A practical guide to building episodic, lexical, vector, and graph memory workflows in Oracle AI Database
Companion notebook: Unified Agent Memory with Oracle AI Database
Key Takeaways
- A unified memory core combines episodic, lexical, semantic, and relationship-aware retrieval in one governed platform.
- Hybrid retrieval (Oracle Text + vector + metadata filters) improves reliability in enterprise queries.
GRAPH_TABLEadds business relationship context beyond nearest-neighbor similarity.DBMS_SCHEDULERand VPD patterns make memory lifecycle and security operational.- The companion notebook demonstrates all core patterns in a runnable workflow.
What Agent Memory is and Why it Matters
Agent memory is the stored context an AI system can access across steps, sessions, or workflows. In practice, it supports several critical functions:
- State persistence – remembering what the agent is currently doing
- Context continuity – carrying forward prior user goals and constraints
- Knowledge retrieval – finding facts, documents, and learned abstractions
- Workflow resilience – resuming long-running tasks after delays or failures
- Personalization – adapting behavior based on historical interactions
This matters because modern agents are not just answering isolated questions. They are coordinating tools, operating over enterprise systems, and producing outputs that depend on both immediate context and historical knowledge.
At a high level, memory is what allows an agent to behave less like a stateless API and more like a system that can learn and adapt over time.
What You’ll Learn
- Modeling episodic memory with JSON and SQL/JSON
- Running lexical and semantic retrieval with Oracle Text and vectors
- Combining lexical, semantic, and metadata constraints into hybrid retrieval.
- Traversing user-ticket-document context with SQL Property Graph and
GRAPH_TABLE. - Applying lifecycle and tenant-aware security patterns for governed agent memory.
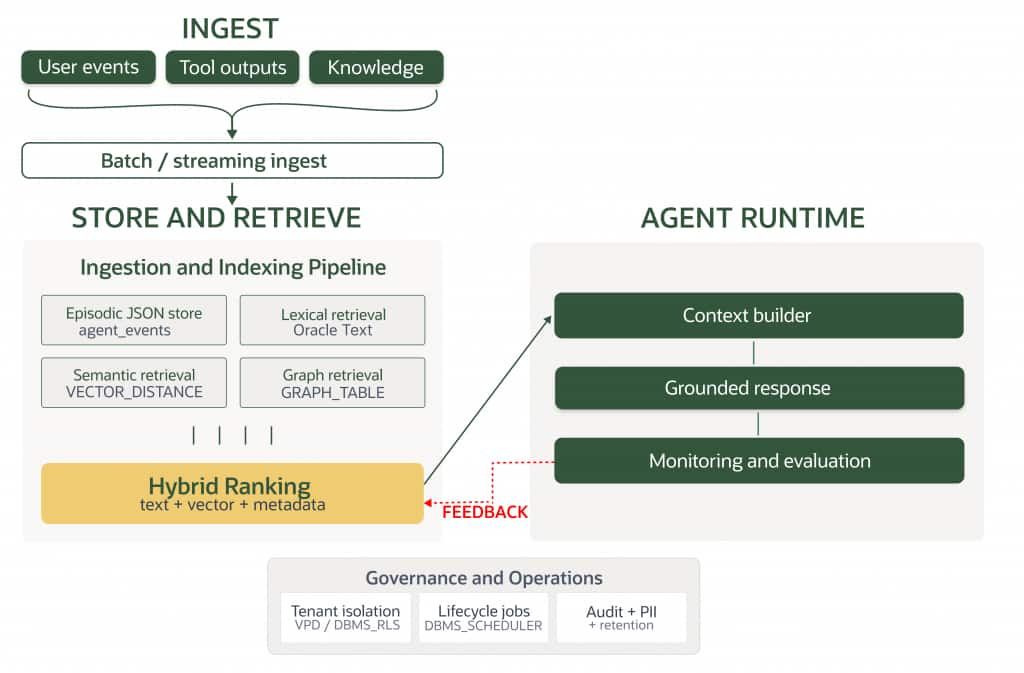
Architecture Overview
The unified memory flow keeps ingestion, storage, retrieval, and governance inside Oracle AI Database. Episodic events are stored in JSON, reusable knowledge is retrieved with Oracle Text and vectors, relationship context is traversed with SQL Property Graph, and lifecycle/security controls are enforced with scheduler and VPD patterns.
Prerequisites
- Python 3.10+
- Oracle AI Database 26ai (or compatible environment)
- Dependencies:
oracledb,python-dotenv,pandas, optionallangchain-core - Privileges for tables, indexes, SQL/JSON, and queries
- Optional privileges for Oracle Text and SQL Property Graph features
Types of Agent Memory
Not all memory behaves the same way. Different memory types have different latency, durability, and retrieval requirements.
Short-Term vs. Long-Term Memory
Short-term memory is the agent’s working context. It typically includes the current conversation window, recent tool outputs, temporary plans, and session variables. It requires very low latency but does not need to be persisted indefinitely.
Long-term memory persists beyond a single interaction. It may include user preferences, completed tasks, conversation summaries, business objects, knowledge artifacts, and execution history. It should be durable, searchable, and governed.
Episodic Memory
Episodic memory stores events and experiences. For agents, that can mean:
- previous conversations
- tool calls and outputs
- actions taken on behalf of a user
- workflow checkpoints
- timestamps, actors, and outcome metadata
This memory is usually time-oriented and benefits from structured metadata, durable storage, and filtering by user, task, tenant, or date range.
Example: episodic memory as JSON documents
A practical pattern is to store each conversation turn, tool invocation, or workflow checkpoint as a JSON document and query it with SQL/JSON functions:
CREATE TABLE agent_events (
event_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
session_id VARCHAR2(100) NOT NULL,
event_data JSON NOT NULL,
created_at TIMESTAMP DEFAULT SYSTIMESTAMP
);
SELECT e.session_id,
JSON_VALUE(e.event_data, '$.type') AS event_type,
jt.tool_name,
jt.latency_ms
FROM agent_events e,
JSON_TABLE(e.event_data, '$'
COLUMNS (
tool_name VARCHAR2(100) PATH '$.tool.name',
latency_ms NUMBER PATH '$.tool.latencyMs'
)
) jt
WHERE JSON_VALUE(e.event_data, '$.type') = 'tool_call';
This pattern is especially useful when an agent needs durable session history without flattening every attribute into separate columns on day one.
Semantic Memory
Semantic memory stores generalized knowledge rather than a raw event log. It includes facts, policies, product information, documentation, ontologies, embeddings, and derived knowledge the agent can reuse across tasks.
This memory often benefits from a combination of:
- vector search for semantic similarity
- keyword/text search for exact terminology and domain-specific phrases
- relational filters for governance, freshness, and access constraints
- graph relationships for connected business meaning
Example: semantic retrieval with Oracle Text
Why does lexical retrieval still matter in a vector-first architecture? An agent can use CONTAINS to rank policy, support, or product documents by relevance and combine that with vector search in the surrounding workflow:
SELECT article_id,
title,
SCORE(1) AS relevance
FROM knowledge_articles
WHERE CONTAINS(content, 'database performance', 1) > 0
ORDER BY relevance DESC
FETCH FIRST 10 ROWS ONLY;
For short text catalogs, Oracle Text‘s CTXCAT model is also a strong fit when agents need keyword matching plus structured filters such as product family, severity, or tenant.
Matching Memory Types to Storage Technologies
| Memory Type | Typical Contents | Key Requirements | Storage Options |
| Short-term/working | Current dialog, temporary tool outputs, scratch state | Millisecond access, session scope, easy overwrite | In-memory cache, session store, relational/JSON state tables |
| Long-term | Durable use context, workflow state, preferences | Persistence, consistency, auditability, access control | Relational database, JSON documents, key-value stores |
| Episodic | Conversations, actions, events, logs | Time-based queries, metadata filtering, retention rules | Relational + JSON, event tables, object storage for large artifacts |
| Semantic | Documents, facts, embeddings, concepts | Similarity retrieval, hybrid search, freshness controls | Vector indexes, text search, graph + relational metadata |
The key design principle is simple: use multiple memory types, but avoid fragmenting them across too many disconnected systems unless you truly need to.
Storage Technologies for Agent Memory
In-Memory Storage: Pros, Cons, and Use Cases
This type of storage is well suited for fast, transient state.
Pros
- extremely low latency
- simple fit for session state and active workflow context
- useful for intermediate reasoning artifacts and recent tool results
Cons
- limited durability
- not suitable as the system of record
- difficult to govern and audit if used alone
Best use cases
- active conversation buffers
- current plan state for an orchestrator
- short-lived coordination across steps in a single run
File-Based Storage: When and Why to Use it
Files and object storage are useful for large, unstructured artifacts such as:
- PDFs and reports
- images and media
- transcript archives
- exported workflow bundles
They work well when the artifact itself is large, rarely updated, or naturally belongs in a document repository. However, file-based storage alone is a weak memory layer because it lacks rich query semantics. In practice, it works best when paired with database metadata, vector indexes, or a catalog layer.
Databases: SQL, NoSQL, and Key-Value Stores
Databases are the backbone of durable agent memory.
- SQL databases excel when agents need strong consistency, joins, transactions, governance, and structured filters.
- NoSQL/document stores are useful when schemas evolve quickly and payloads are semi-structured.
- Key-value stores are effective for simple lookups, caching, and session persistence at high speed.
For enterprise agents, the strongest pattern is often not choosing one memory store per memory type, but choosing a platform that can support multiple memory representations together.
Vector Databases for Semantic Memory Retrieval
Vector retrieval is essential when an agent must find content by meaning rather than exact wording. It is especially effective for:
- semantic search over documents
- similarity matching for prior cases
- memory recall from summarized or embedded interactions
- grounding RAG workflows with relevant context
But vector search should not be treated as the entire memory architecture. Enterprise retrieval often requires semantic matching plus exact filtering, freshness rules, tenant boundaries, business keys, and joins to live data.
That is where Oracle AI Database stands out as a unified memory core. It brings vector search next to relational data, JSON, graph, spatial, and enterprise governance features, allowing agents to retrieve semantically relevant context without losing operational control.
Why Text Search Belongs in the Unified Memory Core
A significant portion of production searches need both vector similarity and keyword matching. Users do not always ask only by meaning. They often include:
- exact product names
- policy clauses
- ticket IDs
- account numbers
- legal terms
- error messages and codes
That is why a mature memory core should include text search alongside vector, graph, spatial, JSON, and relational capabilities. Semantic retrieval helps with meaning; keyword retrieval helps with precision. Together they produce more reliable enterprise context.
Hybrid Storage Architectures and Patterns
Most serious agent systems use a hybrid pattern, such as:
- in-memory working context for active sessions
- relational/JSON persistence for durable state and episodic history
- vector indexes for semantic recall
- text search for lexical precision
- object storage for large source artifacts
- graph structures where relationships are central to reasoning
The question is not whether hybrid memory exists—it almost always does. The real design decision is whether those layers are operationally fragmented or organized around a unified platform.
Example: relationship-aware memory with SQL Property Graph
Oracle SQL Property Graph lets you model and query graph data — vertices (nodes) and edges (relationships) — directly on top of existing relational tables, views, materialized views, or external tables. No data is copied; the graph definition stores only metadata, and queries operate against current table data. This is useful when an agent must follow connected context such as user → ticket → service → document:
SELECT *
FROM GRAPH_TABLE (memory_graph
MATCH (u IS user) -[r IS opened]-> (t IS ticket) -[m IS mentions]-> (d IS document)
COLUMNS (
u.name AS user_name,
t.title AS ticket_title,
d.title AS document_title
)
);
That kind of retrieval complements vector similarity by surfacing the business relationships around a memory item, not just the nearest semantic neighbors.
Scaling Agent Memory for Large Applications
Externalizing Memory from Models
Large language models should not be expected to carry all relevant context in their parameters or prompt window. As applications grow, memory must be externalized into governed stores that can be queried on demand.
This improves:
- freshness of retrieved context
- controllability of business logic
- auditability and compliance
- reuse across workflows and teams
- cost efficiency versus oversizing prompts
Hierarchical and Tiered Memory Layers
At scale, memory is usually tiered:
- Hot memory – immediate session context and recent tool outputs
- Warm memory – summaries, recent episodes, and active task state
- Cold memory – historical records, archived artifacts, and long-term facts
This layered approach keeps latency manageable while retaining historical depth.
Retrieval-Augmented Generation (RAG) Techniques
RAG is the most common pattern for grounding an agent with external memory. Strong RAG systems typically combine:
- semantic retrieval over embeddings
- lexical retrieval for exact terms
- metadata filtering for tenant, time, trust, or policy
- reranking for relevance and precision
- source attribution for traceability
In most real-world systems, no single retrieval method is enough on its own. In enterprise settings, hybrid retrieval matters. Many useful searches depend on both meaning and exact terminology, so text search is not a legacy feature to bolt on later. It is an important part of the unified memory core.
Retrieval Evaluation Metrics
To validate retrieval quality rigorously, hybrid memory systems should be measured with explicit ranking and coverage metrics, not only by subjective answer quality.
- Precision@K: how many of the top-K retrieved results are relevant.
- Recall@K: how much of the relevant context is recovered within top-K results.
- MRR (Mean Reciprocal Rank): how early the first relevant result appears in the ranked list.
- Latency (p50/p95): retrieval responsiveness under realistic concurrency and tenant load.
In practice, these metrics should be tracked per retrieval mode (lexical, semantic, hybrid, graph-augmented) and per query class (policy, troubleshooting, identity, compliance) to detect ranking drift early and keep retrieval behavior stable over time.
Memory Management: Summarization, Pruning, and Lifecycle Policies
Memory is not just about storing more. It is also about deciding what to keep, compress, expire, and promote.
Important practices include:
- summarization to condense long histories into reusable state
- pruning to remove redundant or low-value context
- retention policies based on legal, business, and product rules
- promotion rules to move temporary knowledge into durable memory
- staleness checks so outdated facts do not keep reappearing
Example: scheduled summarization and pruning
DBMS_SCHEDULER is Oracle’s enterprise job scheduling framework. It provides a rich feature set for scheduling PL/SQL code, stored procedures, executables, and scripts — either on a time-based calendar expression, in response to external events, or as part of dependency chains. The DBMS_SCHEDULER maps naturally to memory lifecycle automation. Teams can schedule summarization, retention enforcement, and archive workflows directly in the database:
BEGIN
DBMS_SCHEDULER.CREATE_JOB(
job_name => 'SUMMARIZE_AGENT_SESSIONS',
job_type => 'PLSQL_BLOCK',
job_action => 'BEGIN memory_pkg.summarize_old_sessions(30); END;',
repeat_interval => 'FREQ=HOURLY;INTERVAL=6',
enabled => TRUE,
auto_drop => FALSE
);
END;
/
The same scheduling pattern can also keep search infrastructure fresh, for example by running CTX_DDL.SYNC_INDEX and CTX_DDL.OPTIMIZE_INDEX jobs for Oracle Text indexes on a predictable cadence.
Infrastructure Considerations for Scalability
As memory volume grows, architects should consider:
- partitioning by tenant, time, or workload
- indexing strategies for vector, text, and relational access
- concurrency and transaction isolation for multi-agent workflows
- cost of re-embedding and re-ranking pipelines
- observability for recall quality, latency, and drift
Oracle AI Database is compelling here because it supports enterprise-grade scalability while keeping multiple data modalities close together. That reduces the coordination overhead of moving context between independent systems.
Operations Runbook for Memory Systems
To keep unified memory reliable in production, teams should operationalize a lightweight runbook that covers indexing, partitioning, scheduler cadence, and observability.
- Indexing: monitor Oracle Text and vector index health, and schedule regular sync/optimize routines.
- Partitioning: partition event and knowledge tables by tenant and/or time windows to control growth and query cost.
- Scheduler cadence: run summarization, pruning, retention, and index-maintenance jobs on predictable intervals.
- Observability: track retrieval latency (p50/p95), result quality metrics, and drift signals across retrieval modes.
- Operational review: review failed jobs, low-confidence retrieval patterns, and tenant hot spots on a recurring schedule.
A compact runbook helps maintain retrieval quality, governance compliance, and performance consistency as memory volume and workload complexity increase.
Implementation Walkthrough
This implementation builds a unified memory flow in Oracle AI Database, from event storage to multi-mode retrieval and governance.
- Initialize the environment and establish one Oracle connection reused across the workflow.
- Create episodic memory (
agent_events) with realistic JSON events for user messages, tool calls, tool results, checkpoints, and summaries. - Query episodic memory with SQL/JSON (
JSON_VALUE,JSON_TABLE) for filtering, extraction, and analytics. - Apply tenant-aware retrieval patterns so every recall path remains policy-aligned.
- Create and populate the knowledge store (
knowledge_articles) with tenant-scoped support and policy content. - Run lexical retrieval with Oracle Text (
CONTAINS,SCORE) for exact-term precision. - Add semantic retrieval with vectors and rank results by similarity using
VECTOR_DISTANCE. - Combine lexical, semantic, and metadata constraints into hybrid retrieval ranking.
- Execute unified recall by combining latest episodic context with knowledge retrieval candidates.
- Add relationship-aware retrieval with SQL Property Graph and
GRAPH_TABLEover user-ticket-document paths. - Apply lifecycle automation and security patterns using
DBMS_SCHEDULERandDBMS_RLS. - Validate outputs end to end and keep the workflow rerunnable with cleanup.
How This Guide Maps to the Notebook
To make the guide easier to navigate, each concept in this article is implemented in a corresponding notebook section.
Episodic memory is introduced through the agent_events model and sample event ingestion, then expanded with SQL/JSON extraction using JSON_VALUE and JSON_TABLE.
Tenant-aware retrieval and knowledge storage follow, along with lexical retrieval using Oracle Text and semantic retrieval using vectors (VECTOR_DISTANCE).
Hybrid retrieval then combines lexical relevance, semantic distance, and metadata filtering in one ranking path.
The workflow continues with unified episodic-plus-knowledge recall, relationship-aware traversal using GRAPH_TABLE, and operational patterns for lifecycle automation (DBMS_SCHEDULER) and row-level tenant isolation (DBMS_RLS / VPD).
The notebook concludes with an optional LangChain interoperability layer that keeps retrieval Oracle-native.
Security and Privacy Considerations in Agent Memory Storage
Memory makes agents more capable, but it also expands the attack surface.
Common Security Risks and Attack Vectors
- data leakage across users, roles, or tenants
- prompt injection through retrieved content
- memory poisoning from incorrect or malicious inputs
- over-retention of sensitive information
- stale or conflicting memory causing unsafe decisions
- weak authorization around recalled context and tool actions
Data Protection and Access Control Strategies
Best practices include:
- role-based and attribute-based access control
- encryption in transit and at rest
- row-level or tenant-aware data isolation
- retrieval filters tied to identity and policy
- audit logs for memory access and mutation events
- data classification for sensitive memory types
Operational Security Checklist
To translate security principles into day-to-day practice, teams should validate a compact operational checklist for every memory workflow.
- Enforce tenant isolation in every retrieval path, not only at the application layer.
- Log memory reads and writes for auditability, including tool-triggered retrieval actions.
- Apply data classification and PII handling rules before memory is persisted or retrieved.
- Use role-aware authorization checks for both retrieval and mutation operations.
- Define retention and deletion controls so sensitive memory does not persist beyond policy windows.
- Protect retrieved context against prompt-injection and memory-poisoning propagation.
This checklist helps ensure that memory quality, security, and compliance remain aligned as agent usage scales.
Example: tenant-aware memory access with VPD
Virtual Private Database (VPD), also called Fine-Grained Access Control (FGAC), is Oracle’s mechanism for enforcing row-level security transparently at the database kernel level. Unlike application-layer filtering — which can be bypassed by ad-hoc queries, ETL tools, or reporting applications — VPD policies are enforced by the Oracle query engine itself, regardless of how a query reaches the database.. The Row-Level Security can enforce tenant isolation directly in the database with VPD (DBMS_RLS):
BEGIN
DBMS_RLS.ADD_POLICY(
object_schema => 'APP',
object_name => 'AGENT_MEMORY',
policy_name => 'TENANT_ISOLATION',
function_schema => 'APP',
policy_function => 'TENANT_ISOLATION_POLICY',
statement_types => 'SELECT, INSERT, UPDATE, DELETE',
update_check => TRUE
);
END;
/
With SYS_CONTEXT-driven predicates, the same memory tables can serve many tenants while ensuring an agent only recalls context it is authorized to access.
Mitigation Best Practices and Compliance
Organizations should design agent memory with compliance in mind from the start. That means applying retention rules, provenance tracking, redaction strategies, and approval workflows where needed. It also means ensuring the retrieval layer does not bypass the same governance standards applied to transactional systems.
This is another reason a unified, governed database platform is attractive: it allows memory retrieval to inherit mature enterprise security controls instead of recreating them separately for every store.
Recap of Memory Types and Storage Options
- Short-term memory supports immediate task execution and should be fast.
- Long-term memory preserves durable context across sessions and workflows.
- Episodic memory captures what happened, when, and under what conditions.
- Semantic memory helps the agent retrieve meaning, facts, and abstractions.
No single storage mechanism solves every memory problem. In-memory caches, files, relational stores, key-value systems, text indexes, graph structures, and vector search all have a role.
Guidelines for Choosing and Managing Agent Memory
Use the following rules of thumb:
- Match storage to memory behavior, not just data format.
- Keep working memory fast, but make durable memory governed and auditable.
- Combine semantic retrieval with keyword and metadata filtering.
- Treat lifecycle management as part of memory design, not an afterthought.
- Prefer unified platforms when governance, consistency, and scale matter.
Balancing Performance, Scalability, and Security
The best agent memory architectures do not optimize only for retrieval quality. They balance:
- performance for responsive agent interactions
- scalability for growing users, tasks, and data volumes
- security for enterprise trust and compliance
Oracle AI Database fits this balance especially well for enterprise agents. It provides one of the most sophisticated and scalable ways to unify vector, JSON, graph, spatial, relational, and analytic data access in a governed platform. That makes it a strong foundation for a true unified memory core rather than a collection of disconnected memory services.
When memory becomes a first-class architectural concern, agents become more reliable, more context-aware, and more useful in real business workflows.
Validation & Troubleshooting: Failure Modes and Fallback Strategy
Production memory systems should not assume every retrieval mode is always available. A resilient workflow defines deterministic fallback behavior so the agent can continue safely and predictably.
In this architecture, retrieval degrades gracefully: if lexical retrieval is unavailable or returns weak matches, the workflow can fall back to semantic retrieval; if vector retrieval is unavailable, lexical retrieval and tenant-scoped filtering remain active; if graph traversal is unavailable, relationship context can be reconstructed with relational joins; and if all retrieval modes return low-confidence results, the system should return a safe tenant-scoped fallback response and request clarification.
This fallback strategy preserves continuity, improves user trust, and prevents silent retrieval failure in enterprise workflows.
- Validate Oracle Text index creation and lexical ranking output.
- Validate vector dimensions and input format used by
TO_VECTOR/VECTOR_DISTANCE. - If
GRAPH_TABLEparsing fails, avoid reserved labels and use names likeuser_v,ticket_v,document_v. - If results are empty, verify tenant/category filters and fallback query paths.
- Run the notebook end-to-end and confirm outputs across episodic, lexical, vector, hybrid, and graph sections.
Frequently Asked Questions
Why not use vector search alone?
Enterprise queries often contain exact policy/product terms and IDs, so hybrid retrieval is usually more reliable.
What does unified memory mean in practice?
It means episodic, lexical, semantic, and relationship-aware retrieval are handled in one governed database workflow.
What happens if one retrieval mode is unavailable?
The workflow can use fallback paths (lexical, semantic, or relational fallback) to preserve continuity and safe defaults.
How does this relate to the companion notebook?
The notebook implements each pattern as executable steps so readers can validate outputs end-to-end.
