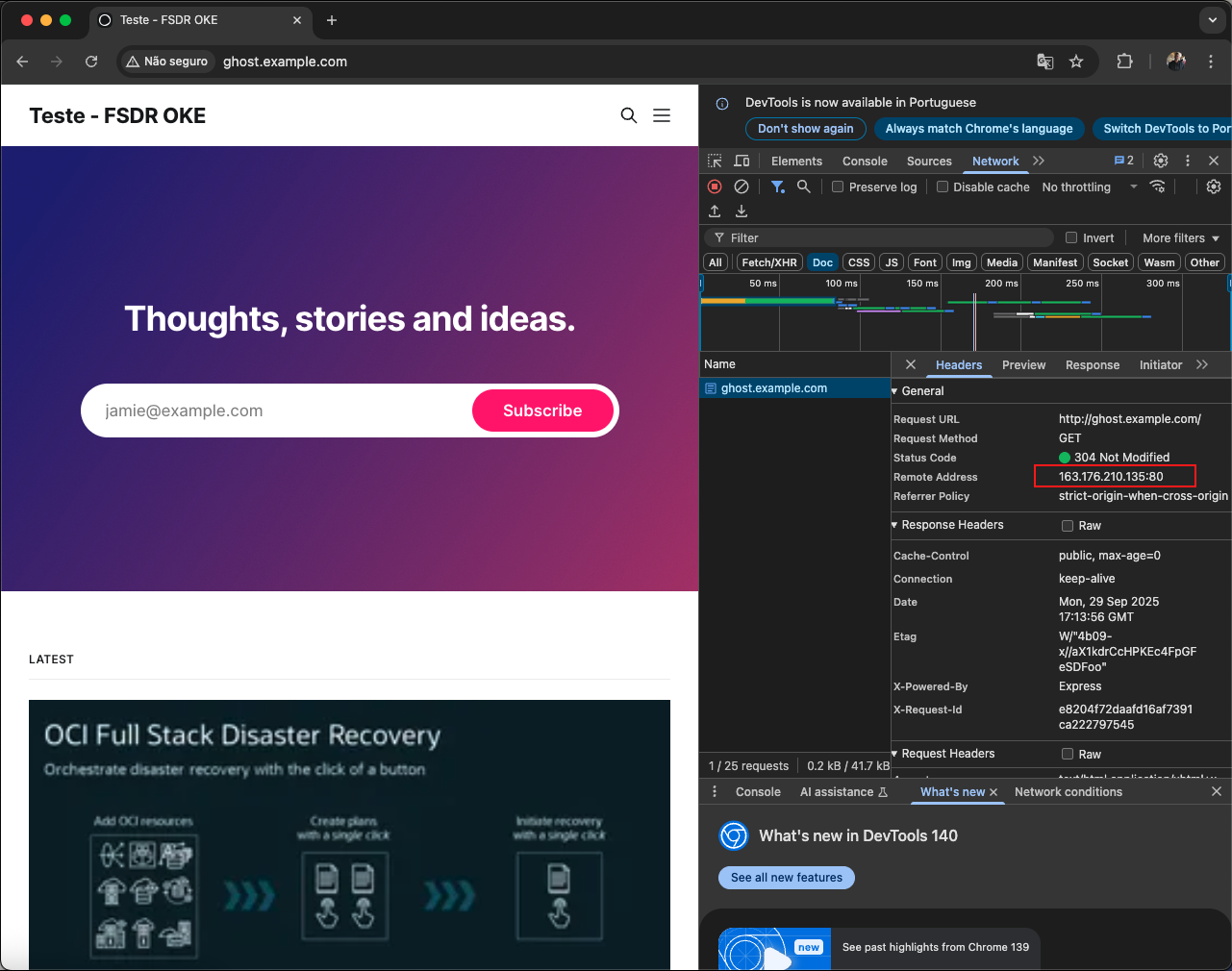
Antes de executar o plano de switchover, é importante validar novamente o acesso ao Ghost Blog no cluster da região primária. Para isso, acesse a URL configurada no arquivo de hosts da sua máquina local: http://ghost.example.com/. Esse endereço está apontando para o IP externo do Load Balancer do Ingress NGINX. Se o site carregar corretamente, significa que o ambiente primário está ativo e pronto para prosseguir com o teste de switchover.
Para reforçar a validação, abra as ferramentas de desenvolvedor do navegador (DevTools → aba Network) e confira o campo Remote Address. Ele deve exibir o IP externo do Load Balancer da região primária, confirmando que o tráfego está sendo roteado corretamente para o cluster primário.
Executando switchover
Na Console da OCI, acesse o DR Protection Group da região standby, selecione o plano switchover-plan recém criado, clique em Actions e escolha a opção Execute plan.
Durante a execução do plano, o FSDR realizará automaticamente as seguintes etapas:
- Ativação dos recursos na região standby, tornando-a a nova região ativa.
- Finalização ordenada dos recursos na região primária (OKE Cluster e Volume Group).
- Habilitação da replicação reversa, de forma que a região primária passe a operar como standby.
Ao finalizar a execução do Switchover, este será o resultado.
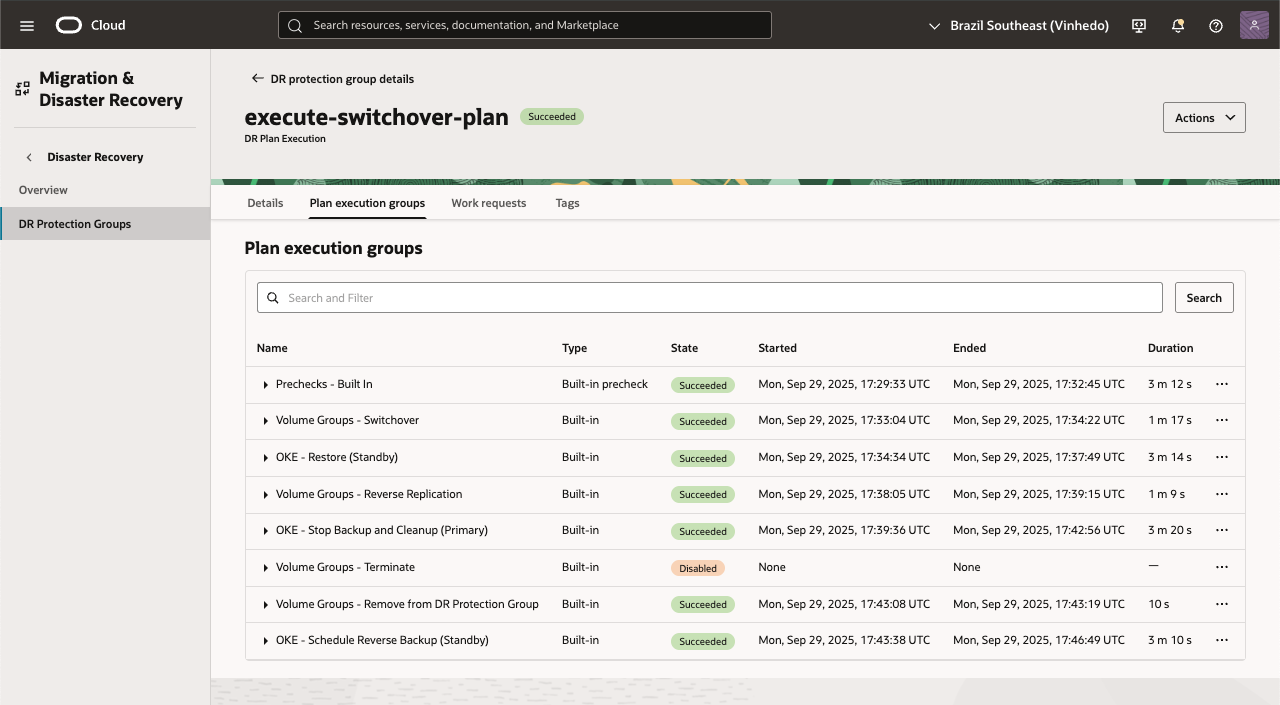
Após a conclusão da execução do plano de Switchover, a tela exibirá o resultado com o status de cada etapa. Neste caso, todas as fases do processo foram concluídas com sucesso, com exceção da etapa Terminate do Volume Group na origem. Essa ação de encerramento definitivo deve ser habilitada apenas em ambientes onde o processo de DR já esteja muito maduro e totalmente validado, pois implica na remoção do recurso original.
Acessando e validando cluster OKE Standby
Agora vamos acessar o cluster OKE standby e verificar se os recursos foram devidamente replicados e iniciados. Para isso, repita os mesmos passos utilizados para acessar o cluster primário descritos na seção Acessando Cluster primário, mas desta vez selecionando o cluster standby.
Observação: no Cloud Shell apenas as VCNs da Home Region ficam disponíveis. Portanto, para alcançar o cluster OKE standby em outra região, será necessário configurar um Remote Peering Connection (RPC) entre as regiões e anexar as duas VCNs, permitindo assim o acesso ao cluster standby. Como criar um RPC.
No cluster OKE standby, valide se os recursos foram devidamente iniciados após o switchover. Primeiro, verifique todos os objetos do namespace do Ghost Blog, incluindo pods, services e PVC:
kubectl get all,pvc -n ghost-ns

Em seguida, confira também o Ingress NGINX, responsável por expor a aplicação externamente:
kubectl get all -n ingress-nginx

Identifique o valor do EXTERNAL-IP do Load Balancer exibido no serviço do Ingress NGINX. Esse será o novo endereço público da aplicação na região standby.
Atualize o host ghost.example.com no arquivo de hosts da sua máquina local para apontar para o novo IP:
- No Linux/macOS: /etc/hosts
- No Windows: C:\Windows\System32\drivers\etc\hosts
<EXTERNAL-IP> ghost.example.com
Validando Ghost Blog
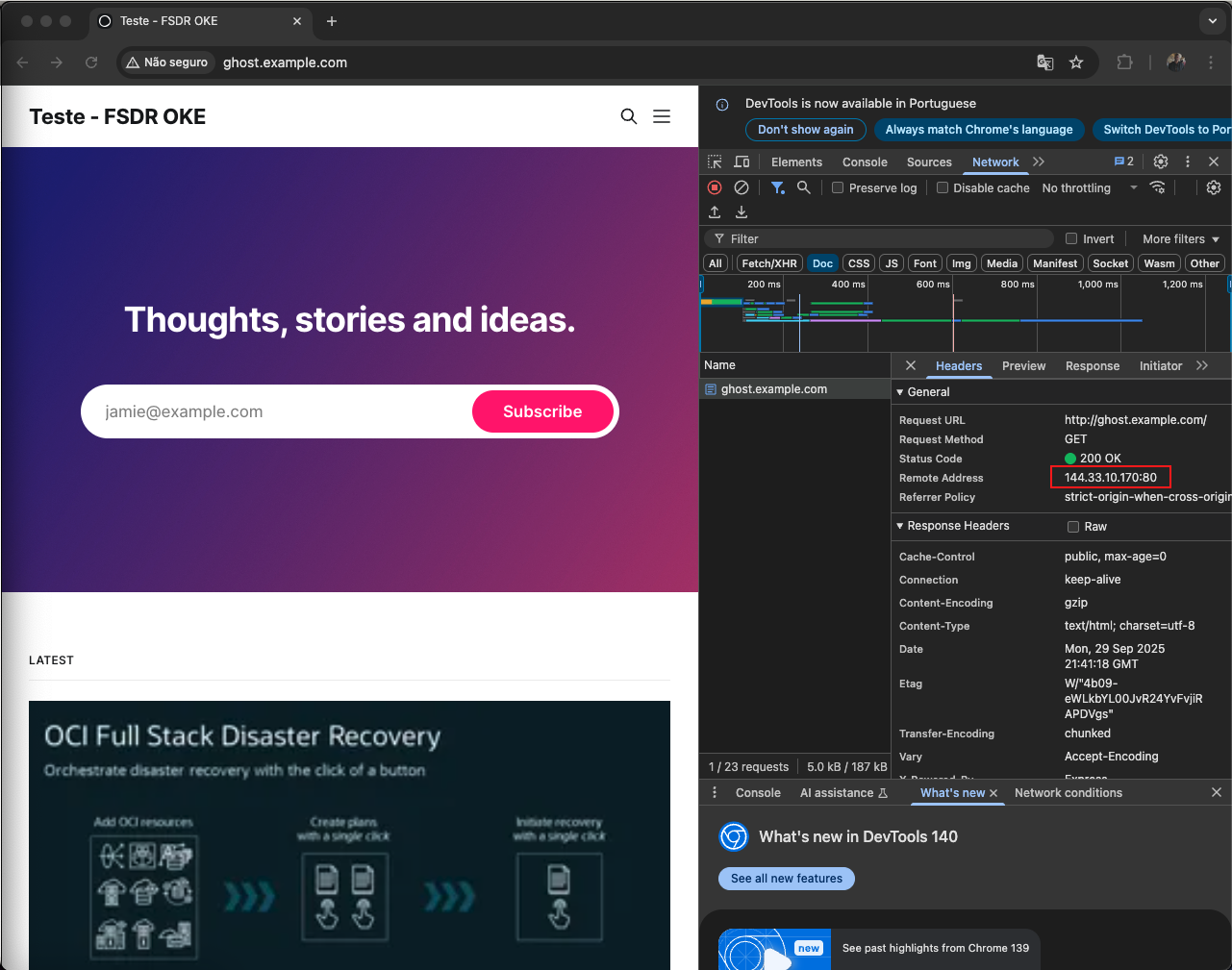
Após atualizar o hosts, acesse novamente o blog em http://ghost.example.com/. Se a página inicial do Ghost Blog for exibida corretamente e o post de teste criado anteriormente também estiver presente, isso comprova que a replicação de dados foi bem-sucedida e que o switchover ocorreu sem perda de informações.
Para confirmar, abra as ferramentas de desenvolvedor do navegador (DevTools > aba Network) e verifique o campo Remote Address. O endereço exibido agora deve corresponder ao EXTERNAL-IP do Load Balancer da região standby, comprovando que o tráfego foi redirecionado com sucesso para o novo ambiente ativo.
Conclusão
Com este hands-on, demonstramos como configurar e executar um plano de Switchover utilizando o OCI Full Stack Disaster Recovery (FSDR) integrado ao Oracle Kubernetes Engine (OKE).
Durante o processo, provisionamos os clusters primário e standby, configuramos buckets e volume groups, implantamos o aplicativo de demonstração Ghost Blog e validamos seu funcionamento antes e depois do switchover. Após a execução do plano, confirmamos que o tráfego passou a ser roteado para a região standby, incluindo o post de teste, o que comprova a replicação bem-sucedida dos dados e a continuidade da aplicação.
Essa abordagem mostra, na prática, como o FSDR possibilita uma recuperação de desastres orquestrada, confiável e alinhada às necessidades de alta disponibilidade e resiliência em ambientes críticos.
