Key Takeaways
- The architectural difference between a chatbot and an AI agent is one pattern: the agent loop. It’s an LLM invoking tools inside an iterative cycle, repeating until the task is complete or a stopping condition is reached.
- A chatbot responds in a single pass. An agent persists, adapts, and acts across multiple steps: perceiving its environment, reasoning over available options, executing an action, and observing the result before deciding what comes next.
- Every major AI company (OpenAI, Anthropic, Google, Microsoft, Meta) has converged on this same core pattern, despite building very different products around it.
- Building agent loops for production requires engineering for two constraints: cost, where agents consume approximately 4x more tokens than standard chat interactions and up to 15x in multi-agent systems, and observability, the ability to trace every reasoning step, tool call, and decision across an iterative execution cycle.
What Is the AI Agent Loop and Why Should You Care?
You have built a chatbot. It works. Users ask a question, it generates a response, and the interaction is complete. Then someone asks it to do something that requires more than one step.
‘Find me the three cheapest flights to Tokyo next month, check if my loyalty points cover any of them, and book the best option’. The chatbot has no mechanism to proceed. It generates a response and stops. It can answer questions about flights. It can explain how loyalty points work. It cannot execute the workflow. The interaction is stateless. Each prompt is processed in isolation, with no persistent context, no access to intermediate results, and no ability to chain decisions across steps.
This is not a limitation of the model. Chat-GPT, Claude, and Gemini are all capable of reasoning through multi-step problems. The limitation is architectural. A chatbot is built to respond. An agent is built to act.
The difference is one while loop.
What is the Agent Loop?
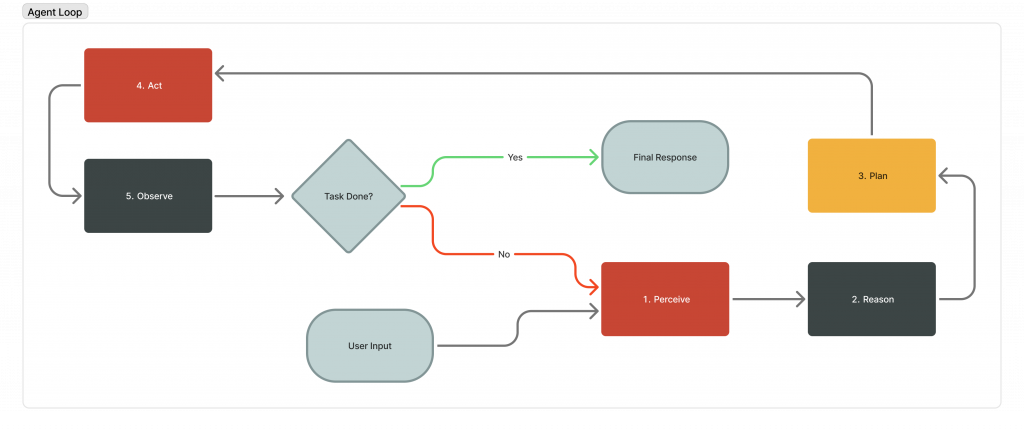
The AI agent loop is the iterative execution cycle at the core of every agentic AI system. At each iteration, the agent assembles context from available inputs, invokes an LLM to reason and select an action, executes that action, observes the outcome, and feeds the observation back into the next iteration. This process repeats until the task is complete or a defined stopping condition is reached.
Across the engineering teams Oracle works with building AI applications, one architectural pattern consistently separates working prototypes from production-grade systems: the agent loop. It’s the architecture that transforms a language model from a text generation system into one that can take actions, adapt to results, and complete multi-step tasks autonomously.
This article examines the agent loop architecture: what it is, how it works, why every major AI company has converged on the same core pattern, and what is required to build one that holds up in production.
All code in this article is available as a runnable companion notebook in the Oracle AI Developer Hub on GitHub. Follow along step by step or execute the full implementation end to end.
Why Single-Pass Responses Hit a Wall
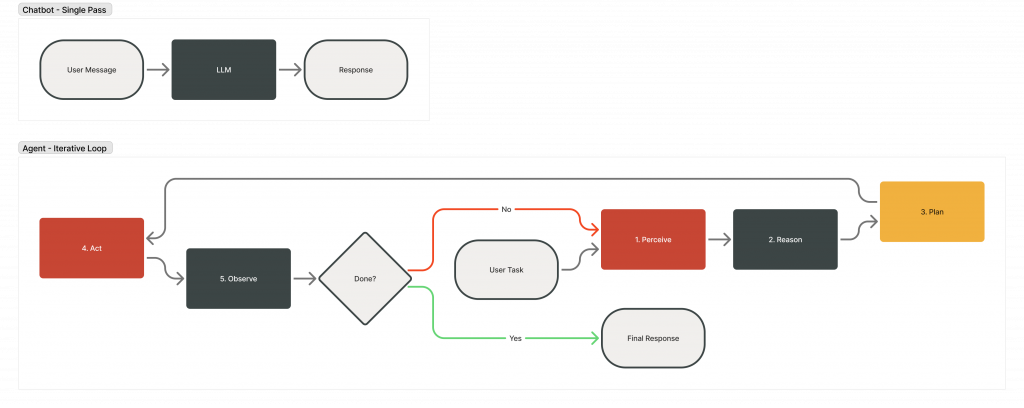
The standard chatbot interaction follows a simple pattern: user sends message, model generates response, done. One input, one output, no state between turns. It works brilliantly for question-answering, summarisation, and creative writing. It falls apart from the moment you need the model to do something in the real world.
A single-pass response has three fundamental constraints:
- It cannot iterate on results. A single-pass system can execute a tool call within a turn, but it has no mechanism to evaluate whether that action succeeded, adapt based on the outcome, or chain a subsequent decision from the result. There is no feedback loop.
- It cannot recover from failure. Without iterative execution, a failed tool call, an empty result set, or an ambiguous API response cannot trigger a revised strategy. The model has no visibility into downstream outcomes.
- It cannot decompose dependent tasks. Real-world workflows require gathering information, making decisions based on that information, executing actions, and handling the consequences of those actions. Each step depends on the result of the previous one. That is a loop, not a straight line.
Russell and Norvig defined an agent back in 1995 as ‘anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators.’ That definition is 30 years old and it still holds. The key word is acting. Not responding. Acting.
The ReAct framework from Princeton and Google Research (Yao et al., 2022) made this practical for LLMs by interleaving reasoning with action in a single prompt-driven loop. The results demonstrated that models perform significantly better when they can reason, act, observe, and reason again: a 34% improvement on ALFWorld and 10% on WebShop. Single-pass responses are not just architecturally limiting. They leave measurable performance on the table.
The Agent Loop: A Mental Model
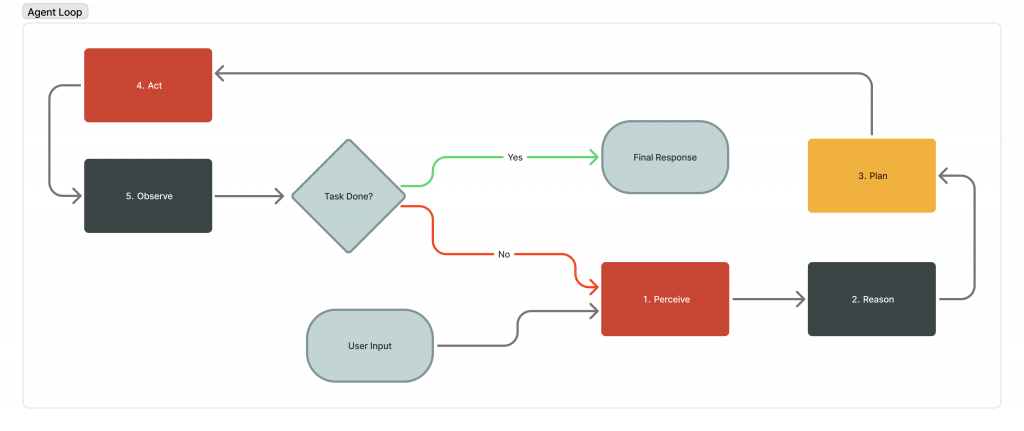
The agent loop operates across five stages that repeat until the task is complete or a stopping condition is met:
- Perceive: The agent receives input. This could be a user message, an API response, an error, or the result of its last action.
- Reason: The LLM processes everything in context and decides what to do next.
- Plan: For complex tasks, the agent decomposes the objective into discrete subtasks before execution. Simpler workflows proceed directly to the Act stage without a dedicated planning step.
- Act: The agent executes something: a tool call, an API request, a database query, a code execution.
- Observe: The agent examines the result. Did it work? Is the task complete? Does the plan need adjusting?
Then, it loops back to step 1.
In pseudocode, the complete pattern reduces to six lines:
while not done:
response = call_llm(messages)
if response has tool_calls:
results = execute_tools(response.tool_calls)
messages.append(results)
else:
done = True
return responseThis execution pattern underpins every autonomous AI system currently in production. It is the foundation on which every major AI organisation has built its agentic architecture. Anthropic’s engineering team describes the pattern directly: ‘Agents can handle sophisticated tasks, but their implementation is often straightforward. They are typically just LLMs using tools based on environmental feedback in a loop.
When the Agent Loop Is Not the Right Architecture
The agent loop is not the appropriate architecture for every use case. Before building an agentic system, validate that the workflow requires iterative execution.
Agent loops are well-suited to tasks where the number of required steps cannot be predicted in advance, where the agent must adapt based on intermediate results, and where the cost of latency is acceptable relative to the value of task completion.
Workflows that follow a fixed, predictable sequence of steps are better served by deterministic pipelines. Single-step tasks that require one LLM call and one tool invocation do not benefit from the overhead of an agent loop. Tasks where latency is the primary constraint should be evaluated carefully, as each loop iteration adds LLM call latency.
The principle from both OpenAI and Anthropic’s published guidance is consistent: start with the simplest architecture that solves the problem. Introduce the agent loop only when iterative reasoning and adaptive tool use are required.
How Every Major AI Company Converged on the Same Architecture
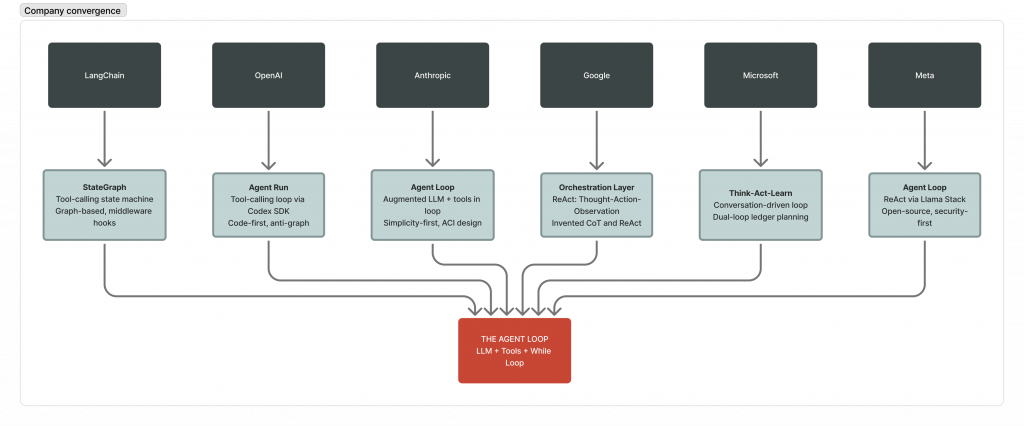
Despite differences in SDK design, nomenclature, and architectural philosophy, every major AI organisation has converged on the same underlying execution pattern. The table below maps each implementation against the five stages of the core loop:
| Company | What they call it | Core pattern | Key contribution |
| OpenAI | Agent Loop | Tool-calling loop via Codex SDK | Code-first approach; anti-declarative-graph philosophy |
| Anthropic | Agent loop | Augmented LLM + tools in loop | Simplicity-first design; workflows vs. agents distinction |
| Orchestration layer | ReAct (Thought-Action-Observation) | Invented Chain-of-Thought and co-created ReAct | |
| Microsoft | Think-Act-Learn | Conversation-driven loop | Dual-loop ledger planning (Magentic-One) |
| Meta | Agent loop | ReAct via Llama Stack | Open-source building blocks; security-first (‘Rule of Two’) |
| LangChain | Agent executor / StateGraph | Tool-calling state machine | Graph-based orchestration; middleware hooks for control |
The implementations differ in naming conventions, SDK design, and architectural philosophy. The execution pattern is identical.
Lilian Weng’s formula captures it simply: Agent = LLM + Memory + Planning + Tool Use. The agent loop is the runtime that ties those four components together.
How the Agent Loop Actually Works
The canonical pattern is ReAct: reasoning interleaved with acting. The model does not simply select a tool. It reasons about why that tool is appropriate, executes the call, processes the result, and reasons again.
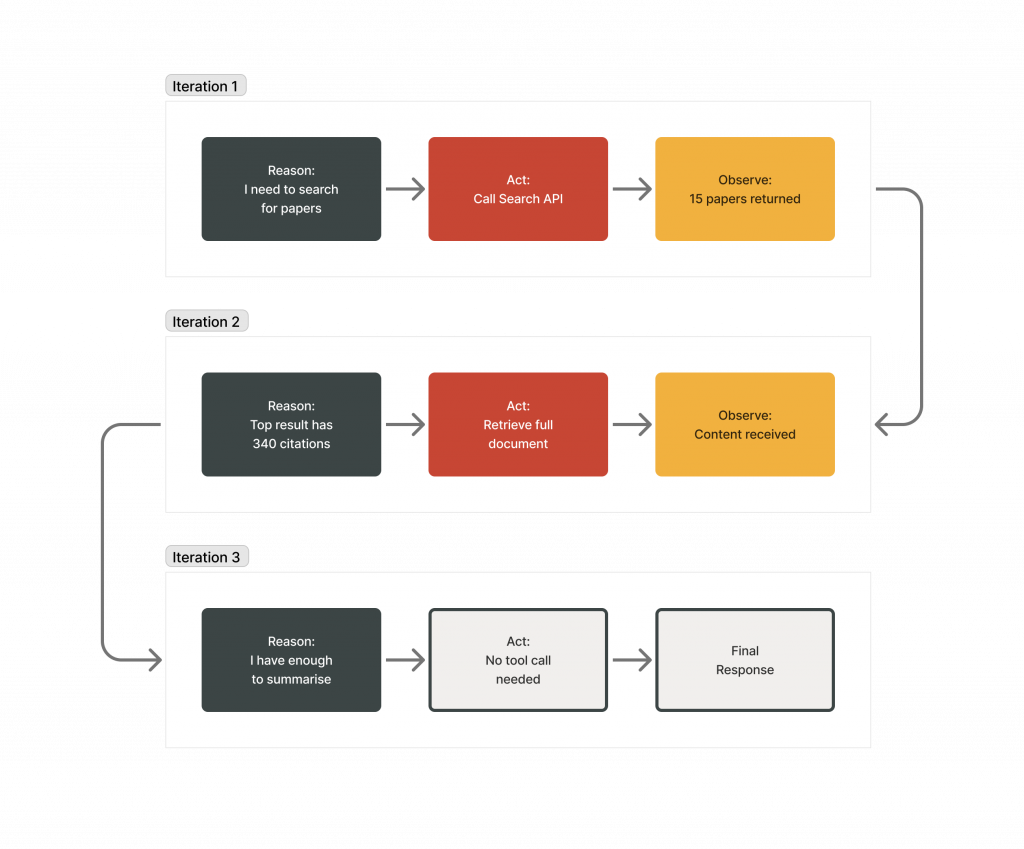
To illustrate how the loop executes in practice, consider the following task: identify the most cited paper on agent memory published in 2026 and summarise its key findings.
Iteration 1 (Reason → Act → Observe):
The agent reasons that it needs to search for papers on agent memory from 2026 and selects the search tool. It calls the search API with relevant keywords. The result returns 15 papers with citation counts.
Iteration 2:
The agent identifies the top result with 340 citations and calls a document retrieval tool to access the full abstract and key sections.
Iteration 3:
The agent determines that sufficient information has been gathered, generates the summary, and exits the loop.
Three iterations. Three tool calls. One complete answer that no single-pass chatbot could have produced.
Tool integration: the universal pattern
Across every provider, tool integration follows the same structure. Tools are defined with a name, description, and JSON Schema parameters. The model decides whether to call a tool and with what arguments. The system executes the function and returns results as a tool message. The model processes results and decides whether to continue looping or return a final response.
Tools in an agent loop can be classified into three categories. Data tools retrieve context, such as database queries, vector search, or document retrieval. Action tools perform operations with side effects, such as writing records, calling external APIs, or executing code. Orchestration tools invoke other agents as callable sub-modules, enabling multi-agent coordination within a single workflow. Clear classification of tools at design time reduces ambiguous model behaviour at runtime.
Anthropic’s Model Context Protocol (MCP) has emerged as a leading open standard for how agents discover and connect to external tools, with adoption across OpenAI, Google, Microsoft, and the broader ecosystem.
Beyond the basic loop
The core ReAct loop handles most use cases, but the pattern extends in two important directions.
Plan-and-execute separates planning from execution. Instead of invoking the LLM at every step, a planner generates a full task breakdown upfront, an executor works through each subtask, and a re-planner adjusts when execution diverges from the plan. LangChain’s LLMCompiler implementation streams a directed acyclic graph of tasks with explicit dependency tracking, enabling parallel execution. The original paper (Kim et al., ICML 2024) reports a 3.6x speedup over sequential ReAct-style execution. At production scale, where each LLM call carries a direct cost, the architectural decision to plan upfront rather than reason at every step has measurable financial implications.
Multi-agent orchestration distributes work across specialised agents. Anthropic’s Claude Research system uses an orchestrator-worker pattern where a lead agent spawns sub-agents to explore different threads in parallel. Their multi-agent system outperformed a single-agent setup by 90.2% on internal research evaluations. Microsoft’s Magentic-One takes it further with a dual-loop system: an outer loop for strategic planning and an inner loop for step-by-step execution, with the ability to reset the entire strategy when progress stalls.
These are powerful extensions, but the advice from every company is the same: start with the simplest loop that works. Only add complexity when you can measure the improvement.
The Enterprise Reality: Cost and Observability
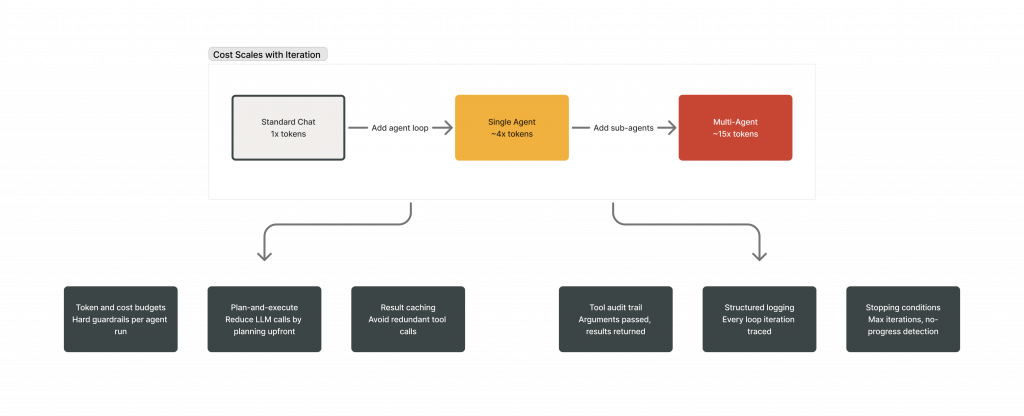
Agent loops that perform well in controlled environments frequently expose new failure modes at production scale. The two constraints that dominate enterprise deployments are cost and observability.
Cost scales with iteration
Every loop iteration is an LLM call. Anthropic’s internal data shows that agents consume roughly 4x more tokens than standard chat. Multi-agent systems push that to approximately 15x. At thousands of agent sessions per day, token costs compound with every loop iteration. Without cost controls embedded at the architecture level, this becomes a significant operational constraint.
The mitigation strategies are architectural. Plan-and-execute patterns reduce the number of LLM calls by planning upfront rather than reasoning at every step. Caching commonly retrieved tool results avoids redundant work. Setting token and cost budgets per agent run prevents runaway spending. These controls must be designed into the system from the start, not added retroactively.
Observability: knowing what your agent did and why
A standard chat interaction produces a single response from a single LLM call. An agent running 15 iterations, calling 8 different tools, and branching across multiple reasoning paths produces a complex execution trace. When a failure occurs, diagnosing it requires structured visibility into every stage of that trace: what the model reasoned, which tool it invoked, what arguments it passed, what the result was, and how the model interpreted that result before the next iteration.
Production agent systems need structured logging at every stage of the loop: what the model reasoned, which tool it called, what arguments it passed, what came back, and how it interpreted the result. Microsoft’s AutoGen 0.4 builds on OpenTelemetry for this. LangChain’s middleware hooks (before_model, after_model, modify_model_request) let you intercept and inspect every iteration.
Stopping conditions are the other critical piece. Without them, agents can loop indefinitely, burning tokens and producing increasingly incoherent results. Every production system needs maximum iteration limits, no-progress detection (exiting when repeated iterations produce no new information), and token/cost budgets as hard guardrails.
The following scenario illustrates the consequence of deploying an agent loop without hard stopping conditions:
An agent is deployed to scrape a website and summarise the data. The target website updates its structure, causing the scraping tool to return an empty result. The agent lacks a hard stopping condition, and its prompt instructs it to retry until data is retrieved. It enters a runaway loop, calling the broken tool 400 times in five minutes and consuming thousands of tokens before hitting a platform rate limit. A maximum iteration limit of three cycles would have prevented the failure entirely.
Building an Agent Loop with LangChain and Oracle
Before selecting a framework or writing code, address the following implementation requirements. These apply regardless of which orchestration library is used:
- Identify tools and schema: What actions can the agent take, and what exact parameters do those tools need?
- Choose state representation: How will you store the conversation history and intermediate tool results?
- Define stopping criteria: What are the hard limits (iterations, tokens, budget) that will force the loop to terminate?
- Establish logging and telemetry: How will you track each reasoning step, tool call, and result?
- Select a memory layer: Where will you store persistent knowledge (like vector embeddings or user preferences) across sessions?
Here is one concrete way to implement that checklist using LangChain and Oracle.
import oracledb
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_core.messages import AIMessage, ToolMessage
# Connect to Oracle AI Database
pool = oracledb.create_pool(
user="agent_user", password="password",
dsn="hostname:port/service",
min=2, max=10, increment=1,
)
# Define tools the agent can use
@tool
def calculate(expression: str) -> str:
"""Evaluate a mathematical expression and return the numeric result."""
...
@tool
def convert_units(value: float, from_unit: str, to_unit: str) -> str:
"""Convert a numeric value from one unit to another."""
...
@tool
def timezone_convert(time_str: str, from_city: str, to_city: str) -> str:
"""Convert a local time from one city's timezone to another."""
...
# Create the agent -- returns a compiled StateGraph that runs the loop
agent = create_agent(
model=llm,
tools=[calculate, convert_units, timezone_convert],
system_prompt="You are a precise reasoning assistant. Use tools for all calculations.",
)
QUESTION = (
"A flight from London to New York JFK covers 5,570 km. "
"The aircraft cruises at 900 km/h. "
"The flight departs London at 14:00 local time. "
"How long is the flight in hours and minutes, "
"and what local time does it arrive in New York?"
)
# Stream the loop live -- each chunk shows one stage of the agent's reasoning
for chunk in agent.stream(
{"messages": [("human", QUESTION)]},
stream_mode="values",
):
last_msg = chunk["messages"][-1]
if isinstance(last_msg, AIMessage) and last_msg.tool_calls:
for call in last_msg.tool_calls:
print(f"[ACT] \\u2192 {call['name']}({call['args']})")
elif isinstance(last_msg, ToolMessage):
print(f"[OBSERVE] \\u2190 {last_msg.content}")
elif isinstance(last_msg, AIMessage) and last_msg.content:
print(f"\\nAnswer: {last_msg.content}")The implementation above is a working agent loop. The compiled agent graph manages the while loop internally, invoking the LLM, evaluating tool calls, executing them, appending results to the message state, and repeating until the model returns a final response without further tool calls or the recursion limit is reached.
Oracle AI Database provides the storage backend for the tools the agent calls. Vector search for semantic retrieval, relational tables for structured data, and ACID transactions ensuring that every tool call either fully succeeds or fully rolls back. No partial state. No corrupted memory.
We’ve published a complete, runnable notebook that implements a full agent loop architecture with LangChain and Oracle AI Database in the Oracle AI Developer Hub.
Run the notebook → oracle-devrel/oracle-ai-developer-hub
Where This Is Heading
Three structural shifts are emerging in how production agent systems are designed and operated.
The core loop architecture is stable. The active area of development is the infrastructure built around it: context management, multi-loop coordination, and decision auditability. The while loop itself is not changing. What is evolving is how context is managed within it, how multiple loops are coordinated together, and how the loop’s decisions are made auditable and controllable.
Agent middleware is emerging as the standard abstraction layer for production systems. LangChain’s recent work on middleware hooks (intercepting the loop at before_model, after_model, and modify_model_request) suggests a future where developers don’t modify the loop itself but layer behaviour on top of it: summarisation, PII redaction, human-in-the-loop approval, dynamic model switching. It’s the same pattern that made web frameworks powerful: don’t change the request-response cycle, add middleware to it.
Cost-per-task will replace cost-per-token as the primary efficiency metric. Token usage is an input measure. The metric that reflects actual business value is the total cost required to complete a task end to end, including LLM calls, tool executions, and any human escalations triggered by agent failures.
An agent that consumes 15x more tokens but resolves a customer issue without human escalation is cheaper than a chatbot that consumes fewer tokens but requires human intervention to complete the task.
The primary open question in production agent deployment is the pace at which observability tooling will mature. Debugging a 20-iteration agent run currently requires piecing together structured logs, tool call traces, and LLM reasoning outputs across multiple systems. The industry needs better tooling for tracing, replaying, and interpreting agent decisions. The building blocks exist in OpenTelemetry, structured logging, and middleware hooks. The developer experience remains the unsolved problem.
The agent loop is the foundational pattern for any AI system that needs to do more than generate a response. It is the architectural starting point for production-grade autonomous AI.
Frequently Asked Questions
What is an AI agent loop?
The AI agent loop is an iterative architecture where a large language model repeatedly reasons about a task, takes an action (typically a tool call), observes the result, and decides what to do next. The cycle continues until the task is complete or a stopping condition is met. In its simplest form, it’s an LLM calling tools inside a while loop. This pattern, formalised in the ReAct framework (2022), is the core architecture behind every major autonomous AI system shipping today.
What is the architectural difference between an AI agent and a chatbot?
A chatbot generates a single response to a single input. It answers questions but cannot execute multi-step actions or adapt based on intermediate results. An AI agent uses the agent loop to iteratively reason, act, and observe, handling complex tasks that require multiple steps, tool interactions, and course corrections. The architectural difference is simple: a chatbot is one LLM call; an agent is an LLM calling tools in a loop until the job is done.
How does the ReAct framework work?
ReAct (Reasoning + Acting) interleaves reasoning traces with tool actions in a prompt-driven loop. At each step, the model generates a ‘thought’ explaining its reasoning, takes an ‘action’ by calling a tool, and receives an ‘observation’ with the result. This cycle repeats until the task is complete. The key innovation is that reasoning and acting reinforce each other: the model reasons about what to do (reason to act) and uses action results to inform further reasoning (act to reason).
What are common patterns for multi-agent orchestration?
Three patterns dominate. The manager pattern uses a central agent that delegates subtasks to specialised sub-agents via tool calls (used by OpenAI’s Agents SDK). The orchestrator-worker pattern has a lead agent spawning workers for parallel exploration (used by Anthropic’s Claude Research). The handoff pattern treats agents as peers that transfer control to one another based on specialisation. Most production systems start with a single agent loop and only move to multi-agent orchestration when task complexity genuinely demands it.
How do you prevent an AI agent from running forever?
Production agent loops use multiple stopping conditions layered together. Maximum iteration limits cap the number of loop cycles (for example, max_iterations=10). Token and cost budgets set hard spending limits per agent run. No-progress detection exits the loop when repeated iterations produce no new information. Goal-achievement checks evaluate whether the task objective has been met. Microsoft’s Magentic-One adds a dual-loop approach where the outer loop can reset the entire strategy when the inner loop stalls, preventing the agent from spinning on a failed approach.
