As enterprises adopt AI and machine learning to drive innovation, Kubernetes has become the preferred platform for managing complex, resource-intensive workloads. Its capabilities for automated scaling, load balancing, and high availability make it an ideal choice for tasks like large-scale model training and real-time inference.
GPUs are essential for AI and ML workloads, providing the computational power needed for training large models and handling high-throughput inference. However, managing GPUs within a Kubernetes cluster presents unique challenges.
Challenges in Managing GPU Resources on Kubernetes
Managing GPU resources in Kubernetes is complex, as multiple components need to be properly installed and configured across the cluster, with strict version compatibility maintained. Ensuring consistency among GPU drivers, the Compute Unified Device Architecture (CUDA) toolkit, Nvidia container runtimes, and the GPU device plugin is essential for smooth operation. Handling these components individually increases the risk of misconfigurations, making the process error-prone and operationally challenging.
Kubernetes Worker Nodes (Host Layer)
- GPU Drivers: Installed on the host OS to interface with NVIDIA GPUs.
- Compute Unified Device Architecture (CUDA) Toolkit: Provides libraries and tools for GPU-accelerated operations.
- NVIDIA Container Runtime: Ensures containers can access and utilize GPU resources effectively.
Kubernetes Cluster Components
- GPU Device Plugin: Deployed as a DaemonSet to manage GPU discovery, health monitoring, and scheduling within the Kubernetes cluster
GPUs on OKE
OCI Kubernetes Engine (OKE) simplifies GPU management. When deploying a managed GPU-enabled node pool on OKE, each worker node is automatically configured with the required drivers and essential GPU software toolkits. Additionally, the OKE cluster includes a compatible GPU device plugin, enabling GPU nodes to be immediately ready for scheduling.
For customers seeking greater control over GPU plugins, OKE will soon offer the GPU device plugin as a cluster add-on. This add-on will allow customers to disable the default GPU device plugin on their OKE cluster, giving them flexibility to independently manage GPU components.
For those who prefer direct management of GPU resources, the recommended approach is to use the GPU operator, which allows for advanced customization and management of GPU components. In this blog, we will guide you through the steps to deploy the NVIDIA GPU Operator on an OKE cluster.
NVIDIA GPU Operator
The NVIDIA GPU Operator simplifies GPU resource management by automating the installation, configuration, and updates of these critical components. With the GPU Operator:
- Standard OS images can be used across both CPU and GPU nodes, eliminating the need for specialized images.
- Updates to all GPU-related components are performed simultaneously to ensure compatibility across the entire system.
OKE Supported NVIDIA GPU Operator Configuration Overvie
The NVIDIA GPU Operator is only supported on Ubuntu and Red Hat Enterprise Linux (RHEL) operating systems. OKE supports the use of Ubuntu worker nodes through node packages.
OKE supports worker nodes running Ubuntu 22.04 LTS and 24.04 LTS, with compatibility for Kubernetes versions 1.28.10 and 1.29.1. Below is a summary of the supported configurations for OKE using Ubuntu-based worker nodes for Nvidia GPU Operator.
Kubernetes Versions:
- 1.28.10
- 1.29.1
Operating Systems:
- Ubuntu 22.04 LTS
- Ubuntu 24.04 LTS
- Node Types:
- Self-managed
- GPU Shapes: OKE Supported GPU Shapes
Note: In an OKE cluster with GPU nodes, it is recommended to provision non-GPU nodes as well. These non-GPU nodes are used to host essential system resources, such as those within the kube-system namespace, which are necessary for cluster operations. GPU nodes, once configured with the GPU operator, receive taints that can block system resources from being scheduled on them. Although adding tolerations could allow system resources to run on GPU nodes it is more efficient to reserve these nodes exclusively for GPU-dependent workloads to ensure optimal GPU utilization.
OKE Cluster Topology Overview
Before installing the NVIDIA GPU Operator, ensure that your OKE cluster is configured with Ubuntu worker nodes, including both GPU and non-GPU node pools.
Please refer to the following documentation for comprehensive guidance on setting up OKE with Ubuntu worker nodes.
In this blog, we will guide you through the steps to install the NVIDIA GPU Operator on an OKE cluster, demonstrating the process with a sample configuration
- OKE Node Type: Managed Nodes
- Kubernetes Version: 1.29.1
- Host OS: Ubuntu 22.04 LTS
- GPU Node Pool Shapes: VM.GPU.A10.1
- Non-GPU Node Pool Shapes: VM.Standard.E5.Flex
Installing the Nvidia GPU Operator
Before proceeding, ensure that both kubectl and Helm are installed on your workstation and kubeconfig is configured to access the OKE cluster.
- Create the GPU Operator Namespace
Set up a dedicated namespace to organize the GPU Operator resources.
# kubectl create ns gpu-operator
- Add the NVIDIA Helm Repository
Add the NVIDIA repository to Helm so you can access the necessary GPU Operator Helm chart
# helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update
- Install the NVIDIA GPU Operator via Helm
# helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator
Note: For this installation, we used the default configuration of the NVIDIA GPU Operator, which is suitable for most environments. If you need to customize the setup, refer to the NVIDIA GPU Operator repository on GitHub for detailed instructions.
Verify the Installation
When the NVIDIA GPU Operator is installed, OKE worker nodes with NVIDIA GPUs will have several essential components, along with additional labels and annotations, automatically deployed. These components include:
- k8s-device-plugin: A device plugin for Kubernetes to manage GPU resources.
- container-toolkit: A set of tools required to run containers utilizing GPUs.
- dcgm-exporter: A DCGM (Data Center GPU Manager) exporter used for monitoring and telemetry.
- gpu-feature-discovery: A component that automatically generates labels for the available GPU features on each node.
- mig-manager: A component that enables dynamic repartitioning of GPUs into various MIG (Multi-Instance GPU) configurations.
- Verify the Installation
Confirm that the GPU Operator is installed correctly by checking the deployment status of pods in the gpu-operator namespace.
# kubectl get pods -n gpu-operator
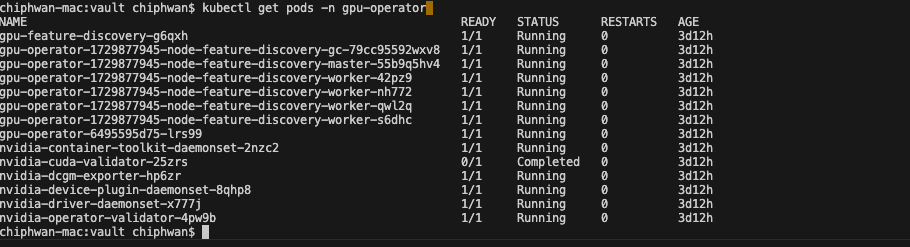
Figure 1. gpu-operator pods
- Verify components on GPU Operator components on each GPU node.
# kubectl describe node <name of GPU node>

Figure 2. GPU Operator Components on Node

Figure 3. GPU taints
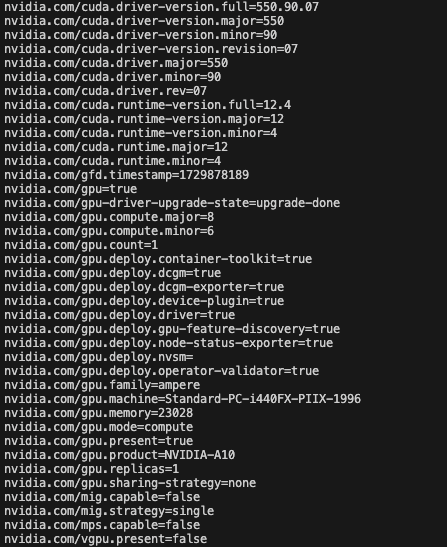
Figure 4. GPU node labels.
Using GPUs on OKE
To assign a GPU to Kubernetes resources, specify the resource limits in the YAML configuration, indicating the number of GPUs required. Here’s an example:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: gpu-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04
# Example image with CUDA
command: ["nvidia-smi"] # Command to check GPU availability
resources:
limits:
nvidia.com/gpu: 1 # Request 1 GPU
tolerations:
- key: "nvidia.com/gpu"
operator: "Equal"
value: "present"
effect: "NoSchedule"
- Save the file as gpu_pod.yaml and create the pod using the following command:
#kubectl create -f gpu_pod.yaml
This pod executes the nvidia-smi command, which will only run successfully if the OKE cluster is properly configured to support GPUs. The output should show the GPU assigned to the pod.
- Get the logs from the pod.
#kubectl logs gpu-pod
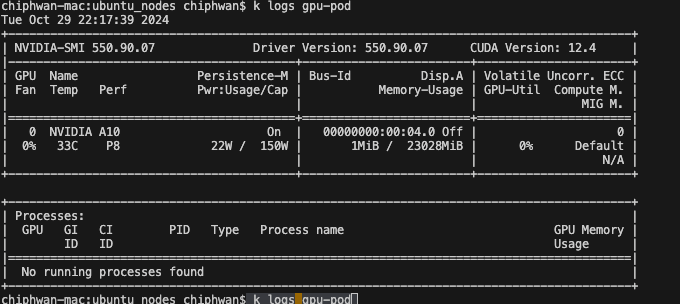
Figure 5. Nvidia-Smi Output
Summary
Managing GPUs in Kubernetes often involves complex tasks such as configuring device plugins, CUDA libraries, and container runtimes manually.
With OKE, deploying GPU-enabled node pools is simplified as each worker node is automatically provisioned with the necessary drivers and GPU software toolkits. Moreover, the OKE cluster includes a pre-configured GPU device plugin, ensuring that GPU nodes are ready for scheduling immediately.
For customers who prefer more granular control over GPU resources, the GPU operator is the recommended solution. It provides advanced options for customizing and managing GPU components effectively.
